 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloPart: Generative 3D Part Amodal Segmentation
Apr 10, 20253D part amodal segmentation--decomposing a 3D shape into complete, semantically meaningful parts, even when occluded--is a challenging but crucial task for 3D content creation and understanding. Existing 3D part segmentation methods only identify visible surface patches, limiting their utility. Inspired by 2D amodal segmentation, we introduce this novel task to the 3D domain and propose a practical, two-stage approach, addressing the key challenges of inferring occluded 3D geometry, maintaining global shape consistency, and handling diverse shapes with limited training data. First, we leverage existing 3D part segmentation to obtain initial, incomplete part segments. Second, we introduce HoloPart, a novel diffusion-based model, to complete these segments into full 3D parts. HoloPart utilizes a specialized architecture with local attention to capture fine-grained part geometry and global shape context attention to ensure overall shape consistency. We introduce new benchmarks based on the ABO and PartObjaverse-Tiny datasets and demonstrate that HoloPart significantly outperforms state-of-the-art shape completion methods. By incorporating HoloPart with existing segmentation techniques, we achieve promising results on 3D part amodal segmentation, opening new avenues for applications in geometry editing, animation, and material assignment.
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Feb 10, 2025Recent advancements in diffusion techniques have propelled image and video generation to unprece- dented levels of quality, significantly accelerating the deployment and application of generative AI. However, 3D shape generation technology has so far lagged behind, constrained by limitations in 3D data scale, complexity of 3D data process- ing, and insufficient exploration of advanced tech- niques in the 3D domain. Current approaches to 3D shape generation face substantial challenges in terms of output quality, generalization capa- bility, and alignment with input conditions. We present TripoSG, a new streamlined shape diffu- sion paradigm capable of generating high-fidelity 3D meshes with precise correspondence to input images. Specifically, we propose: 1) A large-scale rectified flow transformer for 3D shape generation, achieving state-of-the-art fidelity through training on extensive, high-quality data. 2) A hybrid supervised training strategy combining SDF, normal, and eikonal losses for 3D VAE, achieving high- quality 3D reconstruction performance. 3) A data processing pipeline to generate 2 million high- quality 3D samples, highlighting the crucial rules for data quality and quantity in training 3D gen- erative models. Through comprehensive experi- ments, we have validated the effectiveness of each component in our new framework. The seamless integration of these parts has enabled TripoSG to achieve state-of-the-art performance in 3D shape generation. The resulting 3D shapes exhibit en- hanced detail due to high-resolution capabilities and demonstrate exceptional fidelity to input im- ages. Moreover, TripoSG demonstrates improved versatility in generating 3D models from diverse image styles and contents, showcasing strong gen- eralization capabilities. To foster progress and innovation in the field of 3D generation, we will make our model publicly available.
Enhancing Sample Utilization in Noise-Robust Deep Metric Learning With Subgroup-Based Positive-Pair Selection
Jan 19, 2025



The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving the robustness towards noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains under-explored. Existing noisy label learning methods designed for DML mainly discard suspicious noisy samples, resulting in a waste of the training data. To address this issue, we propose a noise-robust DML framework with SubGroup-based Positive-pair Selection (SGPS), which constructs reliable positive pairs for noisy samples to enhance the sample utilization. Specifically, SGPS first effectively identifies clean and noisy samples by a probability-based clean sample selectionstrategy. To further utilize the remaining noisy samples, we discover their potential similar samples based on the subgroup information given by a subgroup generation module and then aggregate them into informative positive prototypes for each noisy sample via a positive prototype generation module. Afterward, a new contrastive loss is tailored for the noisy samples with their selected positive pairs. SGPS can be easily integrated into the training process of existing pair-wise DML tasks, like image retrieval and face recognition. Extensive experiments on multiple synthetic and real-world large-scale label noise datasets demonstrate the effectiveness of our proposed method. Without any bells and whistles, our SGPS framework outperforms the state-of-the-art noisy label DML methods. Code is available at \url{https://github.com/smuelpeng/SGPS-NoiseFreeDML}.
* arXiv admin note: substantial text overlap with arXiv:2108.01431, arXiv:2103.16047 by other authors
Estimating Long-term Heterogeneous Dose-response Curve: Generalization Bound Leveraging Optimal Transport Weights
Jun 27, 2024



