 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptivePose: Human Parts as Adaptive Points
Dec 27, 2021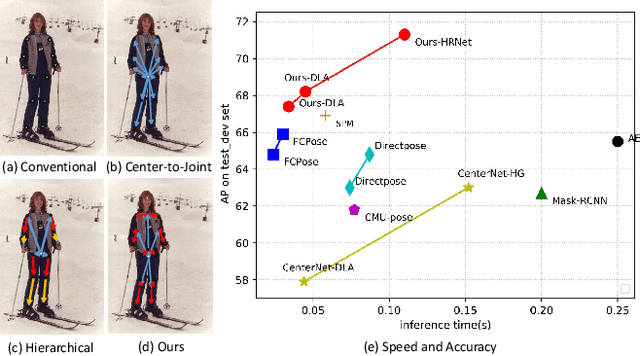
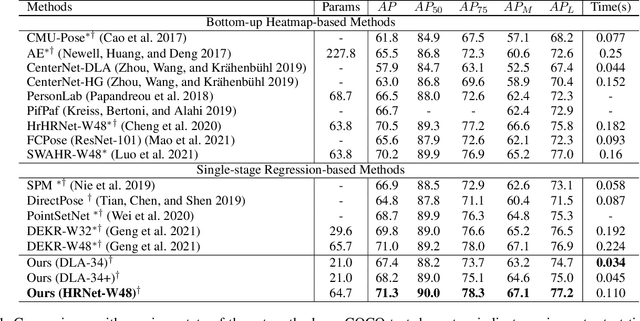
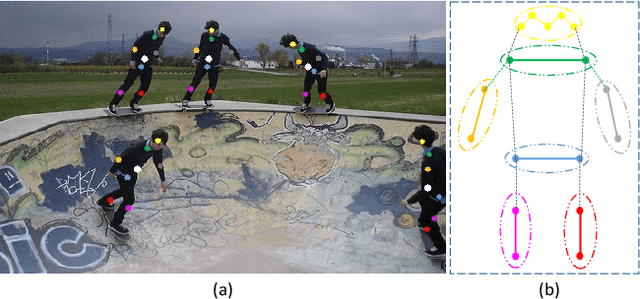
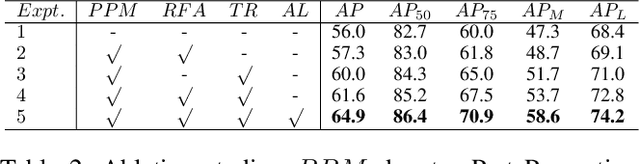
Multi-person pose estimation methods generally follow top-down and bottom-up paradigms, both of which can be considered as two-stage approaches thus leading to the high computation cost and low efficiency. Towards a compact and efficient pipeline for multi-person pose estimation task, in this paper, we propose to represent the human parts as points and present a novel body representation, which leverages an adaptive point set including the human center and seven human-part related points to represent the human instance in a more fine-grained manner. The novel representation is more capable of capturing the various pose deformation and adaptively factorizes the long-range center-to-joint displacement thus delivers a single-stage differentiable network to more precisely regress multi-person pose, termed as AdaptivePose. For inference, our proposed network eliminates the grouping as well as refinements and only needs a single-step disentangling process to form multi-person pose. Without any bells and whistles, we achieve the best speed-accuracy trade-offs of 67.4% AP / 29.4 fps with DLA-34 and 71.3% AP / 9.1 fps with HRNet-W48 on COCO test-dev dataset.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
