 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguageRefer: Spatial-Language Model for 3D Visual Grounding
Jul 22, 2021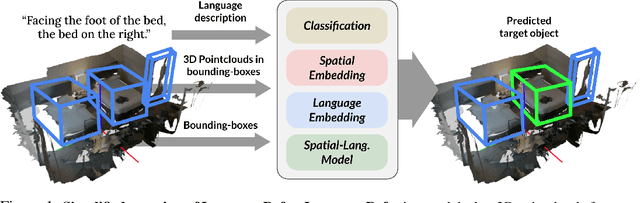
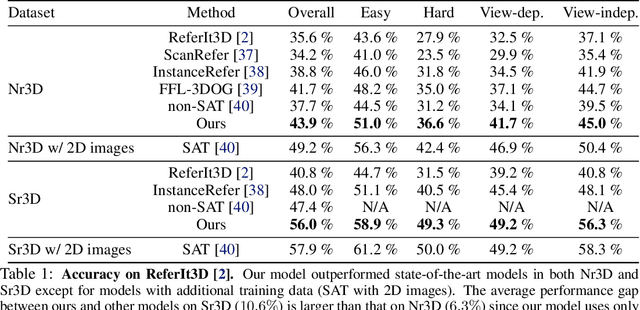
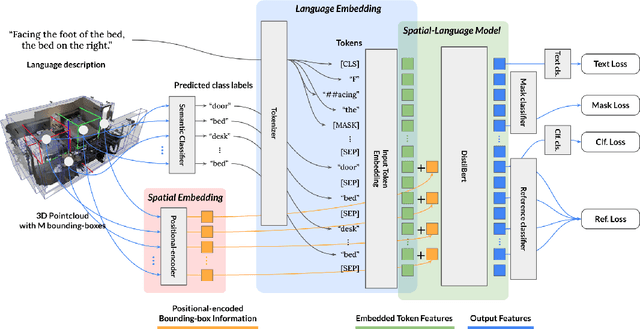
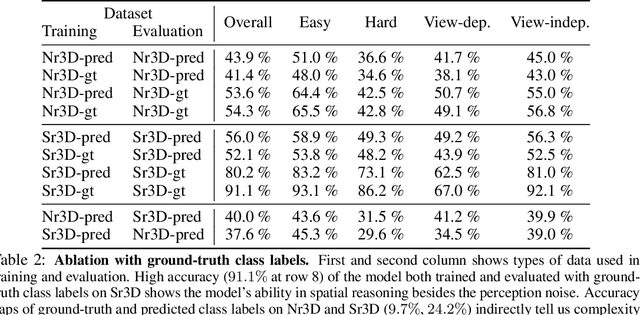
To realize robots that can understand human instructions and perform meaningful tasks in the near future, it is important to develop learned models that can understand referential language to identify common objects in real-world 3D scenes. In this paper, we develop a spatial-language model for a 3D visual grounding problem. Specifically, given a reconstructed 3D scene in the form of a point cloud with 3D bounding boxes of potential object candidates, and a language utterance referring to a target object in the scene, our model identifies the target object from a set of potential candidates. Our spatial-language model uses a transformer-based architecture that combines spatial embedding from bounding-box with a finetuned language embedding from DistilBert and reasons among the objects in the 3D scene to find the target object. We show that our model performs competitively on visio-linguistic datasets proposed by ReferIt3D. We provide additional analysis of performance in spatial reasoning tasks decoupled from perception noise, the effect of view-dependent utterances in terms of accuracy, and view-point annotations for potential robotics applications.
