 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Graphormer on Large-Scale Molecular Modeling Datasets
Mar 14, 2022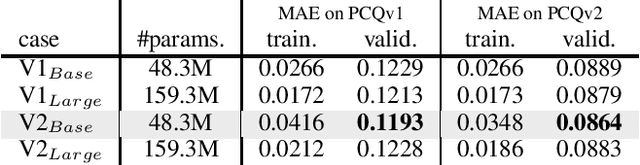
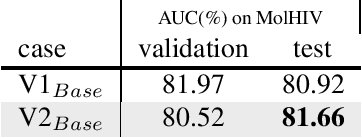
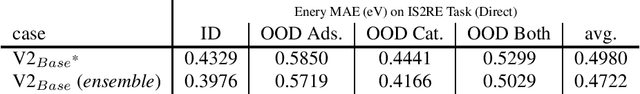

This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. The "Graphormer-V2" could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on downstream tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Graphormer-V2 achieves much less MAE than the vanilla Graphormer on the PCQM4M quantum chemistry dataset used in KDD Cup 2021, where the latter one won the first place in this competition. In the meanwhile, Graphormer-V2 greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All models could be found at \url{https://github.com/Microsoft/Graphormer}.
Benchmarking Graphormer on Large-Scale Molecular Modeling Datasets
Mar 09, 2022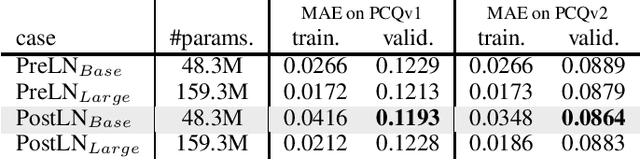
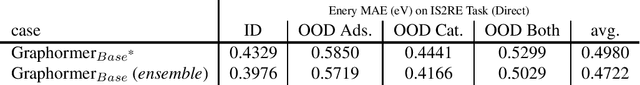
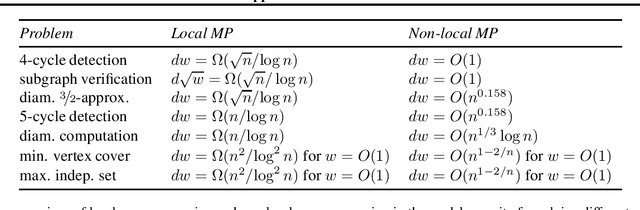
This technical note describes the recent updates of Graphormer, including architecture design modifications, and the adaption to 3D molecular dynamics simulation. With these simple modifications, Graphormer could attain better results on large-scale molecular modeling datasets than the vanilla one, and the performance gain could be consistently obtained on 2D and 3D molecular graph modeling tasks. In addition, we show that with a global receptive field and an adaptive aggregation strategy, Graphormer is more powerful than classic message-passing-based GNNs. Empirically, Graphormer could achieve much less MAE than the originally reported results on the PCQM4M quantum chemistry dataset used in KDD Cup 2021. In the meanwhile, it greatly outperforms the competitors in the recent Open Catalyst Challenge, which is a competition track on NeurIPS 2021 workshop, and aims to model the catalyst-adsorbate reaction system with advanced AI models. All codes could be found at https://github.com/Microsoft/Graphormer.
