 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Free Reasoning for Policy Generalization
Feb 06, 2025



End-to-end imitation learning offers a promising approach for training robot policies. However, generalizing to new settings remains a significant challenge. Although large-scale robot demonstration datasets have shown potential for inducing generalization, they are resource-intensive to scale. In contrast, human video data is abundant and diverse, presenting an attractive alternative. Yet, these human-video datasets lack action labels, complicating their use in imitation learning. Existing methods attempt to extract grounded action representations (e.g., hand poses), but resulting policies struggle to bridge the embodiment gap between human and robot actions. We propose an alternative approach: leveraging language-based reasoning from human videos-essential for guiding robot actions-to train generalizable robot policies. Building on recent advances in reasoning-based policy architectures, we introduce Reasoning through Action-free Data (RAD). RAD learns from both robot demonstration data (with reasoning and action labels) and action-free human video data (with only reasoning labels). The robot data teaches the model to map reasoning to low-level actions, while the action-free data enhances reasoning capabilities. Additionally, we will release a new dataset of 3,377 human-hand demonstrations with reasoning annotations compatible with the Bridge V2 benchmark and aimed at facilitating future research on reasoning-driven robot learning. Our experiments show that RAD enables effective transfer across the embodiment gap, allowing robots to perform tasks seen only in action-free data. Furthermore, scaling up action-free reasoning data significantly improves policy performance and generalization to novel tasks. These results highlight the promise of reasoning-driven learning from action-free datasets for advancing generalizable robot control. Project page: https://rad-generalization.github.io
Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning
Jan 13, 2025



Teaching robots to autonomously complete everyday tasks remains a challenge. Imitation Learning (IL) is a powerful approach that imbues robots with skills via demonstrations, but is limited by the labor-intensive process of collecting teleoperated robot data. Human videos offer a scalable alternative, but it remains difficult to directly train IL policies from them due to the lack of robot action labels. To address this, we propose to represent actions as short-horizon 2D trajectories on an image. These actions, or motion tracks, capture the predicted direction of motion for either human hands or robot end-effectors. We instantiate an IL policy called Motion Track Policy (MT-pi) which receives image observations and outputs motion tracks as actions. By leveraging this unified, cross-embodiment action space, MT-pi completes tasks with high success given just minutes of human video and limited additional robot demonstrations. At test time, we predict motion tracks from two camera views, recovering 6DoF trajectories via multi-view synthesis. MT-pi achieves an average success rate of 86.5% across 4 real-world tasks, outperforming state-of-the-art IL baselines which do not leverage human data or our action space by 40%, and generalizes to scenarios seen only in human videos. Code and videos are available on our website https://portal-cornell.github.io/motion_track_policy/.
What's the Move? Hybrid Imitation Learning via Salient Points
Dec 06, 2024



While imitation learning (IL) offers a promising framework for teaching robots various behaviors, learning complex tasks remains challenging. Existing IL policies struggle to generalize effectively across visual and spatial variations even for simple tasks. In this work, we introduce SPHINX: Salient Point-based Hybrid ImitatioN and eXecution, a flexible IL policy that leverages multimodal observations (point clouds and wrist images), along with a hybrid action space of low-frequency, sparse waypoints and high-frequency, dense end effector movements. Given 3D point cloud observations, SPHINX learns to infer task-relevant points within a point cloud, or salient points, which support spatial generalization by focusing on semantically meaningful features. These salient points serve as anchor points to predict waypoints for long-range movement, such as reaching target poses in free-space. Once near a salient point, SPHINX learns to switch to predicting dense end-effector movements given close-up wrist images for precise phases of a task. By exploiting the strengths of different input modalities and action representations for different manipulation phases, SPHINX tackles complex tasks in a sample-efficient, generalizable manner. Our method achieves 86.7% success across 4 real-world and 2 simulated tasks, outperforming the next best state-of-the-art IL baseline by 41.1% on average across 440 real world trials. SPHINX additionally generalizes to novel viewpoints, visual distractors, spatial arrangements, and execution speeds with a 1.7x speedup over the most competitive baseline. Our website (http://sphinx-manip.github.io) provides open-sourced code for data collection, training, and evaluation, along with supplementary videos.
Vision Language Models are In-Context Value Learners
Nov 07, 2024



Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
RT-Affordance: Affordances are Versatile Intermediate Representations for Robot Manipulation
Nov 05, 2024We explore how intermediate policy representations can facilitate generalization by providing guidance on how to perform manipulation tasks. Existing representations such as language, goal images, and trajectory sketches have been shown to be helpful, but these representations either do not provide enough context or provide over-specified context that yields less robust policies. We propose conditioning policies on affordances, which capture the pose of the robot at key stages of the task. Affordances offer expressive yet lightweight abstractions, are easy for users to specify, and facilitate efficient learning by transferring knowledge from large internet datasets. Our method, RT-Affordance, is a hierarchical model that first proposes an affordance plan given the task language, and then conditions the policy on this affordance plan to perform manipulation. Our model can flexibly bridge heterogeneous sources of supervision including large web datasets and robot trajectories. We additionally train our model on cheap-to-collect in-domain affordance images, allowing us to learn new tasks without collecting any additional costly robot trajectories. We show on a diverse set of novel tasks how RT-Affordance exceeds the performance of existing methods by over 50%, and we empirically demonstrate that affordances are robust to novel settings. Videos available at https://snasiriany.me/rt-affordance
Vocal Sandbox: Continual Learning and Adaptation for Situated Human-Robot Collaboration
Nov 04, 2024



We introduce Vocal Sandbox, a framework for enabling seamless human-robot collaboration in situated environments. Systems in our framework are characterized by their ability to adapt and continually learn at multiple levels of abstraction from diverse teaching modalities such as spoken dialogue, object keypoints, and kinesthetic demonstrations. To enable such adaptation, we design lightweight and interpretable learning algorithms that allow users to build an understanding and co-adapt to a robot's capabilities in real-time, as they teach new behaviors. For example, after demonstrating a new low-level skill for "tracking around" an object, users are provided with trajectory visualizations of the robot's intended motion when asked to track a new object. Similarly, users teach high-level planning behaviors through spoken dialogue, using pretrained language models to synthesize behaviors such as "packing an object away" as compositions of low-level skills $-$ concepts that can be reused and built upon. We evaluate Vocal Sandbox in two settings: collaborative gift bag assembly and LEGO stop-motion animation. In the first setting, we run systematic ablations and user studies with 8 non-expert participants, highlighting the impact of multi-level teaching. Across 23 hours of total robot interaction time, users teach 17 new high-level behaviors with an average of 16 novel low-level skills, requiring 22.1% less active supervision compared to baselines and yielding more complex autonomous performance (+19.7%) with fewer failures (-67.1%). Qualitatively, users strongly prefer Vocal Sandbox systems due to their ease of use (+20.6%) and overall performance (+13.9%). Finally, we pair an experienced system-user with a robot to film a stop-motion animation; over two hours of continuous collaboration, the user teaches progressively more complex motion skills to shoot a 52 second (232 frame) movie.
So You Think You Can Scale Up Autonomous Robot Data Collection?
Nov 04, 2024A long-standing goal in robot learning is to develop methods for robots to acquire new skills autonomously. While reinforcement learning (RL) comes with the promise of enabling autonomous data collection, it remains challenging to scale in the real-world partly due to the significant effort required for environment design and instrumentation, including the need for designing reset functions or accurate success detectors. On the other hand, imitation learning (IL) methods require little to no environment design effort, but instead require significant human supervision in the form of collected demonstrations. To address these shortcomings, recent works in autonomous IL start with an initial seed dataset of human demonstrations that an autonomous policy can bootstrap from. While autonomous IL approaches come with the promise of addressing the challenges of autonomous RL as well as pure IL strategies, in this work, we posit that such techniques do not deliver on this promise and are still unable to scale up autonomous data collection in the real world. Through a series of real-world experiments, we demonstrate that these approaches, when scaled up to realistic settings, face much of the same scaling challenges as prior attempts in RL in terms of environment design. Further, we perform a rigorous study of autonomous IL methods across different data scales and 7 simulation and real-world tasks, and demonstrate that while autonomous data collection can modestly improve performance, simply collecting more human data often provides significantly more improvement. Our work suggests a negative result: that scaling up autonomous data collection for learning robot policies for real-world tasks is more challenging and impractical than what is suggested in prior work. We hope these insights about the core challenges of scaling up data collection help inform future efforts in autonomous learning.
RoboCrowd: Scaling Robot Data Collection through Crowdsourcing
Nov 04, 2024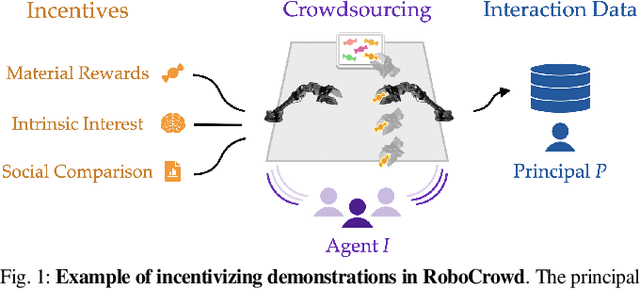
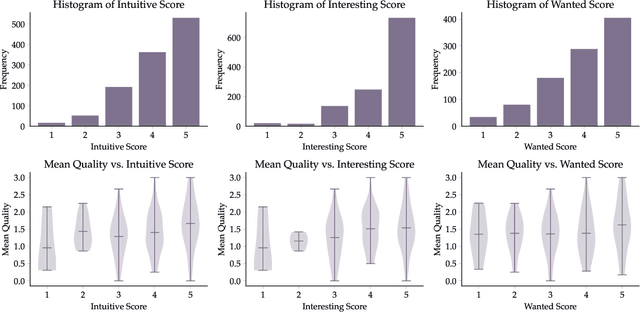
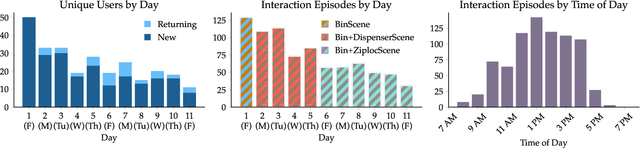
In recent years, imitation learning from large-scale human demonstrations has emerged as a promising paradigm for training robot policies. However, the burden of collecting large quantities of human demonstrations is significant in terms of collection time and the need for access to expert operators. We introduce a new data collection paradigm, RoboCrowd, which distributes the workload by utilizing crowdsourcing principles and incentive design. RoboCrowd helps enable scalable data collection and facilitates more efficient learning of robot policies. We build RoboCrowd on top of ALOHA (Zhao et al. 2023) -- a bimanual platform that supports data collection via puppeteering -- to explore the design space for crowdsourcing in-person demonstrations in a public environment. We propose three classes of incentive mechanisms to appeal to users' varying sources of motivation for interacting with the system: material rewards, intrinsic interest, and social comparison. We instantiate these incentives through tasks that include physical rewards, engaging or challenging manipulations, as well as gamification elements such as a leaderboard. We conduct a large-scale, two-week field experiment in which the platform is situated in a university cafe. We observe significant engagement with the system -- over 200 individuals independently volunteered to provide a total of over 800 interaction episodes. Our findings validate the proposed incentives as mechanisms for shaping users' data quantity and quality. Further, we demonstrate that the crowdsourced data can serve as useful pre-training data for policies fine-tuned on expert demonstrations -- boosting performance up to 20% compared to when this data is not available. These results suggest the potential for RoboCrowd to reduce the burden of robot data collection by carefully implementing crowdsourcing and incentive design principles.
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Sep 24, 2024