DefGraspSim: Simulation-based grasping of 3D deformable objects
Jul 12, 2021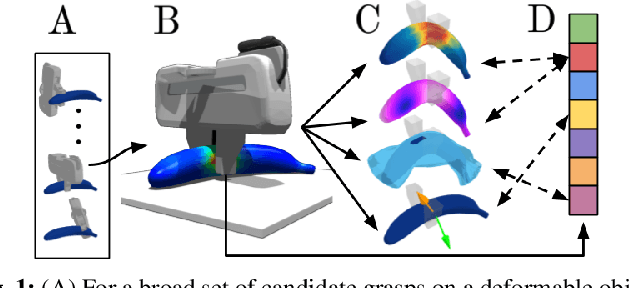
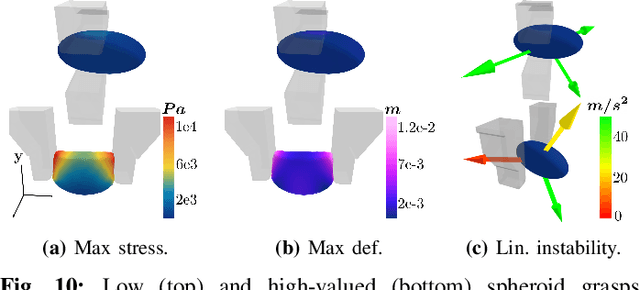

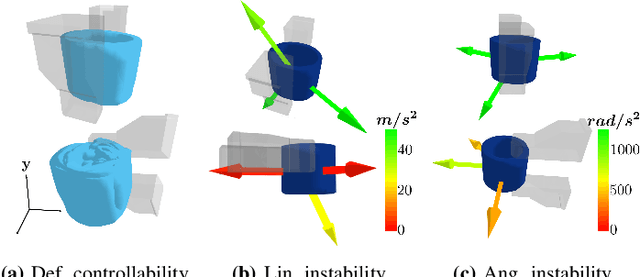
Robotic grasping of 3D deformable objects (e.g., fruits/vegetables, internal organs, bottles/boxes) is critical for real-world applications such as food processing, robotic surgery, and household automation. However, developing grasp strategies for such objects is uniquely challenging. In this work, we efficiently simulate grasps on a wide range of 3D deformable objects using a GPU-based implementation of the corotational finite element method (FEM). To facilitate future research, we open-source our simulated dataset (34 objects, 1e5 Pa elasticity range, 6800 grasp evaluations, 1.1M grasp measurements), as well as a code repository that allows researchers to run our full FEM-based grasp evaluation pipeline on arbitrary 3D object models of their choice. We also provide a detailed analysis on 6 object primitives. For each primitive, we methodically describe the effects of different grasp strategies, compute a set of performance metrics (e.g., deformation, stress) that fully capture the object response, and identify simple grasp features (e.g., gripper displacement, contact area) measurable by robots prior to pickup and predictive of these performance metrics. Finally, we demonstrate good correspondence between grasps on simulated objects and their real-world counterparts.
A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution
Jul 12, 2021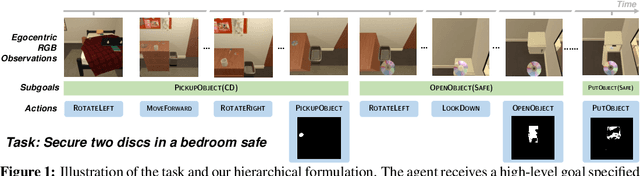
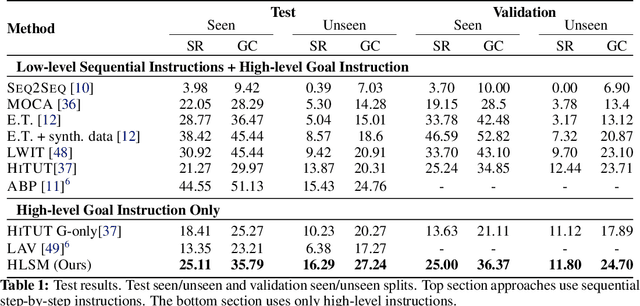
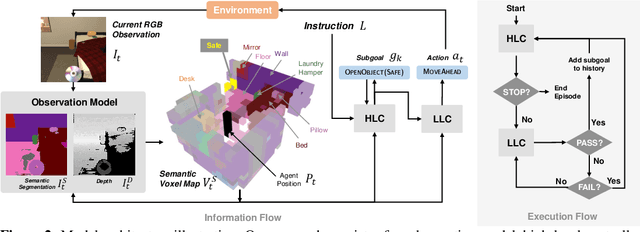
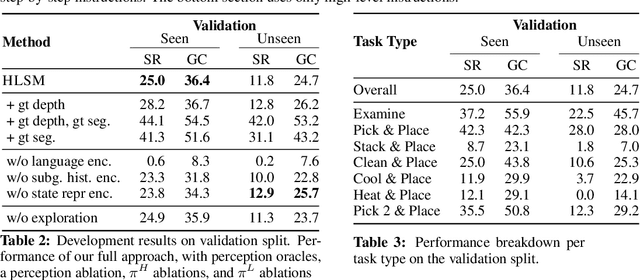
Natural language provides an accessible and expressive interface to specify long-term tasks for robotic agents. However, non-experts are likely to specify such tasks with high-level instructions, which abstract over specific robot actions through several layers of abstraction. We propose that key to bridging this gap between language and robot actions over long execution horizons are persistent representations. We propose a persistent spatial semantic representation method, and show how it enables building an agent that performs hierarchical reasoning to effectively execute long-term tasks. We evaluate our approach on the ALFRED benchmark and achieve state-of-the-art results, despite completely avoiding the commonly used step-by-step instructions.