VADOI:Voice-Activity-Detection Overlapping Inference For End-to-end Long-form Speech Recognition
Feb 22, 2022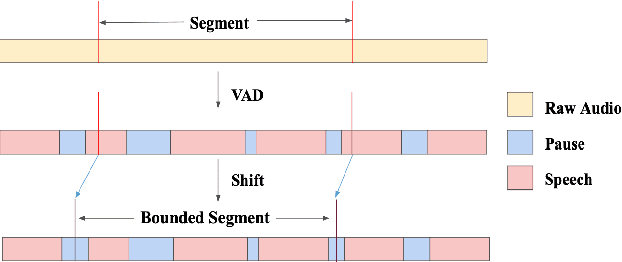

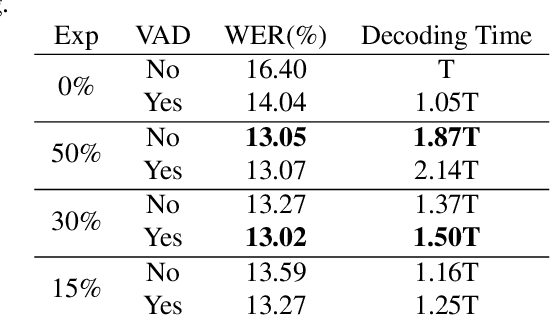
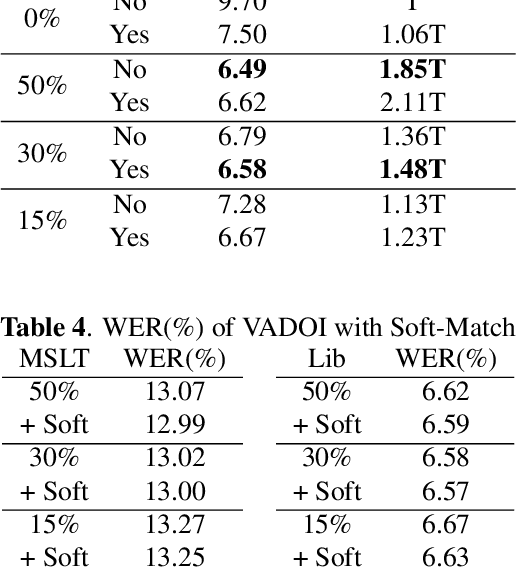
While end-to-end models have shown great success on the Automatic Speech Recognition task, performance degrades severely when target sentences are long-form. The previous proposed methods, (partial) overlapping inference are shown to be effective on long-form decoding. For both methods, word error rate (WER) decreases monotonically when overlapping percentage decreases. Setting aside computational cost, the setup with 50% overlapping during inference can achieve the best performance. However, a lower overlapping percentage has an advantage of fast inference speed. In this paper, we first conduct comprehensive experiments comparing overlapping inference and partial overlapping inference with various configurations. We then propose Voice-Activity-Detection Overlapping Inference to provide a trade-off between WER and computation cost. Results show that the proposed method can achieve a 20% relative computation cost reduction on Librispeech and Microsoft Speech Language Translation long-form corpus while maintaining the WER performance when comparing to the best performing overlapping inference algorithm. We also propose Soft-Match to compensate for similar words mis-aligned problem.
Learning Physics-Informed Neural Networks without Stacked Back-propagation
Feb 18, 2022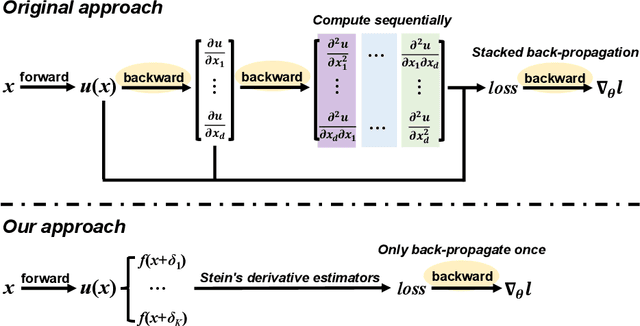
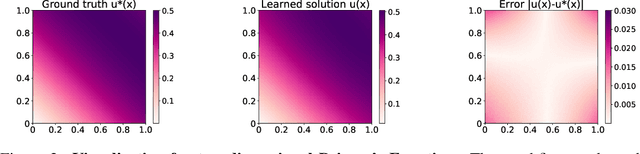
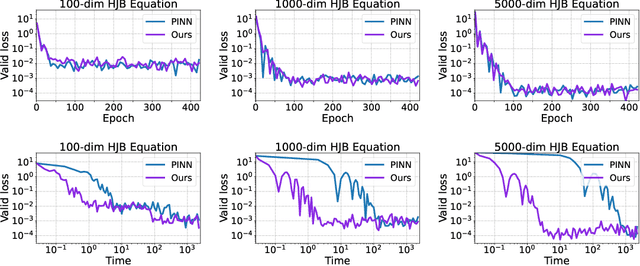
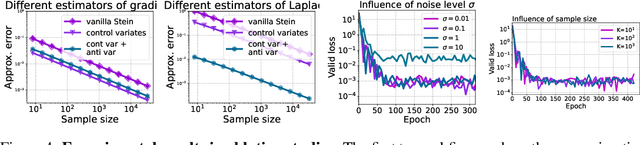
