 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation
Dec 14, 2023



Recent advancements in text-to-3D generation technology have significantly advanced the conversion of textual descriptions into imaginative well-geometrical and finely textured 3D objects. Despite these developments, a prevalent limitation arises from the use of RGB data in diffusion or reconstruction models, which often results in models with inherent lighting and shadows effects that detract from their realism, thereby limiting their usability in applications that demand accurate relighting capabilities. To bridge this gap, we present UniDream, a text-to-3D generation framework by incorporating unified diffusion priors. Our approach consists of three main components: (1) a dual-phase training process to get albedo-normal aligned multi-view diffusion and reconstruction models, (2) a progressive generation procedure for geometry and albedo-textures based on Score Distillation Sample (SDS) using the trained reconstruction and diffusion models, and (3) an innovative application of SDS for finalizing PBR generation while keeping a fixed albedo based on Stable Diffusion model. Extensive evaluations demonstrate that UniDream surpasses existing methods in generating 3D objects with clearer albedo textures, smoother surfaces, enhanced realism, and superior relighting capabilities.
EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Dec 11, 2023Generating multiview images from a single view facilitates the rapid generation of a 3D mesh conditioned on a single image. Recent methods that introduce 3D global representation into diffusion models have shown the potential to generate consistent multiviews, but they have reduced generation speed and face challenges in maintaining generalizability and quality. To address this issue, we propose EpiDiff, a localized interactive multiview diffusion model. At the core of the proposed approach is to insert a lightweight epipolar attention block into the frozen diffusion model, leveraging epipolar constraints to enable cross-view interaction among feature maps of neighboring views. The newly initialized 3D modeling module preserves the original feature distribution of the diffusion model, exhibiting compatibility with a variety of base diffusion models. Experiments show that EpiDiff generates 16 multiview images in just 12 seconds, and it surpasses previous methods in quality evaluation metrics, including PSNR, SSIM and LPIPS. Additionally, EpiDiff can generate a more diverse distribution of views, improving the reconstruction quality from generated multiviews. Please see our project page at https://huanngzh.github.io/EpiDiff/.
Text-to-3D with Classifier Score Distillation
Oct 31, 2023



Text-to-3D generation has made remarkable progress recently, particularly with methods based on Score Distillation Sampling (SDS) that leverages pre-trained 2D diffusion models. While the usage of classifier-free guidance is well acknowledged to be crucial for successful optimization, it is considered an auxiliary trick rather than the most essential component. In this paper, we re-evaluate the role of classifier-free guidance in score distillation and discover a surprising finding: the guidance alone is enough for effective text-to-3D generation tasks. We name this method Classifier Score Distillation (CSD), which can be interpreted as using an implicit classification model for generation. This new perspective reveals new insights for understanding existing techniques. We validate the effectiveness of CSD across a variety of text-to-3D tasks including shape generation, texture synthesis, and shape editing, achieving results superior to those of state-of-the-art methods. Our project page is https://xinyu-andy.github.io/Classifier-Score-Distillation
TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023



Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
VCSUM: A Versatile Chinese Meeting Summarization Dataset
May 15, 2023



Compared to news and chat summarization, the development of meeting summarization is hugely decelerated by the limited data. To this end, we introduce a versatile Chinese meeting summarization dataset, dubbed VCSum, consisting of 239 real-life meetings, with a total duration of over 230 hours. We claim our dataset is versatile because we provide the annotations of topic segmentation, headlines, segmentation summaries, overall meeting summaries, and salient sentences for each meeting transcript. As such, the dataset can adapt to various summarization tasks or methods, including segmentation-based summarization, multi-granularity summarization and retrieval-then-generate summarization. Our analysis confirms the effectiveness and robustness of VCSum. We also provide a set of benchmark models regarding different downstream summarization tasks on VCSum to facilitate further research. The dataset and code will be released at https://github.com/hahahawu/VCSum.
Self-Supervised Sentence Compression for Meeting Summarization
May 13, 2023