BayesSimIG: Scalable Parameter Inference for Adaptive Domain Randomization with IsaacGym
Jul 09, 2021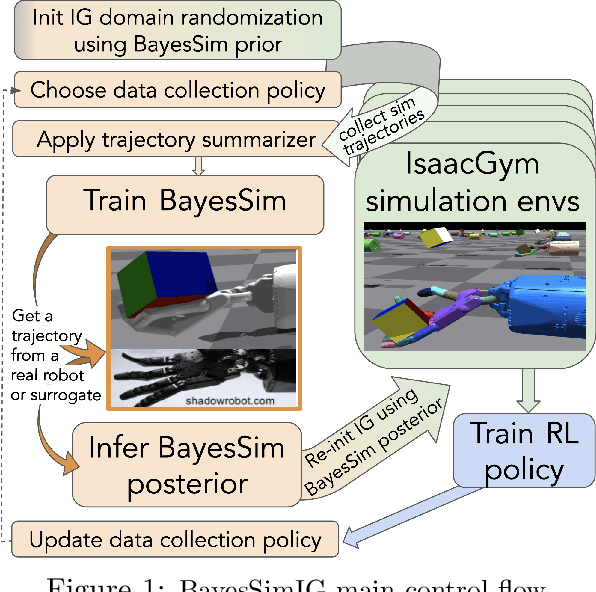

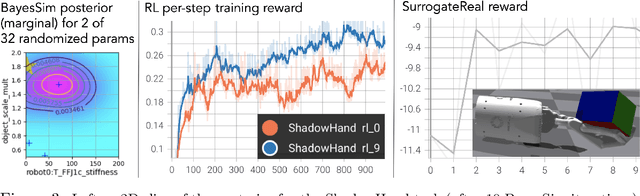
BayesSim is a statistical technique for domain randomization in reinforcement learning based on likelihood-free inference of simulation parameters. This paper outlines BayesSimIG: a library that provides an implementation of BayesSim integrated with the recently released NVIDIA IsaacGym. This combination allows large-scale parameter inference with end-to-end GPU acceleration. Both inference and simulation get GPU speedup, with support for running more than 10K parallel simulation environments for complex robotics tasks that can have more than 100 simulation parameters to estimate. BayesSimIG provides an integration with TensorBoard to easily visualize slices of high-dimensional posteriors. The library is built in a modular way to support research experiments with novel ways to collect and process the trajectories from the parallel IsaacGym environments.