Physics-Informed Neural Network (PINN) has become a commonly used machine learning approach to solve partial differential equations (PDE). But, facing high-dimensional second-order PDE problems, PINN will suffer from severe scalability issues since its loss includes second-order derivatives, the computational cost of which will grow along with the dimension during stacked back-propagation. In this paper, we develop a novel approach that can significantly accelerate the training of Physics-Informed Neural Networks. In particular, we parameterize the PDE solution by the Gaussian smoothed model and show that, derived from Stein's Identity, the second-order derivatives can be efficiently calculated without back-propagation. We further discuss the model capacity and provide variance reduction methods to address key limitations in the derivative estimation. Experimental results show that our proposed method can achieve competitive error compared to standard PINN training but is two orders of magnitude faster.
HousE: Knowledge Graph Embedding with Householder Parameterization
Feb 16, 2022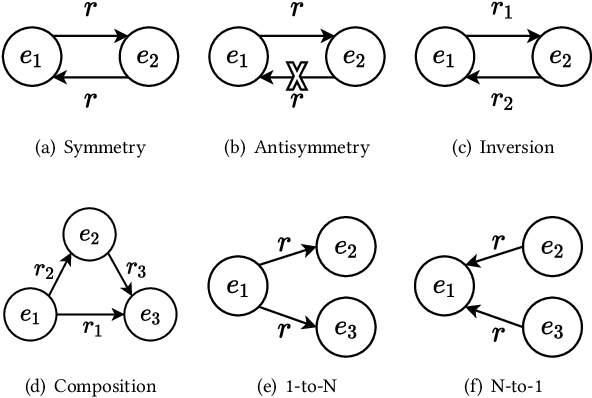
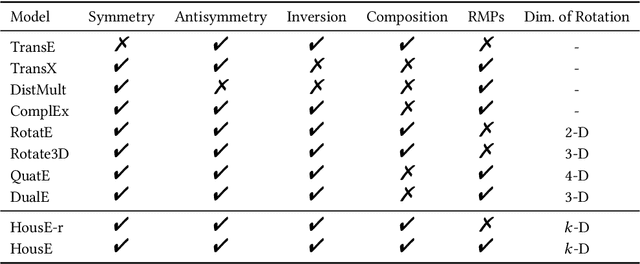
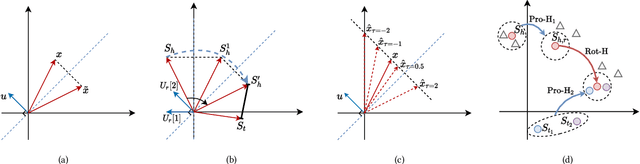
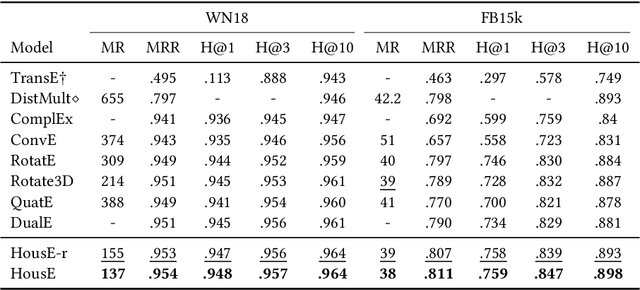
The effectiveness of knowledge graph embedding (KGE) largely depends on the ability to model intrinsic relation patterns and mapping properties. However, existing approaches can only capture some of them with insufficient modeling capacity. In this work, we propose a more powerful KGE framework named HousE, which involves a novel parameterization based on two kinds of Householder transformations: (1) Householder rotations to achieve superior capacity of modeling relation patterns; (2) Householder projections to handle sophisticated relation mapping properties. Theoretically, HousE is capable of modeling crucial relation patterns and mapping properties simultaneously. Besides, HousE is a generalization of existing rotation-based models while extending the rotations to high-dimensional spaces. Empirically, HousE achieves new state-of-the-art performance on five benchmark datasets. Our code is available at https://github.com/anrep/HousE.