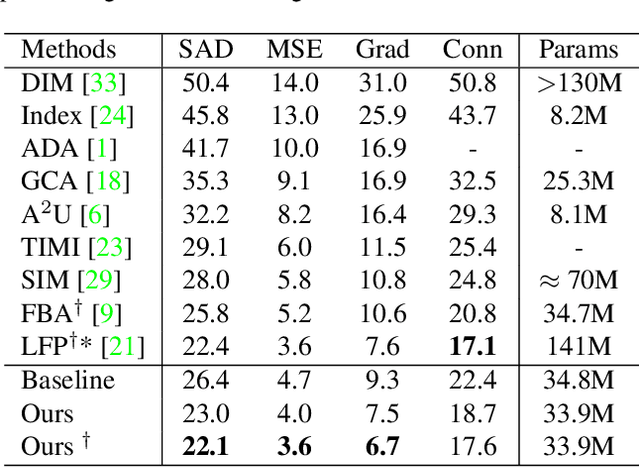
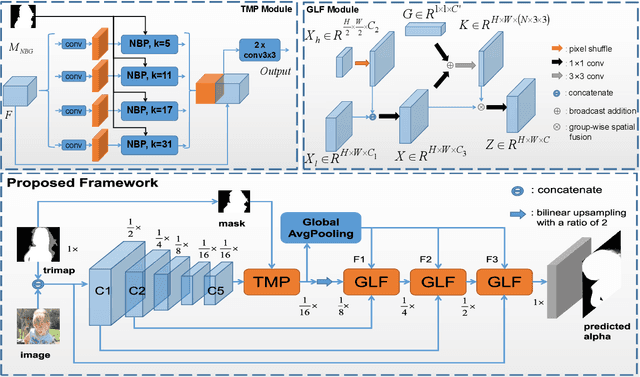
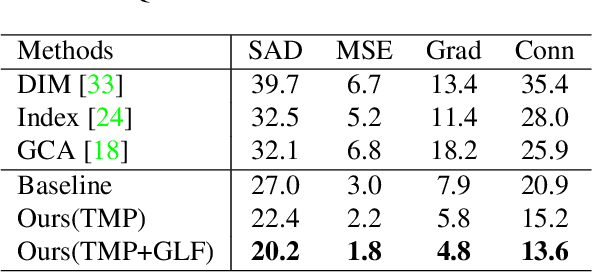
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Oct 14, 2021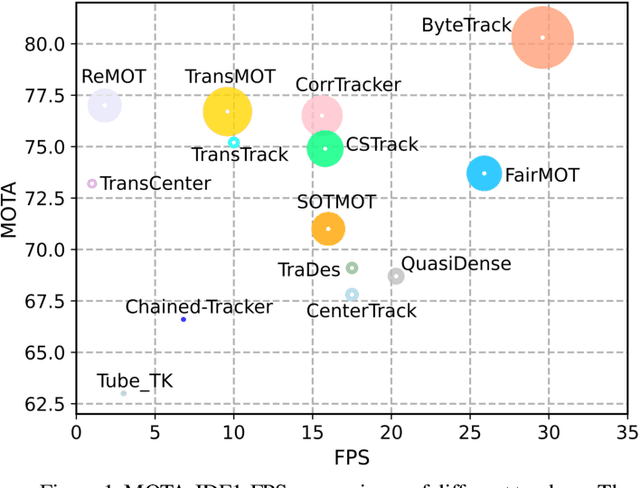


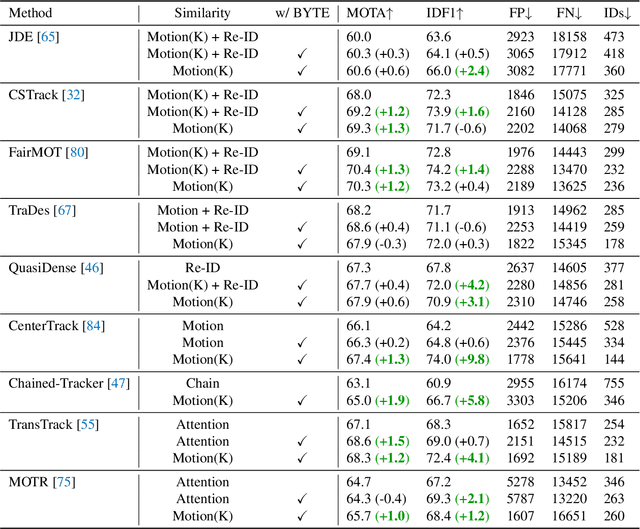
Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects in videos. Most methods obtain identities by associating detection boxes whose scores are higher than a threshold. The objects with low detection scores, e.g. occluded objects, are simply thrown away, which brings non-negligible true object missing and fragmented trajectories. To solve this problem, we present a simple, effective and generic association method, called BYTE, tracking BY associaTing Every detection box instead of only the high score ones. For the low score detection boxes, we utilize their similarities with tracklets to recover true objects and filter out the background detections. We apply BYTE to 9 different state-of-the-art trackers and achieve consistent improvement on IDF1 score ranging from 1 to 10 points. To put forwards the state-of-the-art performance of MOT, we design a simple and strong tracker, named ByteTrack. For the first time, we achieve 80.3 MOTA, 77.3 IDF1 and 63.1 HOTA on the test set of MOT17 with 30 FPS running speed on a single V100 GPU. The source code, pre-trained models with deploy versions and tutorials of applying to other trackers are released at https://github.com/ifzhang/ByteTrack.