Hierarchical Policies for Cluttered-Scene Grasping with Latent Plans
Jul 04, 2021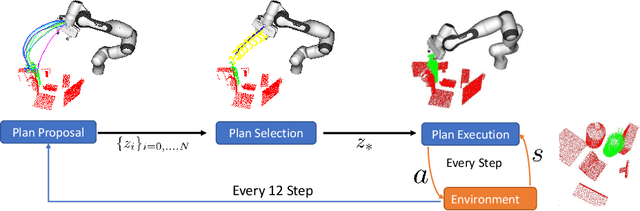

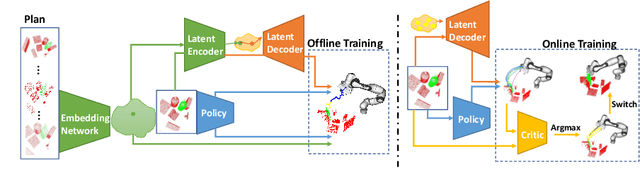
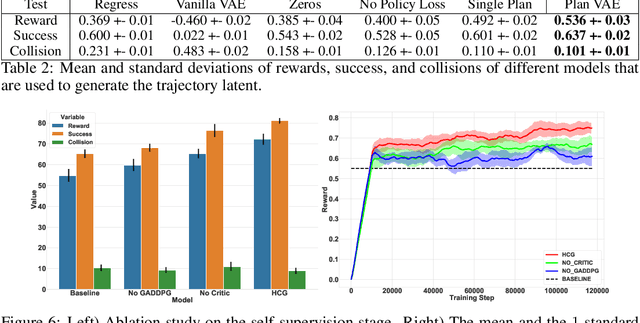
6D grasping in cluttered scenes is a longstanding robotic manipulation problem. Open-loop manipulation pipelines can fail due to modularity and error sensitivity while most end-to-end grasping policies with raw perception inputs have not yet scaled to complex scenes with obstacles. In this work, we propose a new method to close the gap through sampling and selecting plans in the latent space. Our hierarchical framework learns collision-free target-driven grasping based on partial point cloud observations. Our method learns an embedding space to represent expert grasping plans and a variational autoencoder to sample diverse latent plans at inference time. Furthermore, we train a latent plan critic for plan selection and an option classifier for switching to an instance grasping policy through hierarchical reinforcement learning. We evaluate and analyze our method and compare against several baselines in simulation, and demonstrate that the latent planning can generalize to the real-world cluttered-scene grasping task. Our videos and code can be found at https://sites.google.com/view/latent-grasping .
RICE: Refining Instance Masks in Cluttered Environments with Graph Neural Networks
Jun 29, 2021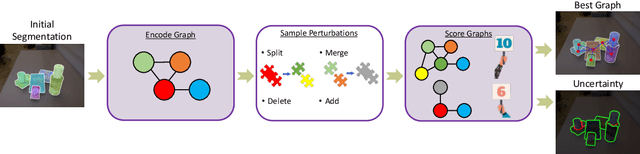

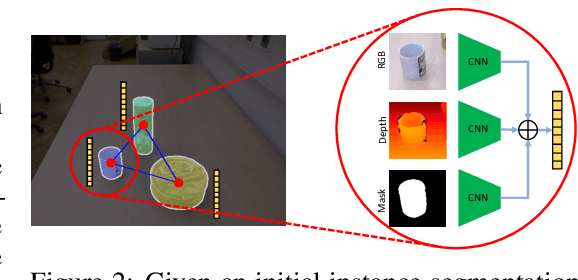
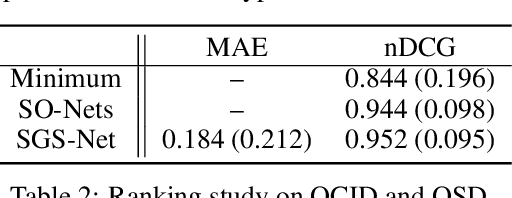
Segmenting unseen object instances in cluttered environments is an important capability that robots need when functioning in unstructured environments. While previous methods have exhibited promising results, they still tend to provide incorrect results in highly cluttered scenes. We postulate that a network architecture that encodes relations between objects at a high-level can be beneficial. Thus, in this work, we propose a novel framework that refines the output of such methods by utilizing a graph-based representation of instance masks. We train deep networks capable of sampling smart perturbations to the segmentations, and a graph neural network, which can encode relations between objects, to evaluate the perturbed segmentations. Our proposed method is orthogonal to previous works and achieves state-of-the-art performance when combined with them. We demonstrate an application that uses uncertainty estimates generated by our method to guide a manipulator, leading to efficient understanding of cluttered scenes. Code, models, and video can be found at https://github.com/chrisdxie/rice .
