 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguageRefer: Spatial-Language Model for 3D Visual Grounding
Jul 22, 2021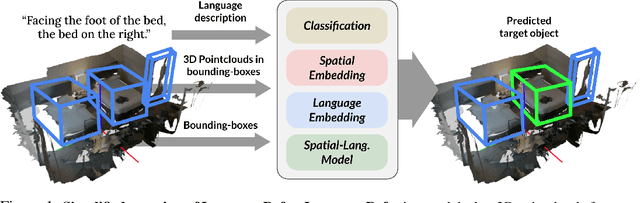
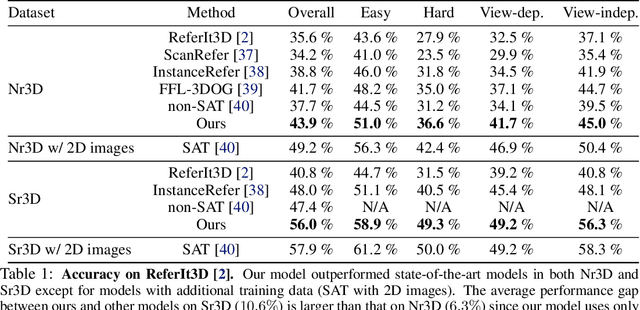
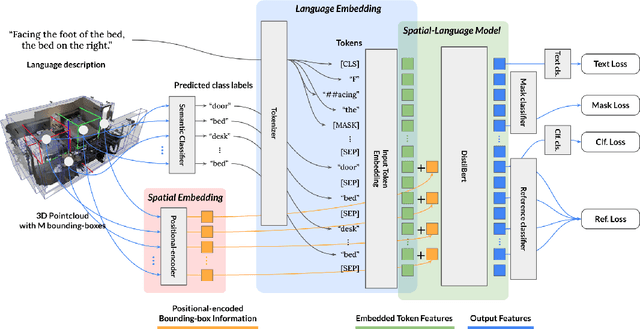
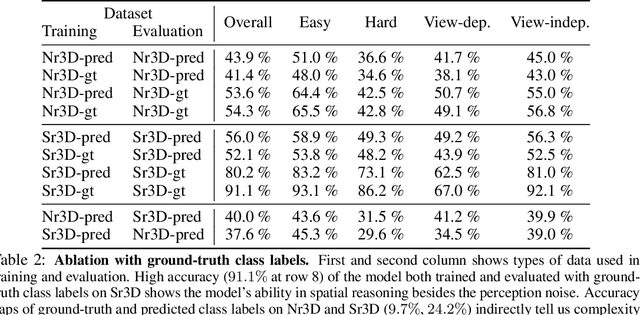
To realize robots that can understand human instructions and perform meaningful tasks in the near future, it is important to develop learned models that can understand referential language to identify common objects in real-world 3D scenes. In this paper, we develop a spatial-language model for a 3D visual grounding problem. Specifically, given a reconstructed 3D scene in the form of a point cloud with 3D bounding boxes of potential object candidates, and a language utterance referring to a target object in the scene, our model identifies the target object from a set of potential candidates. Our spatial-language model uses a transformer-based architecture that combines spatial embedding from bounding-box with a finetuned language embedding from DistilBert and reasons among the objects in the 3D scene to find the target object. We show that our model performs competitively on visio-linguistic datasets proposed by ReferIt3D. We provide additional analysis of performance in spatial reasoning tasks decoupled from perception noise, the effect of view-dependent utterances in terms of accuracy, and view-point annotations for potential robotics applications.