The conventional summarization model often fails to capture critical information in meeting transcripts, as meeting corpus usually involves multiple parties with lengthy conversations and is stuffed with redundant and trivial content. To tackle this problem, we present SVB, an effective and efficient framework for meeting summarization that `compress' the redundancy while preserving important content via three processes: sliding-window dialogue restoration and \textbf{S}coring, channel-wise importance score \textbf{V}oting, and relative positional \textbf{B}ucketing. Specifically, under the self-supervised paradigm, the sliding-window scoring aims to rate the importance of each token from multiple views. Then these ratings are aggregated by channel-wise voting. Tokens with high ratings will be regarded as salient information and labeled as \textit{anchors}. Finally, to tailor the lengthy input to an acceptable length for the language model, the relative positional bucketing algorithm is performed to retain the anchors while compressing other irrelevant contents in different granularities. Without large-scale pre-training or expert-grade annotating tools, our proposed method outperforms previous state-of-the-art approaches. A vast amount of evaluations and analyses are conducted to prove the effectiveness of our method.
Towards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
May 12, 2023



Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023



Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.
Improving Robust Fairness via Balance Adversarial Training
Sep 15, 2022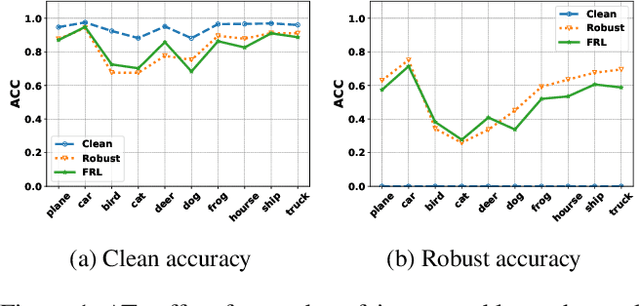
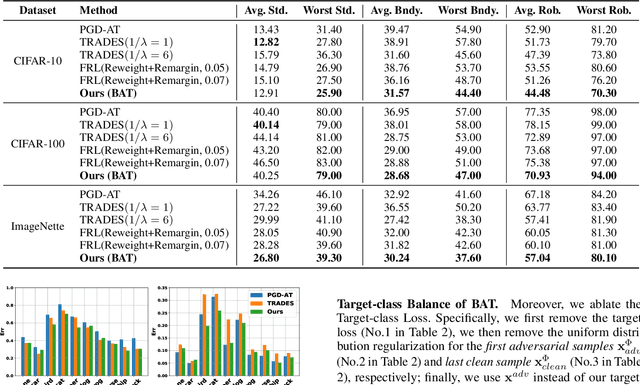
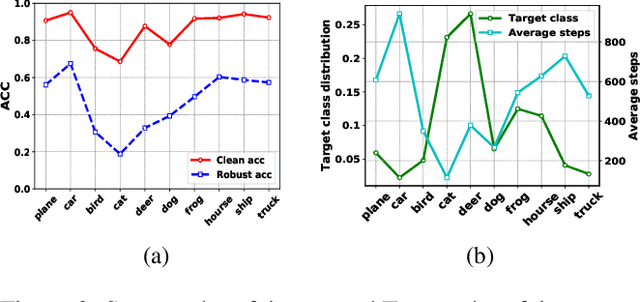