Long-term causal effect estimation is a significant but challenging problem in many applications. Existing methods rely on ideal assumptions to estimate long-term average effects, e.g., no unobserved confounders or a binary treatment,while in numerous real-world applications, these assumptions could be violated and average effects are unable to provide individual-level suggestions.In this paper,we address a more general problem of estimating the long-term heterogeneous dose-response curve (HDRC) while accounting for unobserved confounders. Specifically, to remove unobserved confounding in observational data, we introduce an optimal transport weighting framework to align the observational data to the experimental data with theoretical guarantees. Furthermore,to accurately predict the heterogeneous effects of continuous treatment, we establish a generalization bound on counterfactual prediction error by leveraging the reweighted distribution induced by optimal transport. Finally, we develop an HDRC estimator building upon the above theoretical foundations. Extensive experimental studies conducted on multiple synthetic and semi-synthetic datasets demonstrate the effectiveness of our proposed method.
Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers
Dec 16, 2023



Recent advancements in 3D reconstruction from single images have been driven by the evolution of generative models. Prominent among these are methods based on Score Distillation Sampling (SDS) and the adaptation of diffusion models in the 3D domain. Despite their progress, these techniques often face limitations due to slow optimization or rendering processes, leading to extensive training and optimization times. In this paper, we introduce a novel approach for single-view reconstruction that efficiently generates a 3D model from a single image via feed-forward inference. Our method utilizes two transformer-based networks, namely a point decoder and a triplane decoder, to reconstruct 3D objects using a hybrid Triplane-Gaussian intermediate representation. This hybrid representation strikes a balance, achieving a faster rendering speed compared to implicit representations while simultaneously delivering superior rendering quality than explicit representations. The point decoder is designed for generating point clouds from single images, offering an explicit representation which is then utilized by the triplane decoder to query Gaussian features for each point. This design choice addresses the challenges associated with directly regressing explicit 3D Gaussian attributes characterized by their non-structural nature. Subsequently, the 3D Gaussians are decoded by an MLP to enable rapid rendering through splatting. Both decoders are built upon a scalable, transformer-based architecture and have been efficiently trained on large-scale 3D datasets. The evaluations conducted on both synthetic datasets and real-world images demonstrate that our method not only achieves higher quality but also ensures a faster runtime in comparison to previous state-of-the-art techniques. Please see our project page at https://zouzx.github.io/TriplaneGaussian/.
A Small and Fast BERT for Chinese Medical Punctuation Restoration
Aug 24, 2023



In clinical dictation, utterances after automatic speech recognition (ASR) without explicit punctuation marks may lead to the misunderstanding of dictated reports. To give a precise and understandable clinical report with ASR, automatic punctuation restoration is required. Considering a practical scenario, we propose a fast and light pre-trained model for Chinese medical punctuation restoration based on 'pretraining and fine-tuning' paradigm. In this work, we distill pre-trained models by incorporating supervised contrastive learning and a novel auxiliary pre-training task (Punctuation Mark Prediction) to make it well-suited for punctuation restoration. Our experiments on various distilled models reveal that our model can achieve 95% performance while 10% model size relative to state-of-the-art Chinese RoBERTa.
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023



Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.
HMDO: Markerless Multi-view Hand Manipulation Capture with Deformable Objects
Jan 18, 2023