How can robot manipulation policies generalize to novel tasks involving unseen object types and new motions? In this paper, we provide a solution in terms of predicting motion information from web data through human video generation and conditioning a robot policy on the generated video. Instead of attempting to scale robot data collection which is expensive, we show how we can leverage video generation models trained on easily available web data, for enabling generalization. Our approach Gen2Act casts language-conditioned manipulation as zero-shot human video generation followed by execution with a single policy conditioned on the generated video. To train the policy, we use an order of magnitude less robot interaction data compared to what the video prediction model was trained on. Gen2Act doesn't require fine-tuning the video model at all and we directly use a pre-trained model for generating human videos. Our results on diverse real-world scenarios show how Gen2Act enables manipulating unseen object types and performing novel motions for tasks not present in the robot data. Videos are at https://homangab.github.io/gen2act/
MotIF: Motion Instruction Fine-tuning
Sep 16, 2024



While success in many robotics tasks can be determined by only observing the final state and how it differs from the initial state - e.g., if an apple is picked up - many tasks require observing the full motion of the robot to correctly determine success. For example, brushing hair requires repeated strokes that correspond to the contours and type of hair. Prior works often use off-the-shelf vision-language models (VLMs) as success detectors; however, when success depends on the full trajectory, VLMs struggle to make correct judgments for two reasons. First, modern VLMs are trained only on single frames, and cannot capture changes over a full trajectory. Second, even if we provide state-of-the-art VLMs with an aggregate input of multiple frames, they still fail to detect success due to a lack of robot data. Our key idea is to fine-tune VLMs using abstract representations that are able to capture trajectory-level information such as the path the robot takes by overlaying keypoint trajectories on the final image. We propose motion instruction fine-tuning (MotIF), a method that fine-tunes VLMs using the aforementioned abstract representations to semantically ground the robot's behavior in the environment. To benchmark and fine-tune VLMs for robotic motion understanding, we introduce the MotIF-1K dataset containing 653 human and 369 robot demonstrations across 13 task categories. MotIF assesses the success of robot motion given the image observation of the trajectory, task instruction, and motion description. Our model significantly outperforms state-of-the-art VLMs by at least twice in precision and 56.1% in recall, generalizing across unseen motions, tasks, and environments. Finally, we demonstrate practical applications of MotIF in refining and terminating robot planning, and ranking trajectories on how they align with task and motion descriptions. Project page: https://motif-1k.github.io