Weakly Supervised Person Search with Region Siamese Networks
Sep 13, 2021

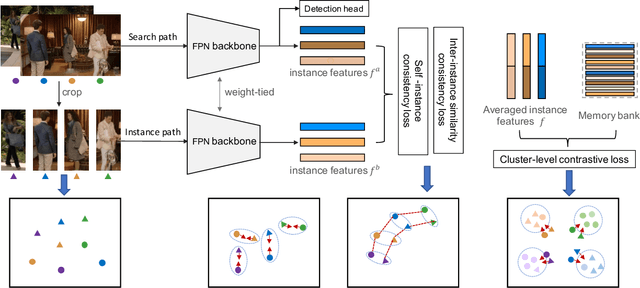
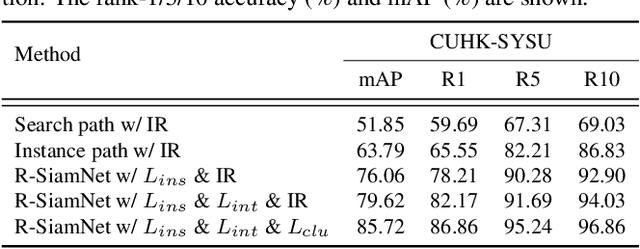
Supervised learning is dominant in person search, but it requires elaborate labeling of bounding boxes and identities. Large-scale labeled training data is often difficult to collect, especially for person identities. A natural question is whether a good person search model can be trained without the need of identity supervision. In this paper, we present a weakly supervised setting where only bounding box annotations are available. Based on this new setting, we provide an effective baseline model termed Region Siamese Networks (R-SiamNets). Towards learning useful representations for recognition in the absence of identity labels, we supervise the R-SiamNet with instance-level consistency loss and cluster-level contrastive loss. For instance-level consistency learning, the R-SiamNet is constrained to extract consistent features from each person region with or without out-of-region context. For cluster-level contrastive learning, we enforce the aggregation of closest instances and the separation of dissimilar ones in feature space. Extensive experiments validate the utility of our weakly supervised method. Our model achieves the rank-1 of 87.1% and mAP of 86.0% on CUHK-SYSU benchmark, which surpasses several fully supervised methods, such as OIM and MGTS, by a clear margin. More promising performance can be reached by incorporating extra training data. We hope this work could encourage the future research in this field.
Memory Based Video Scene Parsing
Sep 01, 2021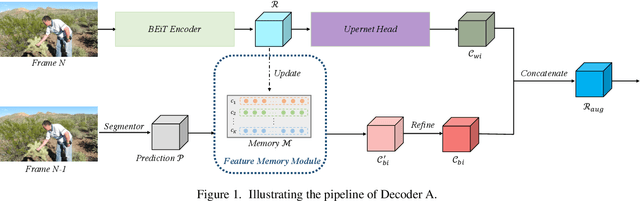
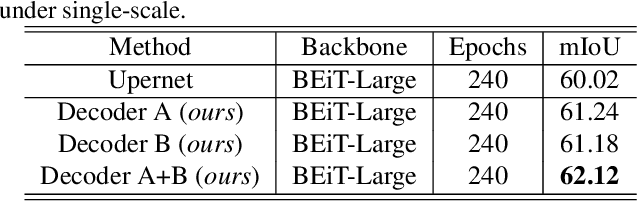
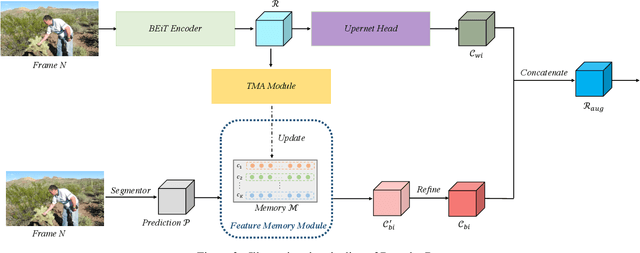
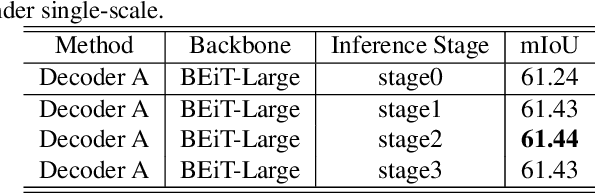
Video scene parsing is a long-standing challenging task in computer vision, aiming to assign pre-defined semantic labels to pixels of all frames in a given video. Compared with image semantic segmentation, this task pays more attention on studying how to adopt the temporal information to obtain higher predictive accuracy. In this report, we introduce our solution for the 1st Video Scene Parsing in the Wild Challenge, which achieves a mIoU of 57.44 and obtained the 2nd place (our team name is CharlesBLWX).