Multimodal Trajectory Prediction via Topological Invariance for Navigation at Uncontrolled Intersections
Nov 08, 2020
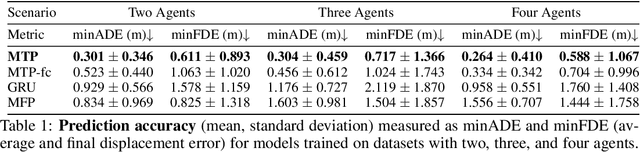
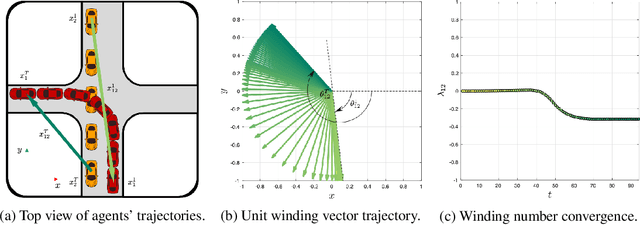
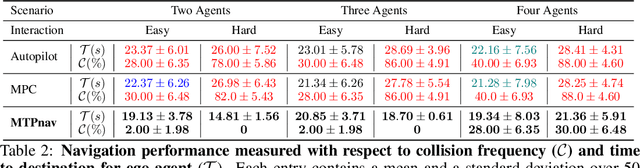
We focus on decentralized navigation among multiple non-communicating rational agents at \emph{uncontrolled} intersections, i.e., street intersections without traffic signs or signals. Avoiding collisions in such domains relies on the ability of agents to predict each others' intentions reliably, and react quickly. Multiagent trajectory prediction is NP-hard whereas the sample complexity of existing data-driven approaches limits their applicability. Our key insight is that the geometric structure of the intersection and the incentive of agents to move efficiently and avoid collisions (rationality) reduces the space of likely behaviors, effectively relaxing the problem of trajectory prediction. In this paper, we collapse the space of multiagent trajectories at an intersection into a set of modes representing different classes of multiagent behavior, formalized using a notion of topological invariance. Based on this formalism, we design Multiple Topologies Prediction (MTP), a data-driven trajectory-prediction mechanism that reconstructs trajectory representations of high-likelihood modes in multiagent intersection scenes. We show that MTP outperforms a state-of-the-art multimodal trajectory prediction baseline (MFP) in terms of prediction accuracy by 78.24% on a challenging simulated dataset. Finally, we show that MTP enables our optimization-based planner, MTPnav, to achieve collision-free and time-efficient navigation across a variety of challenging intersection scenarios on the CARLA simulator.
Conditional Driving from Natural Language Instructions
Oct 16, 2019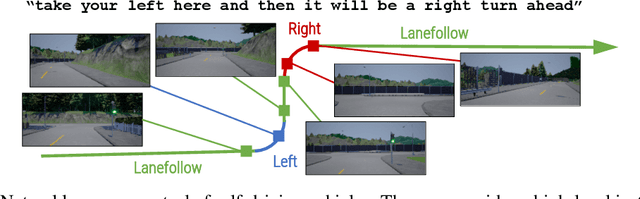
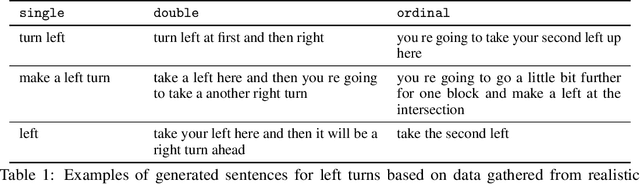
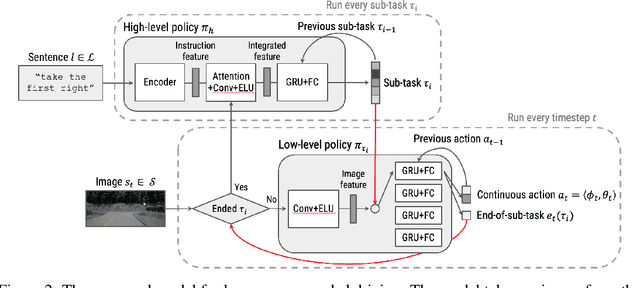
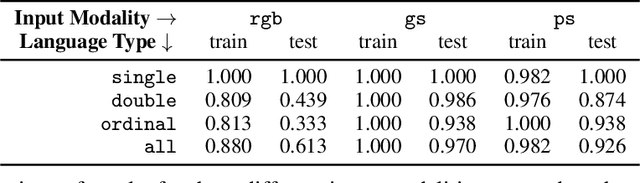
Widespread adoption of self-driving cars will depend not only on their safety but largely on their ability to interact with human users. Just like human drivers, self-driving cars will be expected to understand and safely follow natural-language directions that suddenly alter the pre-planned route according to user's preference or in presence of ambiguities, particularly in locations with poor or outdated map coverage. To this end, we propose a language-grounded driving agent implementing a hierarchical policy using recurrent layers and gated attention. The hierarchical approach enables us to reason both in terms of high-level language instructions describing long time horizons and low-level, complex, continuous state/action spaces required for real-time control of a self-driving car. We train our policy with conditional imitation learning from realistic language data collected from human drivers and navigators. Through quantitative and interactive experiments within the CARLA framework, we show that our model can successfully interpret language instructions and follow them safely, even when generalizing to previously unseen environments. Code and video are available at https://sites.google.com/view/language-grounded-driving.