 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInsight: A Unified Evaluation Infrastructure Across the Physical AI Stack
Jun 16, 2026Evaluating a Physical AI stack spans operators that differ by more than three orders of magnitude -- from a single foundation-model decoding step to thousands of physics ticks of whole-body control -- varying orthogonally in modality, reward semantics, and resource profile. No existing framework spans this range, so the stack is evaluated today by stitching together separate harnesses that share neither runtime nor scoring, preserving each segment's local validity but losing the shared identity needed to diagnose cross-layer regressions. We present DeepInsight, an evaluation infrastructure that serves this full spectrum on a single runtime. Rather than homogenize the regimes, it preserves their heterogeneity behind three narrow abstractions -- task, resource, and result -- each realized as one invariant shared by every subsystem: one episode driver, one resource-handle protocol implemented by every expensive backend (LLM inference and sandboxed runtimes alike), and one trace identity scheme under which every event is written. Deployed in production across all three layers of an embodied humanoid stack, this single set of invariants onboards new benchmarks largely by configuration. Where mature peer orchestrators exist -- at the foundation-model end -- it reproduces published references and peer-framework readings within their own spread, runs the same suites faster on a single node, and scales near-linearly across nodes. Its distinctive return is diagnostic: because every layer writes into one shared trace, a regression that begins in one layer and surfaces in another stays localizable on that trace -- a cross-layer payoff no federation of per-segment harnesses can reproduce.
Let Geometry GUIDE: Layer-wise Unrolling of Geometric Priors in Multimodal LLMs
Apr 07, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in 2D visual tasks but still exhibit limited physical spatial awareness when processing real-world visual streams. Recently, feed-forward geometric foundation models, which implicitly extract geometric priors, have provided a new pathway to address this issue. However, existing geometry-aware MLLMs are predominantly constrained by the paradigm of single deep-layer extraction and input-level fusion. This flattened fusion leads to the loss of local geometric details and causes semantic mismatches in the early layers. To break this bottleneck, we propose GUIDE (Geometric Unrolling Inside MLLM Early-layers), a progressive geometric priors injection framework. GUIDE performs multi-level sampling within the geometric encoder, comprehensively capturing multi-granularity features ranging from local edges to global topologies. Subsequently, we rigorously align and fuse these multi-level geometric priors step-by-step with the early layers of the MLLM. Building upon the injection of multi-granularity geometric information, this design guides the model to progressively learn the 2D-to-3D transitional process. Furthermore, we introduce a context-aware gating that enables the model to fetch requisite spatial cues based on current semantics, thereby maximizing the utilization efficiency of spatial priors and effectively suppressing redundant geometric noise. Extensive experiments demonstrate that GUIDE significantly outperforms existing baselines on multiple complex spatial reasoning and perception tasks, establishing a novel paradigm for integrating 3D geometric priors into large models.