Mining Contextual Information Beyond Image for Semantic Segmentation
Aug 26, 2021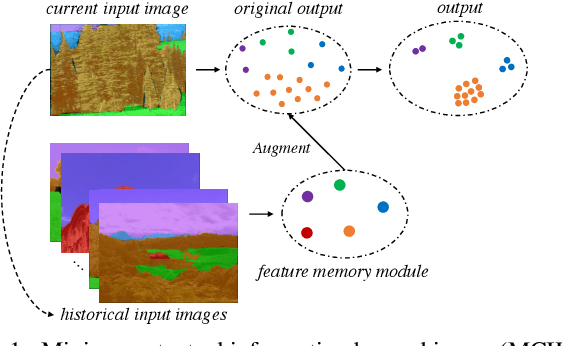

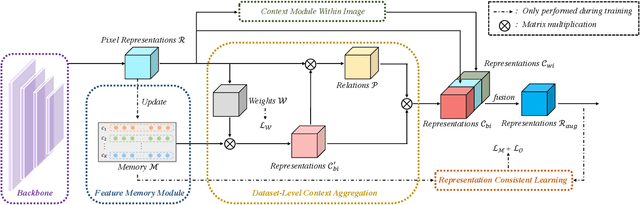

This paper studies the context aggregation problem in semantic image segmentation. The existing researches focus on improving the pixel representations by aggregating the contextual information within individual images. Though impressive, these methods neglect the significance of the representations of the pixels of the corresponding class beyond the input image. To address this, this paper proposes to mine the contextual information beyond individual images to further augment the pixel representations. We first set up a feature memory module, which is updated dynamically during training, to store the dataset-level representations of various categories. Then, we learn class probability distribution of each pixel representation under the supervision of the ground-truth segmentation. At last, the representation of each pixel is augmented by aggregating the dataset-level representations based on the corresponding class probability distribution. Furthermore, by utilizing the stored dataset-level representations, we also propose a representation consistent learning strategy to make the classification head better address intra-class compactness and inter-class dispersion. The proposed method could be effortlessly incorporated into existing segmentation frameworks (e.g., FCN, PSPNet, OCRNet and DeepLabV3) and brings consistent performance improvements. Mining contextual information beyond image allows us to report state-of-the-art performance on various benchmarks: ADE20K, LIP, Cityscapes and COCO-Stuff.
Body Meshes as Points
May 06, 2021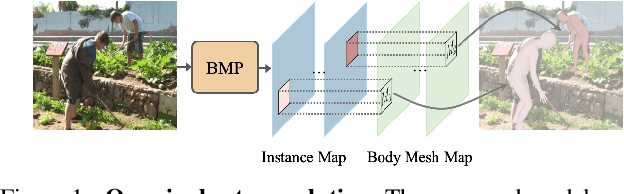

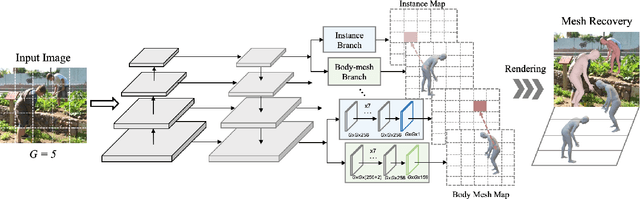

We consider the challenging multi-person 3D body mesh estimation task in this work. Existing methods are mostly two-stage based--one stage for person localization and the other stage for individual body mesh estimation, leading to redundant pipelines with high computation cost and degraded performance for complex scenes (e.g., occluded person instances). In this work, we present a single-stage model, Body Meshes as Points (BMP), to simplify the pipeline and lift both efficiency and performance. In particular, BMP adopts a new method that represents multiple person instances as points in the spatial-depth space where each point is associated with one body mesh. Hinging on such representations, BMP can directly predict body meshes for multiple persons in a single stage by concurrently localizing person instance points and estimating the corresponding body meshes. To better reason about depth ordering of all the persons within the same scene, BMP designs a simple yet effective inter-instance ordinal depth loss to obtain depth-coherent body mesh estimation. BMP also introduces a novel keypoint-aware augmentation to enhance model robustness to occluded person instances. Comprehensive experiments on benchmarks Panoptic, MuPoTS-3D and 3DPW clearly demonstrate the state-of-the-art efficiency of BMP for multi-person body mesh estimation, together with outstanding accuracy. Code can be found at: https://github.com/jfzhang95/BMP.
