 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating uncertainty quantification into randomized smoothing based robustness guarantees
Oct 27, 2024



Deep neural networks have proven to be extremely powerful, however, they are also vulnerable to adversarial attacks which can cause hazardous incorrect predictions in safety-critical applications. Certified robustness via randomized smoothing gives a probabilistic guarantee that the smoothed classifier's predictions will not change within an $\ell_2$-ball around a given input. On the other hand (uncertainty) score-based rejection is a technique often applied in practice to defend models against adversarial attacks. In this work, we fuse these two approaches by integrating a classifier that abstains from predicting when uncertainty is high into the certified robustness framework. This allows us to derive two novel robustness guarantees for uncertainty aware classifiers, namely (i) the radius of an $\ell_2$-ball around the input in which the same label is predicted and uncertainty remains low and (ii) the $\ell_2$-radius of a ball in which the predictions will either not change or be uncertain. While the former provides robustness guarantees with respect to attacks aiming at increased uncertainty, the latter informs about the amount of input perturbation necessary to lead the uncertainty aware model into a wrong prediction. Notably, this is on CIFAR10 up to 20.93% larger than for models not allowing for uncertainty based rejection. We demonstrate, that the novel framework allows for a systematic robustness evaluation of different network architectures and uncertainty measures and to identify desired properties of uncertainty quantification techniques. Moreover, we show that leveraging uncertainty in a smoothed classifier helps out-of-distribution detection.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
On the Limitations of Model Stealing with Uncertainty Quantification Models
May 09, 2023


Model stealing aims at inferring a victim model's functionality at a fraction of the original training cost. While the goal is clear, in practice the model's architecture, weight dimension, and original training data can not be determined exactly, leading to mutual uncertainty during stealing. In this work, we explicitly tackle this uncertainty by generating multiple possible networks and combining their predictions to improve the quality of the stolen model. For this, we compare five popular uncertainty quantification models in a model stealing task. Surprisingly, our results indicate that the considered models only lead to marginal improvements in terms of label agreement (i.e., fidelity) to the stolen model. To find the cause of this, we inspect the diversity of the model's prediction by looking at the prediction variance as a function of training iterations. We realize that during training, the models tend to have similar predictions, indicating that the network diversity we wanted to leverage using uncertainty quantification models is not (high) enough for improvements on the model stealing task.
How Sampling Impacts the Robustness of Stochastic Neural Networks
Apr 22, 2022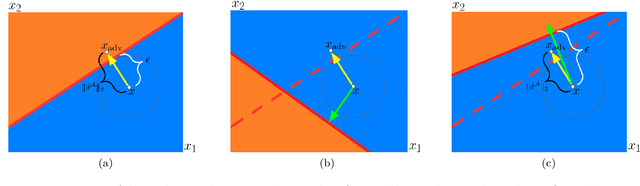

Stochastic neural networks (SNNs) are random functions and predictions are gained by averaging over multiple realizations of this random function. Consequently, an adversarial attack is calculated based on one set of samples and applied to the prediction defined by another set of samples. In this paper we analyze robustness in this setting by deriving a sufficient condition for the given prediction process to be robust against the calculated attack. This allows us to identify the factors that lead to an increased robustness of SNNs and helps to explain the impact of the variance and the amount of samples. Among other things, our theoretical analysis gives insights into (i) why increasing the amount of samples drawn for the estimation of adversarial examples increases the attack's strength, (ii) why decreasing sample size during inference hardly influences the robustness, and (iii) why a higher prediction variance between realizations relates to a higher robustness. We verify the validity of our theoretical findings by an extensive empirical analysis.
Investigating maximum likelihood based training of infinite mixtures for uncertainty quantification
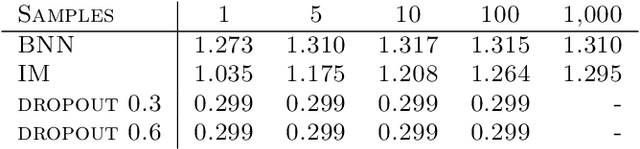
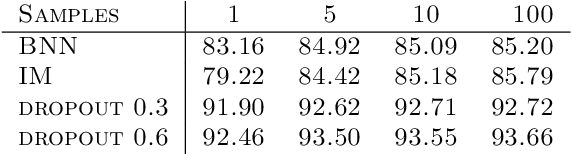
Aug 17, 2020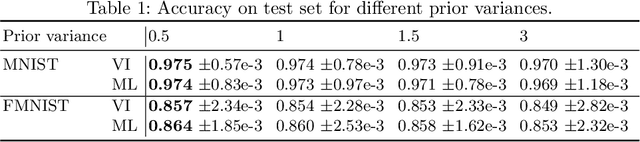
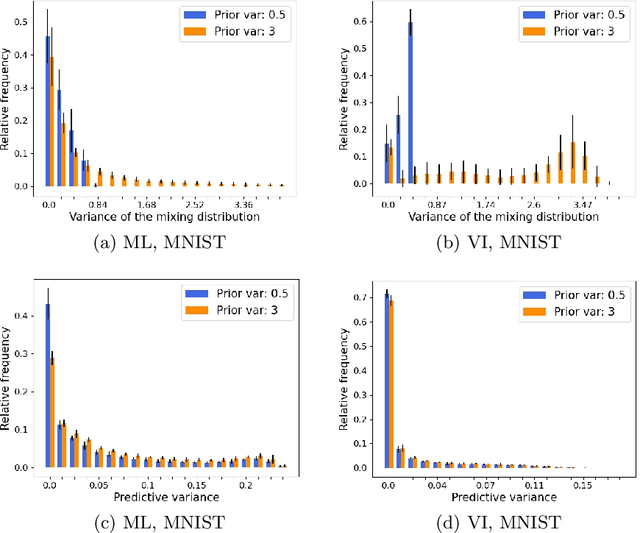