Improving Robust Fairness via Balance Adversarial Training
Sep 15, 2022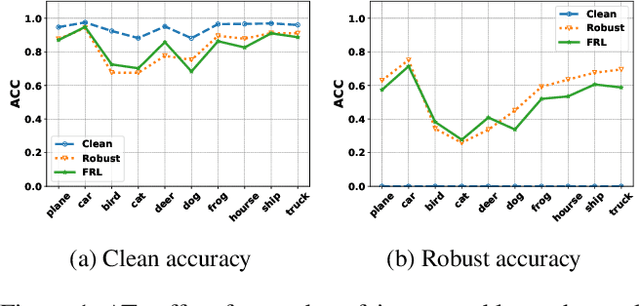
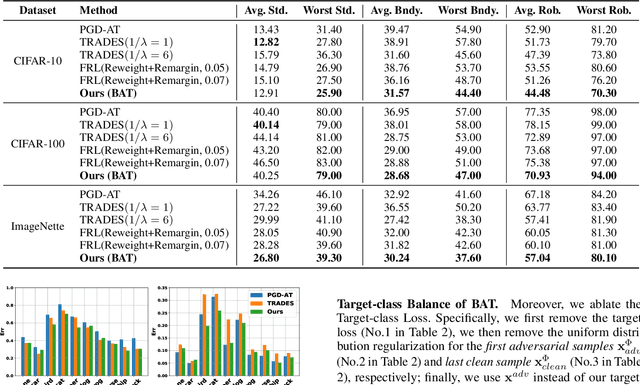
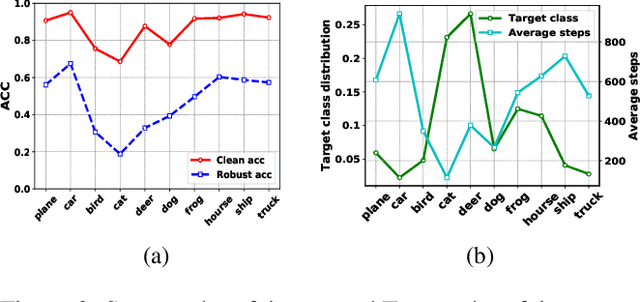

Adversarial training (AT) methods are effective against adversarial attacks, yet they introduce severe disparity of accuracy and robustness between different classes, known as the robust fairness problem. Previously proposed Fair Robust Learning (FRL) adaptively reweights different classes to improve fairness. However, the performance of the better-performed classes decreases, leading to a strong performance drop. In this paper, we observed two unfair phenomena during adversarial training: different difficulties in generating adversarial examples from each class (source-class fairness) and disparate target class tendencies when generating adversarial examples (target-class fairness). From the observations, we propose Balance Adversarial Training (BAT) to address the robust fairness problem. Regarding source-class fairness, we adjust the attack strength and difficulties of each class to generate samples near the decision boundary for easier and fairer model learning; considering target-class fairness, by introducing a uniform distribution constraint, we encourage the adversarial example generation process for each class with a fair tendency. Extensive experiments conducted on multiple datasets (CIFAR-10, CIFAR-100, and ImageNette) demonstrate that our method can significantly outperform other baselines in mitigating the robust fairness problem (+5-10\% on the worst class accuracy)
Semantic Segmentation-Assisted Instance Feature Fusion for Multi-Level 3D Part Instance Segmentation
Aug 09, 2022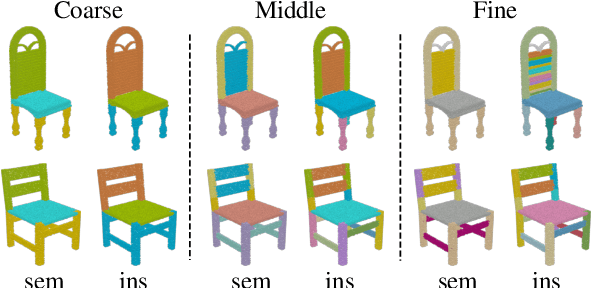
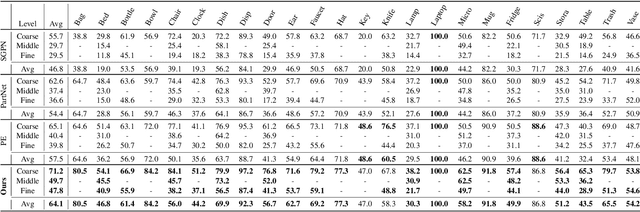
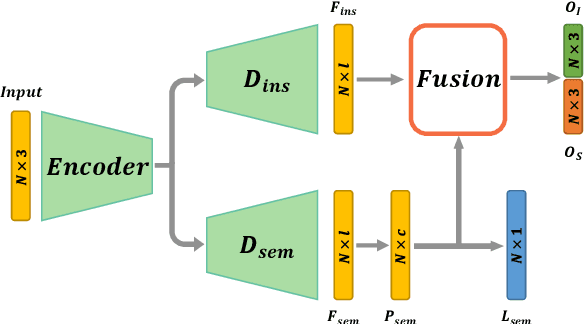

Recognizing 3D part instances from a 3D point cloud is crucial for 3D structure and scene understanding. Several learning-based approaches use semantic segmentation and instance center prediction as training tasks and fail to further exploit the inherent relationship between shape semantics and part instances. In this paper, we present a new method for 3D part instance segmentation. Our method exploits semantic segmentation to fuse nonlocal instance features, such as center prediction, and further enhances the fusion scheme in a multi- and cross-level way. We also propose a semantic region center prediction task to train and leverage the prediction results to improve the clustering of instance points. Our method outperforms existing methods with a large-margin improvement in the PartNet benchmark. We also demonstrate that our feature fusion scheme can be applied to other existing methods to improve their performance in indoor scene instance segmentation tasks.