Conditional Meta-Network for Blind Super-Resolution with Multiple Degradations
Apr 09, 2021


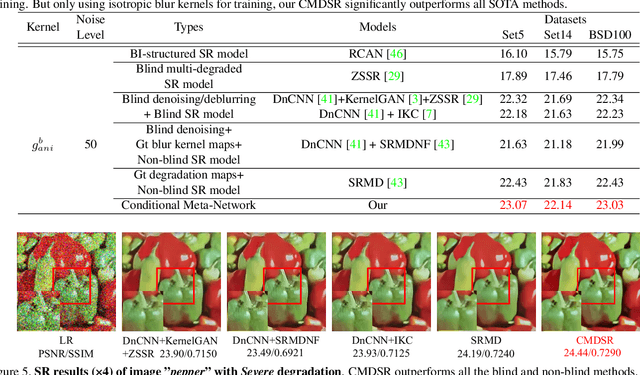
Although single-image super-resolution (SISR) methods have achieved great success on single degradation, they still suffer performance drop with multiple degrading effects in real scenarios. Recently, some blind and non-blind models for multiple degradations have been explored. However, those methods usually degrade significantly for distribution shifts between the training and test data. Towards this end, we propose a conditional meta-network framework (named CMDSR) for the first time, which helps SR framework learn how to adapt to changes in input distribution. We extract degradation prior at task-level with the proposed ConditionNet, which will be used to adapt the parameters of the basic SR network (BaseNet). Specifically, the ConditionNet of our framework first learns the degradation prior from a support set, which is composed of a series of degraded image patches from the same task. Then the adaptive BaseNet rapidly shifts its parameters according to the conditional features. Moreover, in order to better extract degradation prior, we propose a task contrastive loss to decrease the inner-task distance and increase the cross-task distance between task-level features. Without predefining degradation maps, our blind framework can conduct one single parameter update to yield considerable SR results. Extensive experiments demonstrate the effectiveness of CMDSR over various blind, even non-blind methods. The flexible BaseNet structure also reveals that CMDSR can be a general framework for large series of SISR models.
F2Net: Learning to Focus on the Foreground for Unsupervised Video Object Segmentation
Dec 04, 2020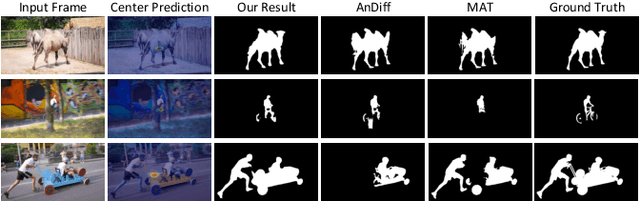
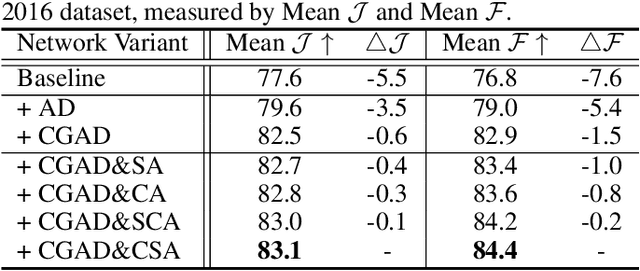
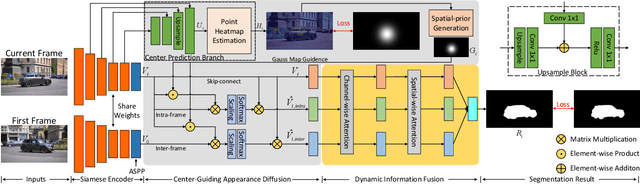
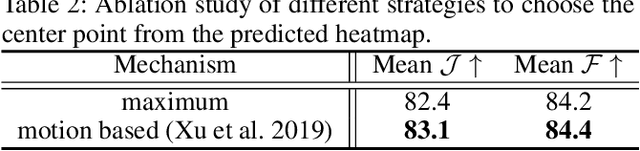
Although deep learning based methods have achieved great progress in unsupervised video object segmentation, difficult scenarios (e.g., visual similarity, occlusions, and appearance changing) are still not well-handled. To alleviate these issues, we propose a novel Focus on Foreground Network (F2Net), which delves into the intra-inter frame details for the foreground objects and thus effectively improve the segmentation performance. Specifically, our proposed network consists of three main parts: Siamese Encoder Module, Center Guiding Appearance Diffusion Module, and