We construct the first markerless deformable interaction dataset recording interactive motions of the hands and deformable objects, called HMDO (Hand Manipulation with Deformable Objects). With our built multi-view capture system, it captures the deformable interactions with multiple perspectives, various object shapes, and diverse interactive forms. Our motivation is the current lack of hand and deformable object interaction datasets, as 3D hand and deformable object reconstruction is challenging. Mainly due to mutual occlusion, the interaction area is difficult to observe, the visual features between the hand and the object are entangled, and the reconstruction of the interaction area deformation is difficult. To tackle this challenge, we propose a method to annotate our captured data. Our key idea is to collaborate with estimated hand features to guide the object global pose estimation, and then optimize the deformation process of the object by analyzing the relationship between the hand and the object. Through comprehensive evaluation, the proposed method can reconstruct interactive motions of hands and deformable objects with high quality. HMDO currently consists of 21600 frames over 12 sequences. In the future, this dataset could boost the research of learning-based reconstruction of deformable interaction scenes.
Speckle-based optical cryptosystem and its application for human face recognition via deep learning
Jan 26, 2022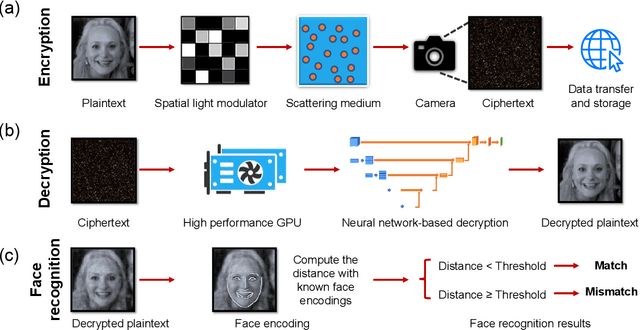
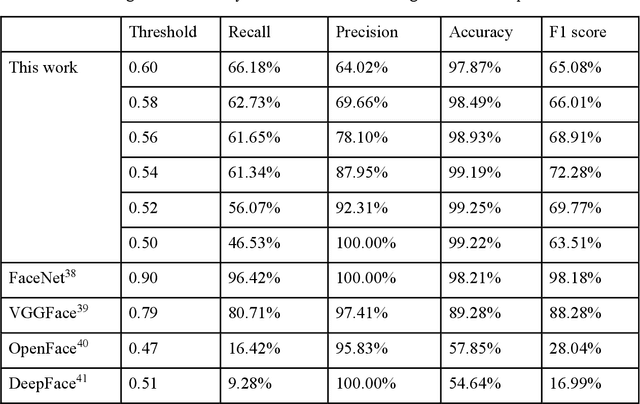
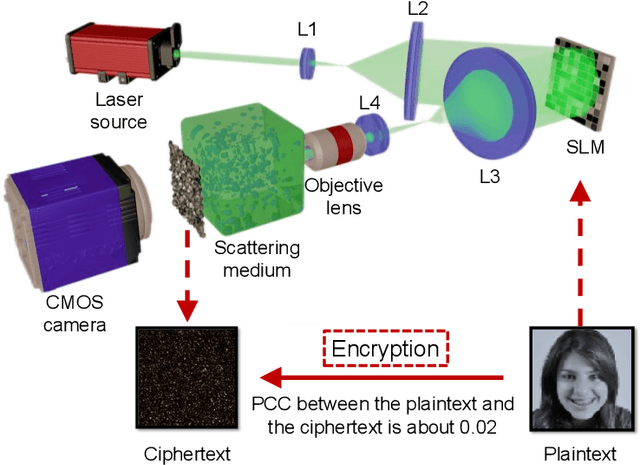
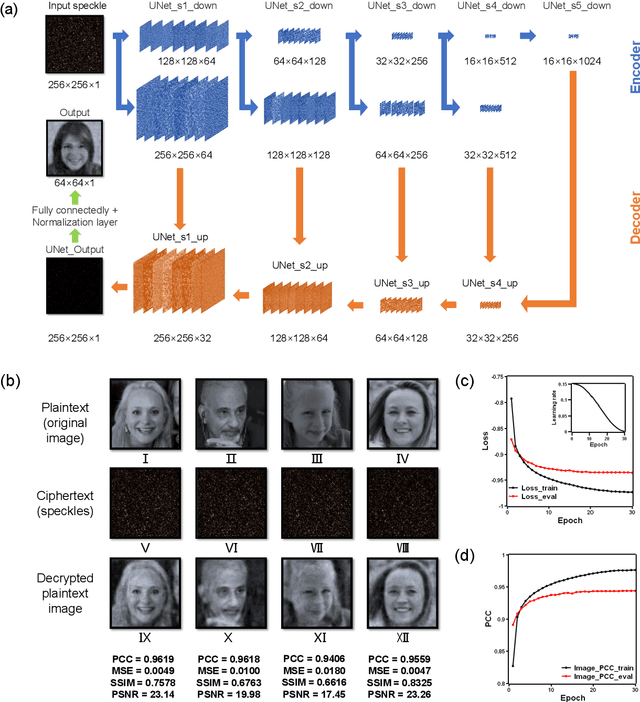
Face recognition has recently become ubiquitous in many scenes for authentication or security purposes. Meanwhile, there are increasing concerns about the privacy of face images, which are sensitive biometric data that should be carefully protected. Software-based cryptosystems are widely adopted nowadays to encrypt face images, but the security level is limited by insufficient digital secret key length or computing power. Hardware-based optical cryptosystems can generate enormously longer secret keys and enable encryption at light speed, but most reported optical methods, such as double random phase encryption, are less compatible with other systems due to system complexity. In this study, a plain yet high-efficient speckle-based optical cryptosystem is proposed and implemented. A scattering ground glass is exploited to generate physical secret keys of gigabit length and encrypt face images via seemingly random optical speckles at light speed. Face images can then be decrypted from the random speckles by a well-trained decryption neural network, such that face recognition can be realized with up to 98% accuracy. The proposed cryptosystem has wide applicability, and it may open a new avenue for high-security complex information encryption and decryption by utilizing optical speckles.