NeRP: Neural Rearrangement Planning for Unknown Objects
Jun 04, 2021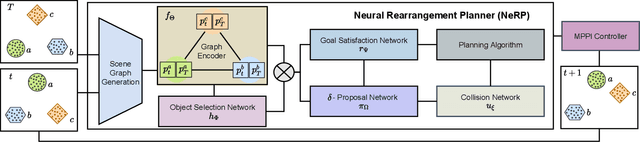



Robots will be expected to manipulate a wide variety of objects in complex and arbitrary ways as they become more widely used in human environments. As such, the rearrangement of objects has been noted to be an important benchmark for AI capabilities in recent years. We propose NeRP (Neural Rearrangement Planning), a deep learning based approach for multi-step neural object rearrangement planning which works with never-before-seen objects, that is trained on simulation data, and generalizes to the real world. We compare NeRP to several naive and model-based baselines, demonstrating that our approach is measurably better and can efficiently arrange unseen objects in fewer steps and with less planning time. Finally, we demonstrate it on several challenging rearrangement problems in the real world.
DiSECt: A Differentiable Simulation Engine for Autonomous Robotic Cutting
May 25, 2021
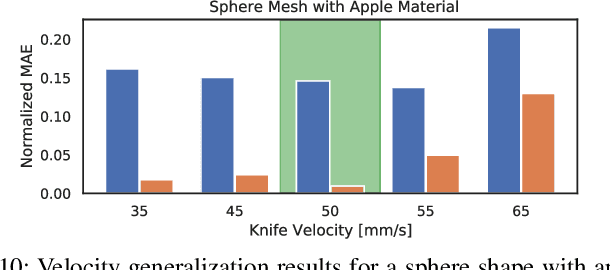
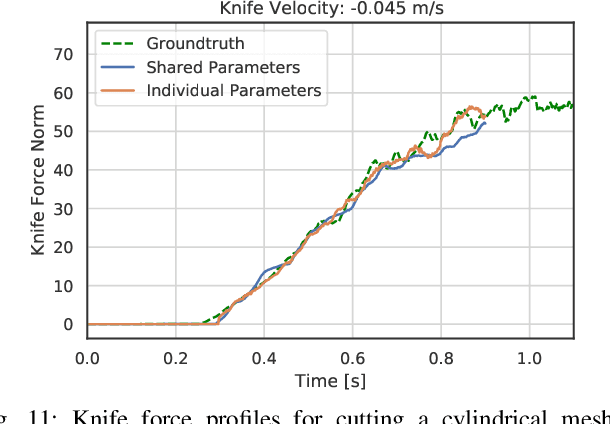
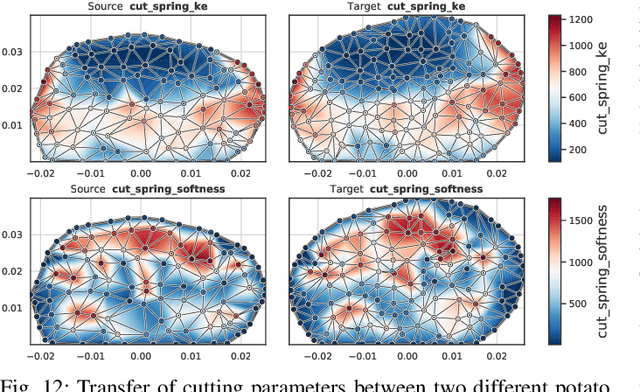
Robotic cutting of soft materials is critical for applications such as food processing, household automation, and surgical manipulation. As in other areas of robotics, simulators can facilitate controller verification, policy learning, and dataset generation. Moreover, differentiable simulators can enable gradient-based optimization, which is invaluable for calibrating simulation parameters and optimizing controllers. In this work, we present DiSECt: the first differentiable simulator for cutting soft materials. The simulator augments the finite element method (FEM) with a continuous contact model based on signed distance fields (SDF), as well as a continuous damage model that inserts springs on opposite sides of the cutting plane and allows them to weaken until zero stiffness, enabling crack formation. Through various experiments, we evaluate the performance of the simulator. We first show that the simulator can be calibrated to match resultant forces and deformation fields from a state-of-the-art commercial solver and real-world cutting datasets, with generality across cutting velocities and object instances. We then show that Bayesian inference can be performed efficiently by leveraging the differentiability of the simulator, estimating posteriors over hundreds of parameters in a fraction of the time of derivative-free methods. Finally, we illustrate that control parameters in the simulation can be optimized to minimize cutting forces via lateral slicing motions. We publish videos and additional results on our project website at https://diff-cutting-sim.github.io.