Adversarial training (AT) methods are effective against adversarial attacks, yet they introduce severe disparity of accuracy and robustness between different classes, known as the robust fairness problem. Previously proposed Fair Robust Learning (FRL) adaptively reweights different classes to improve fairness. However, the performance of the better-performed classes decreases, leading to a strong performance drop. In this paper, we observed two unfair phenomena during adversarial training: different difficulties in generating adversarial examples from each class (source-class fairness) and disparate target class tendencies when generating adversarial examples (target-class fairness). From the observations, we propose Balance Adversarial Training (BAT) to address the robust fairness problem. Regarding source-class fairness, we adjust the attack strength and difficulties of each class to generate samples near the decision boundary for easier and fairer model learning; considering target-class fairness, by introducing a uniform distribution constraint, we encourage the adversarial example generation process for each class with a fair tendency. Extensive experiments conducted on multiple datasets (CIFAR-10, CIFAR-100, and ImageNette) demonstrate that our method can significantly outperform other baselines in mitigating the robust fairness problem (+5-10\% on the worst class accuracy)
Adaptive Perturbation Generation for Multiple Backdoors Detection
Sep 13, 2022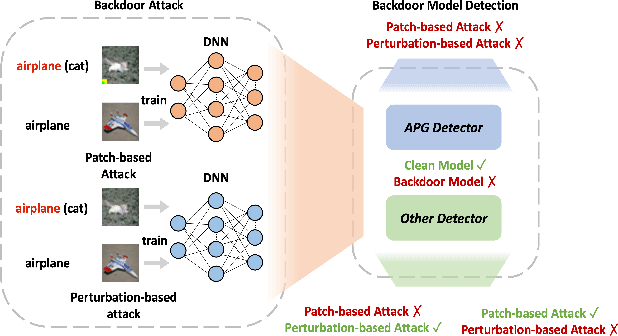
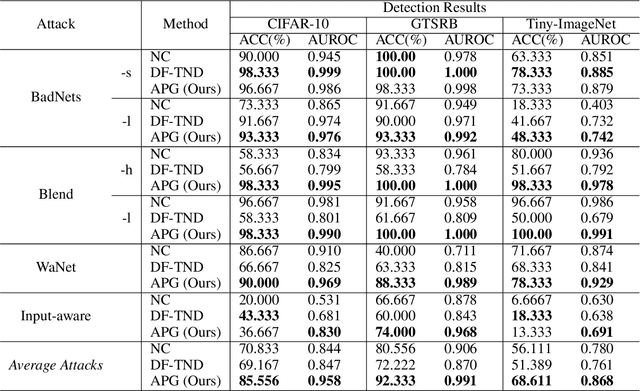
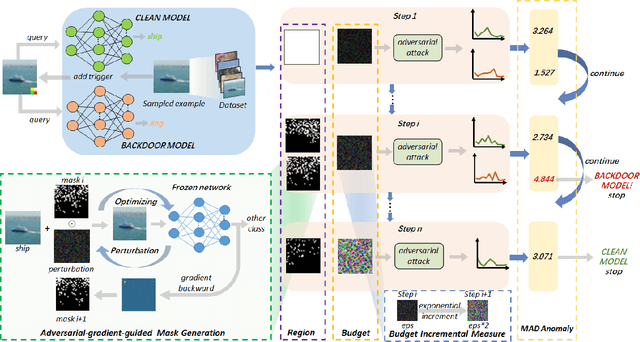
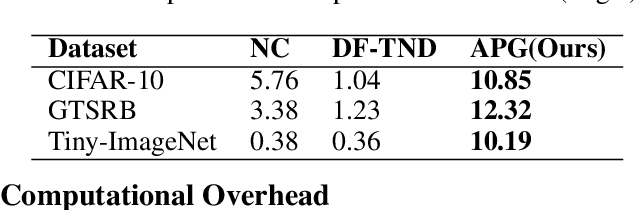
Extensive evidence has demonstrated that deep neural networks (DNNs) are vulnerable to backdoor attacks, which motivates the development of backdoor detection methods. Existing backdoor detection methods are typically tailored for backdoor attacks with individual specific types (e.g., patch-based or perturbation-based). However, adversaries are likely to generate multiple types of backdoor attacks in practice, which challenges the current detection strategies. Based on the fact that adversarial perturbations are highly correlated with trigger patterns, this paper proposes the Adaptive Perturbation Generation (APG) framework to detect multiple types of backdoor attacks by adaptively injecting adversarial perturbations. Since different trigger patterns turn out to show highly diverse behaviors under the same adversarial perturbations, we first design the global-to-local strategy to fit the multiple types of backdoor triggers via adjusting the region and budget of attacks. To further increase the efficiency of perturbation injection, we introduce a gradient-guided mask generation strategy to search for the optimal regions for adversarial attacks. Extensive experiments conducted on multiple datasets (CIFAR-10, GTSRB, Tiny-ImageNet) demonstrate that our method outperforms state-of-the-art baselines by large margins(+12%).