Exploration of Dark Chemical Genomics Space via Portal Learning: Applied to Targeting the Undruggable Genome and COVID-19 Anti-Infective Polypharmacology
Nov 23, 2021
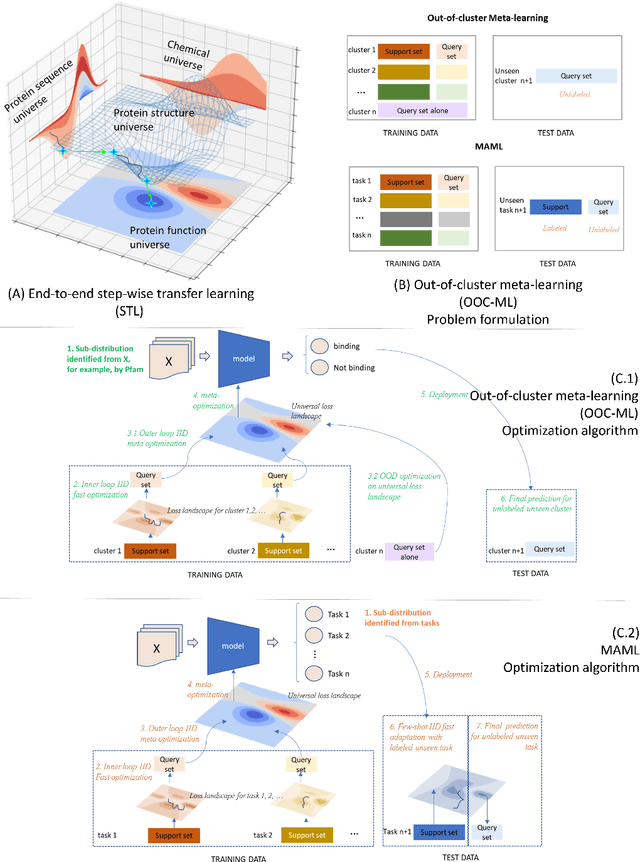

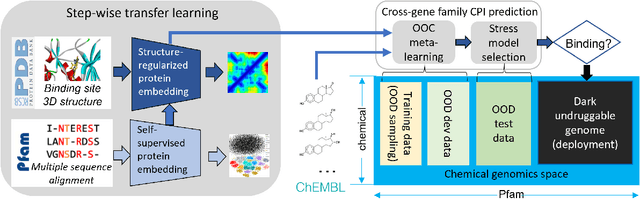
Advances in biomedicine are largely fueled by exploring uncharted territories of human biology. Machine learning can both enable and accelerate discovery, but faces a fundamental hurdle when applied to unseen data with distributions that differ from previously observed ones -- a common dilemma in scientific inquiry. We have developed a new deep learning framework, called {\textit{Portal Learning}}, to explore dark chemical and biological space. Three key, novel components of our approach include: (i) end-to-end, step-wise transfer learning, in recognition of biology's sequence-structure-function paradigm, (ii) out-of-cluster meta-learning, and (iii) stress model selection. Portal Learning provides a practical solution to the out-of-distribution (OOD) problem in statistical machine learning. Here, we have implemented Portal Learning to predict chemical-protein interactions on a genome-wide scale. Systematic studies demonstrate that Portal Learning can effectively assign ligands to unexplored gene families (unknown functions), versus existing state-of-the-art methods, thereby allowing us to target previously "undruggable" proteins and design novel polypharmacological agents for disrupting interactions between SARS-CoV-2 and human proteins. Portal Learning is general-purpose and can be further applied to other areas of scientific inquiry.