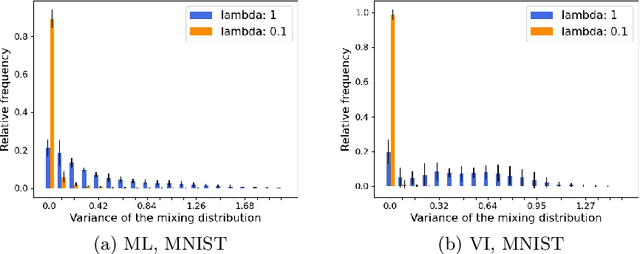
Uncertainty quantification in neural networks gained a lot of attention in the past years. The most popular approaches, Bayesian neural networks (BNNs), Monte Carlo dropout, and deep ensembles have one thing in common: they are all based on some kind of mixture model. While the BNNs build infinite mixture models and are derived via variational inference, the latter two build finite mixtures trained with the maximum likelihood method. In this work we investigate the effect of training an infinite mixture distribution with the maximum likelihood method instead of variational inference. We find that the proposed objective leads to stochastic networks with an increased predictive variance, which improves uncertainty based identification of miss-classification and robustness against adversarial attacks in comparison to a standard BNN with equivalent network structure. The new model also displays higher entropy on out-of-distribution data.
Detecting Adversarial Examples for Speech Recognition via Uncertainty Quantification
May 24, 2020
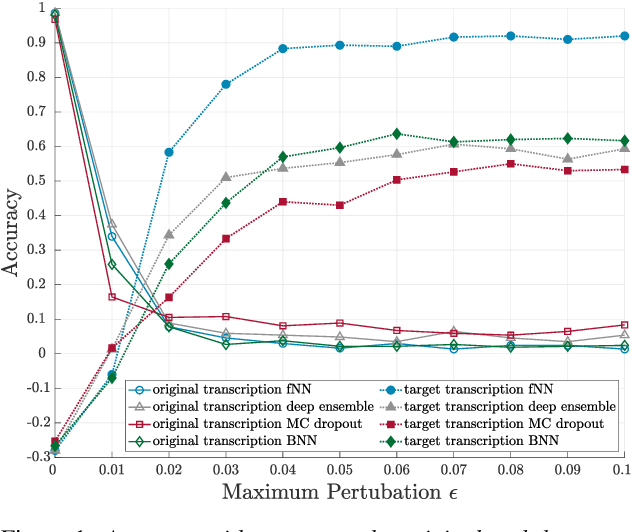
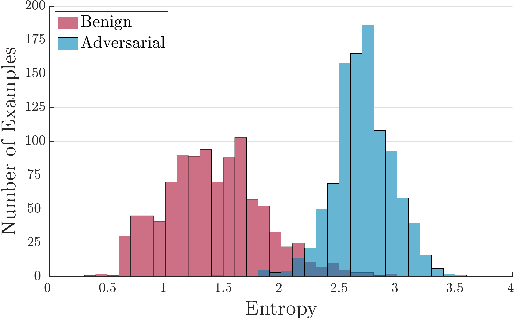
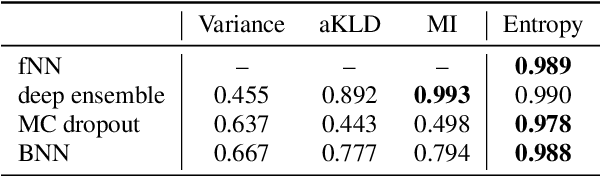
Machine learning systems and also, specifically, automatic speech recognition (ASR) systems are vulnerable against adversarial attacks, where an attacker maliciously changes the input. In the case of ASR systems, the most interesting cases are targeted attacks, in which an attacker aims to force the system into recognizing given target transcriptions in an arbitrary audio sample. The increasing number of sophisticated, quasi imperceptible attacks raises the question of countermeasures. In this paper, we focus on hybrid ASR systems and compare four acoustic models regarding their ability to indicate uncertainty under attack: a feed-forward neural network and three neural networks specifically designed for uncertainty quantification, namely a Bayesian neural network, Monte Carlo dropout, and a deep ensemble. We employ uncertainty measures of the acoustic model to construct a simple one-class classification model for assessing whether inputs are benign or adversarial. Based on this approach, we are able to detect adversarial examples with an area under the receiving operator curve score of more than 0.99. The neural networks for uncertainty quantification simultaneously diminish the vulnerability to the attack, which is reflected in a lower recognition accuracy of the malicious target text in comparison to a standard hybrid ASR system.