 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Distillation from Speech and Music Representation Models
Jun 08, 2025



Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
Distilling a speech and music encoder with task arithmetic
May 19, 2025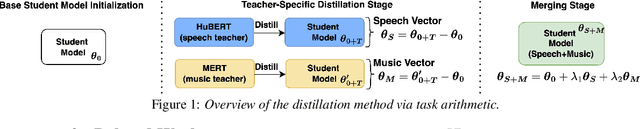
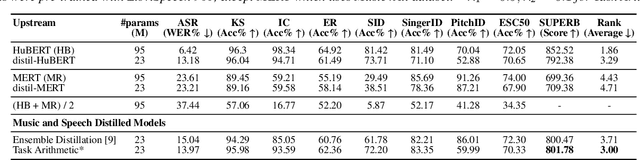
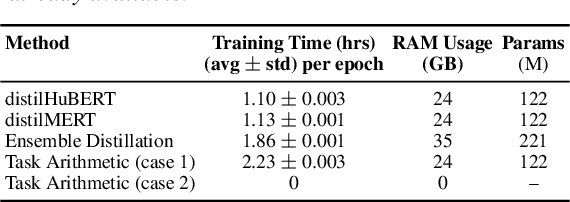
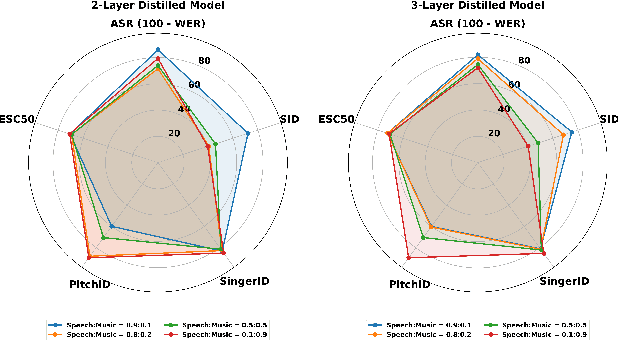
Despite the progress in self-supervised learning (SSL) for speech and music, existing models treat these domains separately, limiting their capacity for unified audio understanding. A unified model is desirable for applications that require general representations, e.g. audio large language models. Nonetheless, directly training a general model for speech and music is computationally expensive. Knowledge Distillation of teacher ensembles may be a natural solution, but we posit that decoupling the distillation of the speech and music SSL models allows for more flexibility. Thus, we propose to learn distilled task vectors and then linearly interpolate them to form a unified speech+music model. This strategy enables flexible domain emphasis through adjustable weights and is also simpler to train. Experiments on speech and music benchmarks demonstrate that our method yields superior overall performance compared to ensemble distillation.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.