 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
Improving Synthetic Data Training for Contextual Biasing Models with a Keyword-Aware Cost Function
Sep 11, 2025



Rare word recognition can be improved by adapting ASR models to synthetic data that includes these words. Further improvements can be achieved through contextual biasing, which trains and adds a biasing module into the model architecture to prioritize rare words. While training the module on synthetic rare word data is more effective than using non-rare-word data, it can lead to overfitting due to artifacts in the synthetic audio. To address this, we enhance the TCPGen-based contextual biasing approach and propose a keyword-aware loss function that additionally focuses on biased words when training biasing modules. This loss includes a masked cross-entropy term for biased word prediction and a binary classification term for detecting biased word positions. These two terms complementarily support the decoding of biased words during inference. By adapting Whisper to 10 hours of synthetic data, our method reduced the word error rate on the NSC Part 2 test set from 29.71% to 11.81%.
Zero-shot Context Biasing with Trie-based Decoding using Synthetic Multi-Pronunciation
Aug 25, 2025Contextual automatic speech recognition (ASR) systems allow for recognizing out-of-vocabulary (OOV) words, such as named entities or rare words. However, it remains challenging due to limited training data and ambiguous or inconsistent pronunciations. In this paper, we propose a synthesis-driven multi-pronunciation contextual biasing method that performs zero-shot contextual ASR on a pretrained Whisper model. Specifically, we leverage text-to-speech (TTS) systems to synthesize diverse speech samples containing each target rare word, and then use the pretrained Whisper model to extract multiple predicted pronunciation variants. These variant token sequences are compiled into a prefix-trie, which assigns rewards to beam hypotheses in a shallow-fusion manner during beam-search decoding. After which, any recognized variant is mapped back to the original rare word in the final transcription. The evaluation results on the Librispeech dataset show that our method reduces biased word error rate (WER) by 42% on test-clean and 43% on test-other while maintaining unbiased WER essentially unchanged.
Bi-directional Context-Enhanced Speech Large Language Models for Multilingual Conversational ASR
Jun 16, 2025This paper introduces the integration of language-specific bi-directional context into a speech large language model (SLLM) to improve multilingual continuous conversational automatic speech recognition (ASR). We propose a character-level contextual masking strategy during training, which randomly removes portions of the context to enhance robustness and better emulate the flawed transcriptions that may occur during inference. For decoding, a two-stage pipeline is utilized: initial isolated segment decoding followed by context-aware re-decoding using neighboring hypotheses. Evaluated on the 1500-hour Multilingual Conversational Speech and Language Model (MLC-SLM) corpus covering eleven languages, our method achieves an 18% relative improvement compared to a strong baseline, outperforming even the model trained on 6000 hours of data for the MLC-SLM competition. These results underscore the significant benefit of incorporating contextual information in multilingual continuous conversational ASR.
NTU Speechlab LLM-Based Multilingual ASR System for Interspeech MLC-SLM Challenge 2025
Jun 16, 2025This report details the NTU Speechlab system developed for the Interspeech 2025 Multilingual Conversational Speech and Language Model (MLC-SLM) Challenge (Task I), where we achieved 5th place. We present comprehensive analyses of our multilingual automatic speech recognition system, highlighting key advancements in model architecture, data selection, and training strategies. In particular, language-specific prompts and model averaging techniques were instrumental in boosting system performance across diverse languages. Compared to the initial baseline system, our final model reduced the average Mix Error Rate from 20.2% to 10.6%, representing an absolute improvement of 9.6% (a relative improvement of 48%) on the evaluation set. Our results demonstrate the effectiveness of our approach and offer practical insights for future Speech Large Language Models.
A correlation-permutation approach for speech-music encoders model merging
Jun 13, 2025Creating a unified speech and music model requires expensive pre-training. Model merging can instead create an unified audio model with minimal computational expense. However, direct merging is challenging when the models are not aligned in the weight space. Motivated by Git Re-Basin, we introduce a correlation-permutation approach that aligns a music encoder's internal layers with a speech encoder. We extend previous work to the case of merging transformer layers. The method computes a permutation matrix that maximizes the model's features-wise cross-correlations layer by layer, enabling effective fusion of these otherwise disjoint models. The merged model retains speech capabilities through this method while significantly enhancing music performance, achieving an improvement of 14.83 points in average score compared to linear interpolation model merging. This work allows the creation of unified audio models from independently trained encoders.