Dynamic Information Fusion Module. Firstly, we take a siamese encoder to extract the feature representations of paired frames (reference frame and current frame). Then, a Center Guiding Appearance Diffusion Module is designed to capture the inter-frame feature (dense correspondences between reference frame and current frame), intra-frame feature (dense correspondences in current frame), and original semantic feature of current frame. Specifically, we establish a Center Prediction Branch to predict the center location of the foreground object in current frame and leverage the center point information as spatial guidance prior to enhance the inter-frame and intra-frame feature extraction, and thus the feature representation considerably focus on the foreground objects. Finally, we propose a Dynamic Information Fusion Module to automatically select relatively important features through three aforementioned different level features. Extensive experiments on DAVIS2016, Youtube-object, and FBMS datasets show that our proposed F2Net achieves the state-of-the-art performance with significant improvement.
SPCNet:Spatial Preserve and Content-aware Network for Human Pose Estimation
Apr 13, 2020
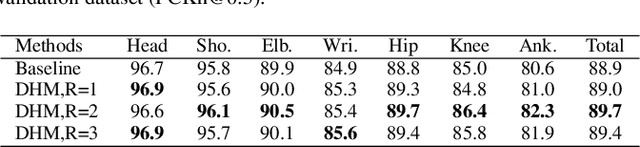
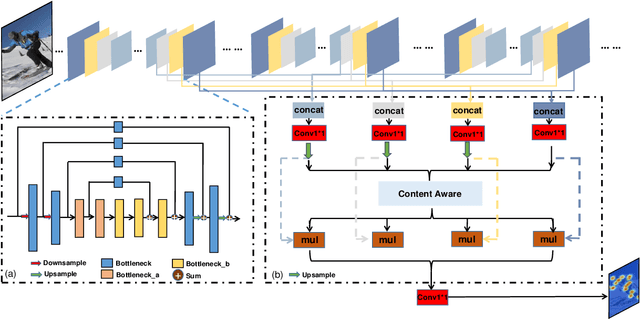
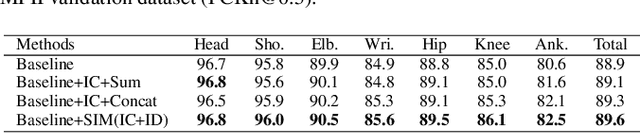
Human pose estimation is a fundamental yet challenging task in computer vision. Although deep learning techniques have made great progress in this area, difficult scenarios (e.g., invisible keypoints, occlusions, complex multi-person scenarios, and abnormal poses) are still not well-handled. To alleviate these issues, we propose a novel Spatial Preserve and Content-aware Network(SPCNet), which includes two effective modules: Dilated Hourglass Module(DHM) and Selective Information Module(SIM). By using the Dilated Hourglass Module, we can preserve the spatial resolution along with large receptive field. Similar to Hourglass Network, we stack the DHMs to get the multi-stage and multi-scale information. Then, a Selective Information Module is designed to select relatively important features from different levels under a sufficient consideration of spatial content-aware mechanism and thus considerably improves the performance. Extensive experiments on MPII, LSP and FLIC human pose estimation benchmarks demonstrate the effectiveness of our network. In particular, we exceed previous methods and achieve the state-of-the-art performance on three aforementioned benchmark datasets.