Can Vision Transformers Perform Convolution?
Nov 03, 2021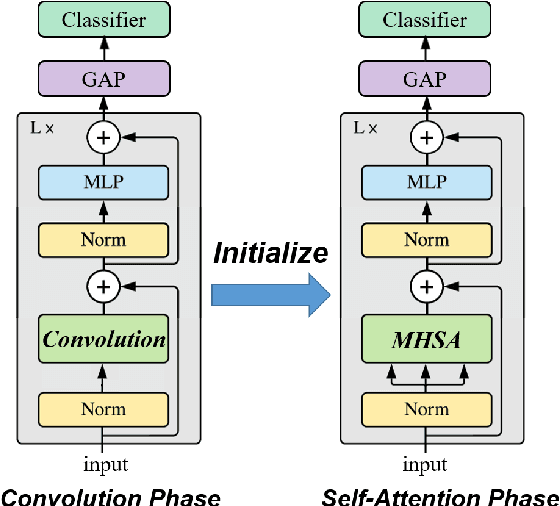
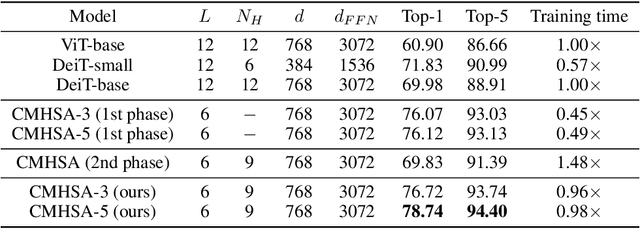
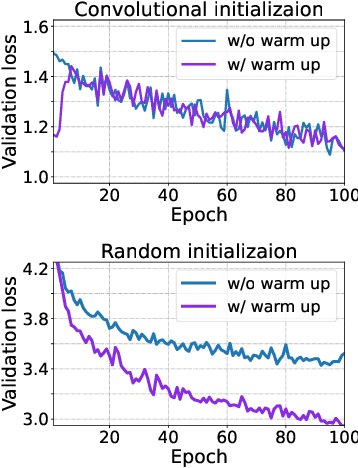
Several recent studies have demonstrated that attention-based networks, such as Vision Transformer (ViT), can outperform Convolutional Neural Networks (CNNs) on several computer vision tasks without using convolutional layers. This naturally leads to the following questions: Can a self-attention layer of ViT express any convolution operation? In this work, we prove that a single ViT layer with image patches as the input can perform any convolution operation constructively, where the multi-head attention mechanism and the relative positional encoding play essential roles. We further provide a lower bound on the number of heads for Vision Transformers to express CNNs. Corresponding with our analysis, experimental results show that the construction in our proof can help inject convolutional bias into Transformers and significantly improve the performance of ViT in low data regimes.