Speechless: Speech Instruction Training Without Speech for Low Resource Languages
May 23, 2025The rapid growth of voice assistants powered by large language models (LLM) has highlighted a need for speech instruction data to train these systems. Despite the abundance of speech recognition data, there is a notable scarcity of speech instruction data, which is essential for fine-tuning models to understand and execute spoken commands. Generating high-quality synthetic speech requires a good text-to-speech (TTS) model, which may not be available to low resource languages. Our novel approach addresses this challenge by halting synthesis at the semantic representation level, bypassing the need for TTS. We achieve this by aligning synthetic semantic representations with the pre-trained Whisper encoder, enabling an LLM to be fine-tuned on text instructions while maintaining the ability to understand spoken instructions during inference. This simplified training process is a promising approach to building voice assistant for low-resource languages.
EASY: Emotion-aware Speaker Anonymization via Factorized Distillation
May 21, 2025Emotion plays a significant role in speech interaction, conveyed through tone, pitch, and rhythm, enabling the expression of feelings and intentions beyond words to create a more personalized experience. However, most existing speaker anonymization systems employ parallel disentanglement methods, which only separate speech into linguistic content and speaker identity, often neglecting the preservation of the original emotional state. In this study, we introduce EASY, an emotion-aware speaker anonymization framework. EASY employs a novel sequential disentanglement process to disentangle speaker identity, linguistic content, and emotional representation, modeling each speech attribute in distinct subspaces through a factorized distillation approach. By independently constraining speaker identity and emotional representation, EASY minimizes information leakage, enhancing privacy protection while preserving original linguistic content and emotional state. Experimental results on the VoicePrivacy Challenge official datasets demonstrate that our proposed approach outperforms all baseline systems, effectively protecting speaker privacy while maintaining linguistic content and emotional state.
Distilling a speech and music encoder with task arithmetic
May 19, 2025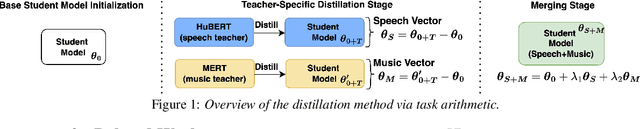
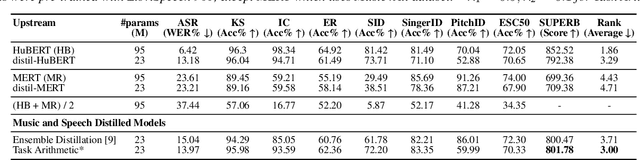
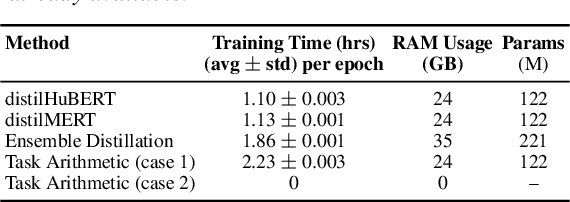
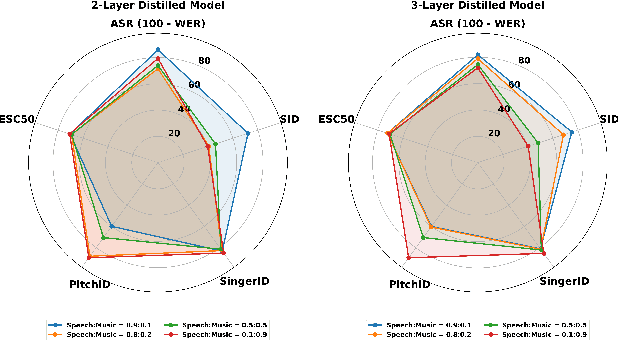
Despite the progress in self-supervised learning (SSL) for speech and music, existing models treat these domains separately, limiting their capacity for unified audio understanding. A unified model is desirable for applications that require general representations, e.g. audio large language models. Nonetheless, directly training a general model for speech and music is computationally expensive. Knowledge Distillation of teacher ensembles may be a natural solution, but we posit that decoupling the distillation of the speech and music SSL models allows for more flexibility. Thus, we propose to learn distilled task vectors and then linearly interpolate them to form a unified speech+music model. This strategy enables flexible domain emphasis through adjustable weights and is also simpler to train. Experiments on speech and music benchmarks demonstrate that our method yields superior overall performance compared to ensemble distillation.