 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025



Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Magnetoencephalography (MEG) Based Non-Invasive Chinese Speech Decoding
Jun 15, 2025As an emerging paradigm of brain-computer interfaces (BCIs), speech BCI has the potential to directly reflect auditory perception and thoughts, offering a promising communication alternative for patients with aphasia. Chinese is one of the most widely spoken languages in the world, whereas there is very limited research on speech BCIs for Chinese language. This paper reports a text-magnetoencephalography (MEG) dataset for non-invasive Chinese speech BCIs. It also proposes a multi-modality assisted speech decoding (MASD) algorithm to capture both text and acoustic information embedded in brain signals during speech activities. Experiment results demonstrated the effectiveness of both our text-MEG dataset and our proposed MASD algorithm. To our knowledge, this is the first study on modality-assisted decoding for non-invasive speech BCIs.
SACM: SEEG-Audio Contrastive Matching for Chinese Speech Decoding
May 26, 2025Speech disorders such as dysarthria and anarthria can severely impair the patient's ability to communicate verbally. Speech decoding brain-computer interfaces (BCIs) offer a potential alternative by directly translating speech intentions into spoken words, serving as speech neuroprostheses. This paper reports an experimental protocol for Mandarin Chinese speech decoding BCIs, along with the corresponding decoding algorithms. Stereo-electroencephalography (SEEG) and synchronized audio data were collected from eight drug-resistant epilepsy patients as they conducted a word-level reading task. The proposed SEEG and Audio Contrastive Matching (SACM), a contrastive learning-based framework, achieved decoding accuracies significantly exceeding chance levels in both speech detection and speech decoding tasks. Electrode-wise analysis revealed that a single sensorimotor cortex electrode achieved performance comparable to that of the full electrode array. These findings provide valuable insights for developing more accurate online speech decoding BCIs.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Empowering Few-Shot Relation Extraction with The Integration of Traditional RE Methods and Large Language Models
Jul 12, 2024Few-Shot Relation Extraction (FSRE), a subtask of Relation Extraction (RE) that utilizes limited training instances, appeals to more researchers in Natural Language Processing (NLP) due to its capability to extract textual information in extremely low-resource scenarios. The primary methodologies employed for FSRE have been fine-tuning or prompt tuning techniques based on Pre-trained Language Models (PLMs). Recently, the emergence of Large Language Models (LLMs) has prompted numerous researchers to explore FSRE through In-Context Learning (ICL). However, there are substantial limitations associated with methods based on either traditional RE models or LLMs. Traditional RE models are hampered by a lack of necessary prior knowledge, while LLMs fall short in their task-specific capabilities for RE. To address these shortcomings, we propose a Dual-System Augmented Relation Extractor (DSARE), which synergistically combines traditional RE models with LLMs. Specifically, DSARE innovatively injects the prior knowledge of LLMs into traditional RE models, and conversely enhances LLMs' task-specific aptitude for RE through relation extraction augmentation. Moreover, an Integrated Prediction module is employed to jointly consider these two respective predictions and derive the final results. Extensive experiments demonstrate the efficacy of our proposed method.
CVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023



Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
MAE-GEBD:Winning the CVPR'2023 LOVEU-GEBD Challenge
Jun 27, 2023