Boosting the Certified Robustness of L-infinity Distance Nets
Oct 13, 2021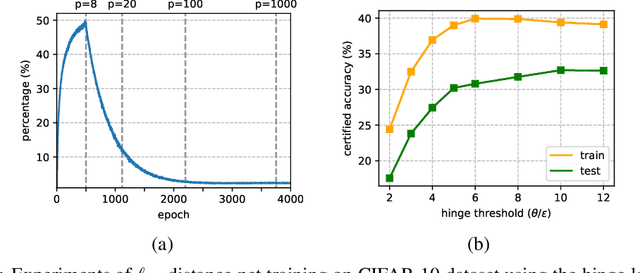
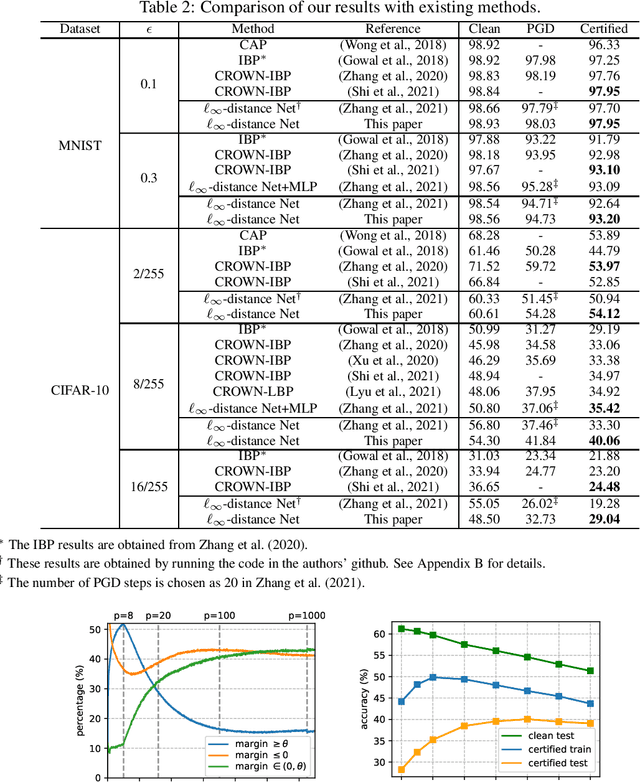
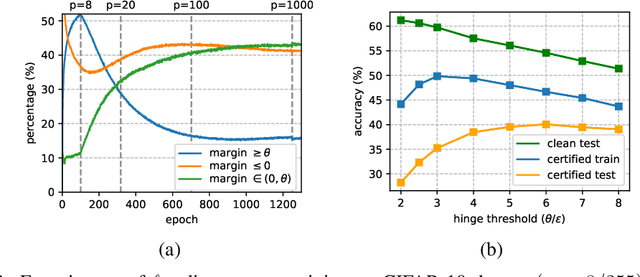

Recently, Zhang et al. (2021) developed a new neural network architecture based on $\ell_\infty$-distance functions, which naturally possesses certified robustness by its construction. Despite the excellent theoretical properties, the model so far can only achieve comparable performance to conventional networks. In this paper, we significantly boost the certified robustness of $\ell_\infty$-distance nets through a careful analysis of its training process. In particular, we show the $\ell_p$-relaxation, a crucial way to overcome the non-smoothness of the model, leads to an unexpected large Lipschitz constant at the early training stage. This makes the optimization insufficient using hinge loss and produces sub-optimal solutions. Given these findings, we propose a simple approach to address the issues above by using a novel objective function that combines a scaled cross-entropy loss with clipped hinge loss. Our experiments show that using the proposed training strategy, the certified accuracy of $\ell_\infty$-distance net can be dramatically improved from 33.30% to 40.06% on CIFAR-10 ($\epsilon=8/255$), meanwhile significantly outperforming other approaches in this area. Such a result clearly demonstrates the effectiveness and potential of $\ell_\infty$-distance net for certified robustness.
Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
Jun 23, 2021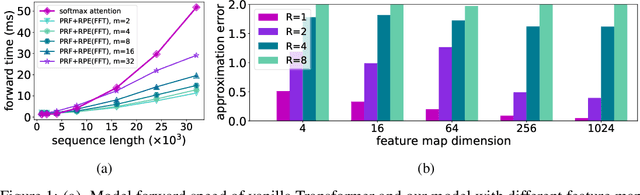
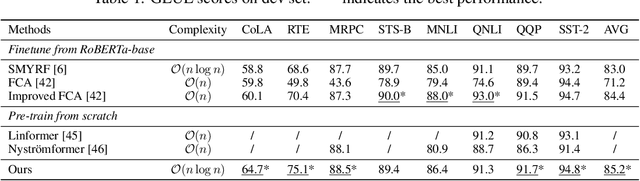


The attention module, which is a crucial component in Transformer, cannot scale efficiently to long sequences due to its quadratic complexity. Many works focus on approximating the dot-then-exponentiate softmax function in the original attention, leading to sub-quadratic or even linear-complexity Transformer architectures. However, we show that these methods cannot be applied to more powerful attention modules that go beyond the dot-then-exponentiate style, e.g., Transformers with relative positional encoding (RPE). Since in many state-of-the-art models, relative positional encoding is used as default, designing efficient Transformers that can incorporate RPE is appealing. In this paper, we propose a novel way to accelerate attention calculation for Transformers with RPE on top of the kernelized attention. Based upon the observation that relative positional encoding forms a Toeplitz matrix, we mathematically show that kernelized attention with RPE can be calculated efficiently using Fast Fourier Transform (FFT). With FFT, our method achieves $\mathcal{O}(n\log n)$ time complexity. Interestingly, we further demonstrate that properly using relative positional encoding can mitigate the training instability problem of vanilla kernelized attention. On a wide range of tasks, we empirically show that our models can be trained from scratch without any optimization issues. The learned model performs better than many efficient Transformer variants and is faster than standard Transformer in the long-sequence regime.
First Place Solution of KDD Cup 2021 & OGB Large-Scale Challenge Graph Prediction Track
Jun 20, 2021

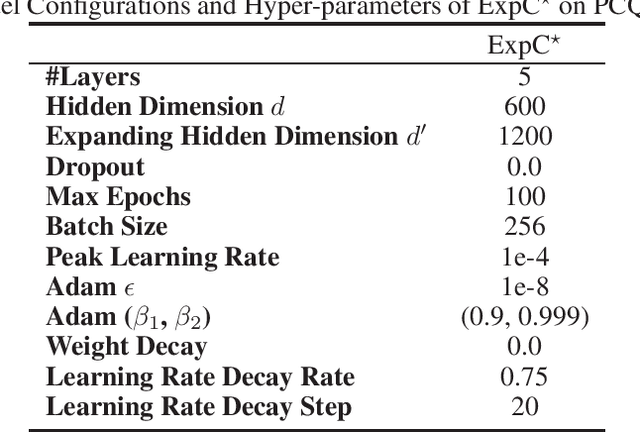
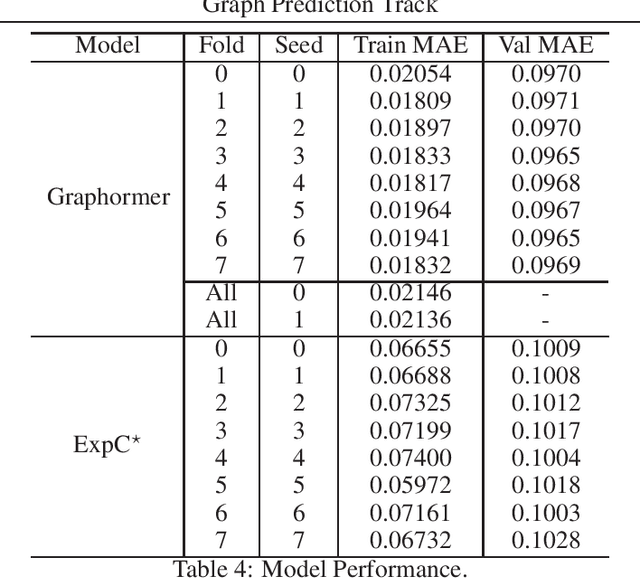
In this technical report, we present our solution of KDD Cup 2021 OGB Large-Scale Challenge - PCQM4M-LSC Track. We adopt Graphormer and ExpC as our basic models. We train each model by 8-fold cross-validation, and additionally train two Graphormer models on the union of training and validation sets with different random seeds. For final submission, we use a naive ensemble for these 18 models by taking average of their outputs. Using our method, our team MachineLearning achieved 0.1200 MAE on test set, which won the first place in KDD Cup graph prediction track.