Robust Value Iteration for Continuous Control Tasks
May 25, 2021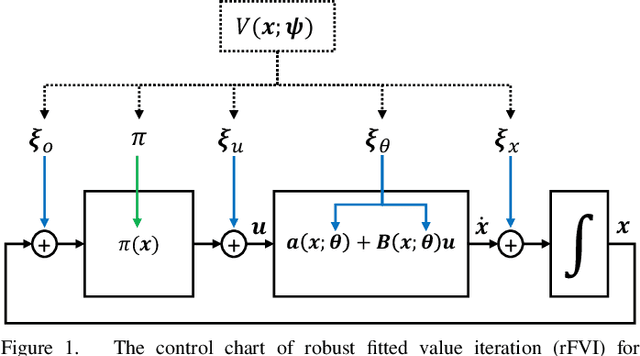

When transferring a control policy from simulation to a physical system, the policy needs to be robust to variations in the dynamics to perform well. Commonly, the optimal policy overfits to the approximate model and the corresponding state-distribution, often resulting in failure to trasnfer underlying distributional shifts. In this paper, we present Robust Fitted Value Iteration, which uses dynamic programming to compute the optimal value function on the compact state domain and incorporates adversarial perturbations of the system dynamics. The adversarial perturbations encourage a optimal policy that is robust to changes in the dynamics. Utilizing the continuous-time perspective of reinforcement learning, we derive the optimal perturbations for the states, actions, observations and model parameters in closed-form. Notably, the resulting algorithm does not require discretization of states or actions. Therefore, the optimal adversarial perturbations can be efficiently incorporated in the min-max value function update. We apply the resulting algorithm to the physical Furuta pendulum and cartpole. By changing the masses of the systems we evaluate the quantitative and qualitative performance across different model parameters. We show that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
Value Iteration in Continuous Actions, States and Time
May 10, 2021
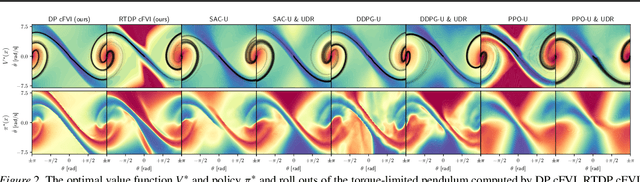
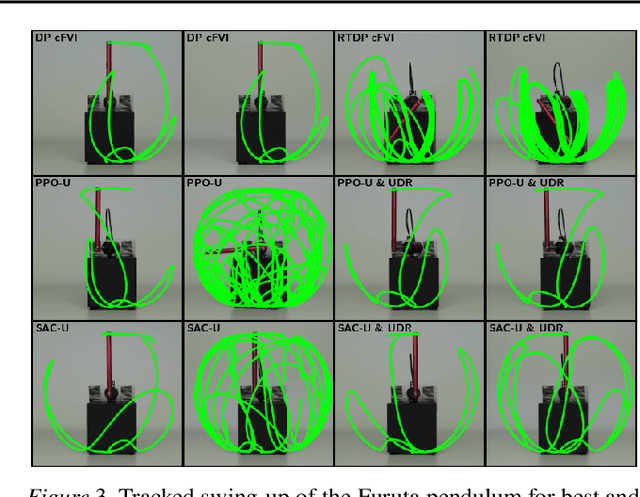
Classical value iteration approaches are not applicable to environments with continuous states and actions. For such environments, the states and actions are usually discretized, which leads to an exponential increase in computational complexity. In this paper, we propose continuous fitted value iteration (cFVI). This algorithm enables dynamic programming for continuous states and actions with a known dynamics model. Leveraging the continuous-time formulation, the optimal policy can be derived for non-linear control-affine dynamics. This closed-form solution enables the efficient extension of value iteration to continuous environments. We show in non-linear control experiments that the dynamic programming solution obtains the same quantitative performance as deep reinforcement learning methods in simulation but excels when transferred to the physical system. The policy obtained by cFVI is more robust to changes in the dynamics despite using only a deterministic model and without explicitly incorporating robustness in the optimization. Videos of the physical system are available at \url{https://sites.google.com/view/value-iteration}.