The Generic Event Boundary Detection (GEBD) task aims to build a model for segmenting videos into segments by detecting general event boundaries applicable to various classes. In this paper, based on last year's MAE-GEBD method, we have improved our model performance on the GEBD task by adjusting the data processing strategy and loss function. Based on last year's approach, we extended the application of pseudo-label to a larger dataset and made many experimental attempts. In addition, we applied focal loss to concentrate more on difficult samples and improved our model performance. Finally, we improved the segmentation alignment strategy used last year, and dynamically adjusted the segmentation alignment method according to the boundary density and duration of the video, so that our model can be more flexible and fully applicable in different situations. With our method, we achieve an F1 score of 86.03% on the Kinetics-GEBD test set, which is a 0.09% improvement in the F1 score compared to our 2022 Kinetics-GEBD method.
Masked Autoencoders for Generic Event Boundary Detection CVPR'2022 Kinetics-GEBD Challenge
Jun 17, 2022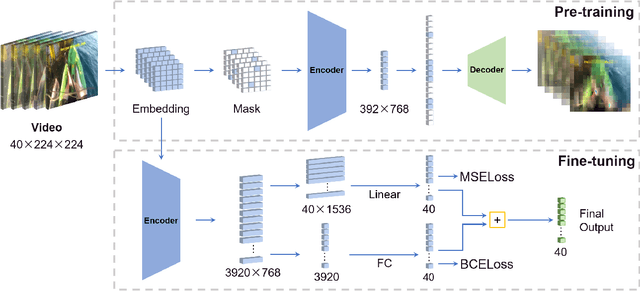
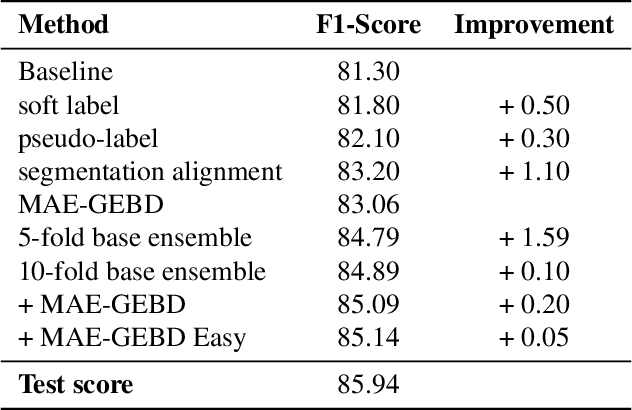
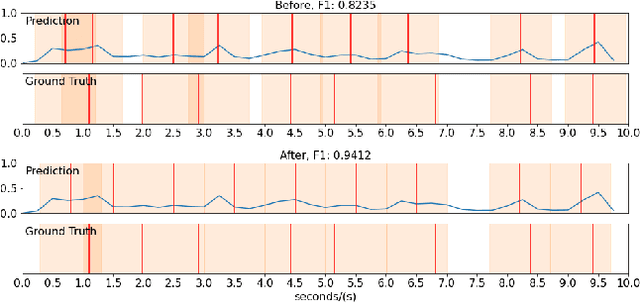
Generic Event Boundary Detection (GEBD) tasks aim at detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. In this paper, we apply Masked Autoencoders to improve algorithm performance on the GEBD tasks. Our approach mainly adopted the ensemble of Masked Autoencoders fine-tuned on the GEBD task as a self-supervised learner with other base models. Moreover, we also use a semi-supervised pseudo-label method to take full advantage of the abundant unlabeled Kinetics-400 data while training. In addition, we propose a soft-label method to partially balance the positive and negative samples and alleviate the problem of ambiguous labeling in this task. Lastly, a tricky segmentation alignment policy is implemented to refine boundaries predicted by our models to more accurate locations. With our approach, we achieved 85.94% on the F1-score on the Kinetics-GEBD test set, which improved the F1-score by 2.31% compared to the winner of the 2021 Kinetics-GEBD Challenge. Our code is available at https://github.com/ContentAndMaterialPortrait/MAE-GEBD.
Robust Seatbelt Detection and Usage Recognition for Driver Monitoring Systems
Mar 02, 2022
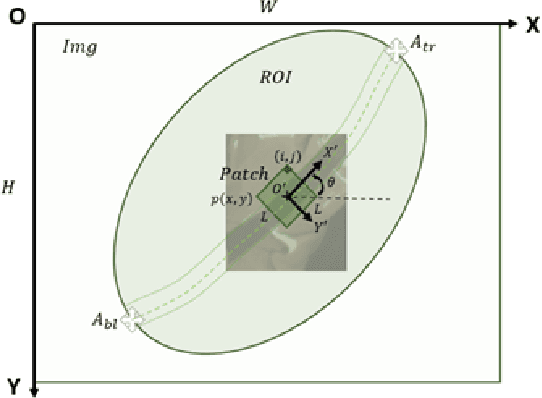
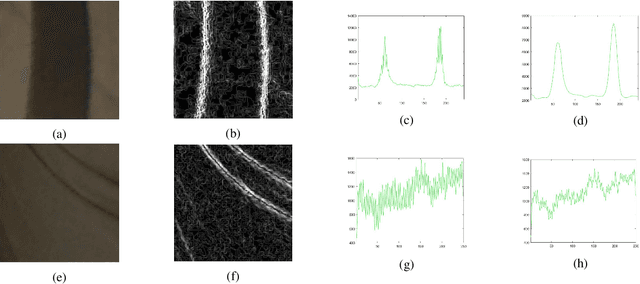
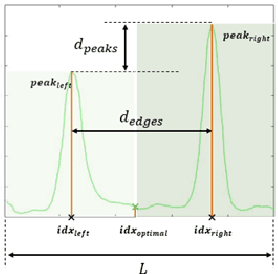
Wearing a seatbelt appropriately while driving can reduce serious crash-related injuries or deaths by about half. However, current seatbelt reminder system has multiple shortcomings, such as can be easily fooled by a "Seatbelt Warning Stopper", and cannot recognize incorrect usages for example seating in front of a buckled seatbelt or wearing a seatbelt under the arm. General seatbelt usage recognition has many challenges, to name a few, lacking of color information in Infrared (IR) cameras, strong distortion caused by wide Field of View (FoV) fisheye lens, low contrast between belt and its background, occlusions caused by hands or hair, and imaging blurry. In this paper, we introduce a novel general seatbelt detection and usage recognition framework to resolve the above challenges. Our method consists of three components: a local predictor, a global assembler, and a shape modeling process. Our approach can be applied to the driver in the Driver Monitoring System (DMS) or general passengers in the Occupant Monitoring System (OMS) for various camera modalities. Experiment results on both DMS and OMS are provided to demonstrate the accuracy and robustness of the proposed approach.