 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deeper Understanding of Camouflaged Object Detection
May 23, 2022
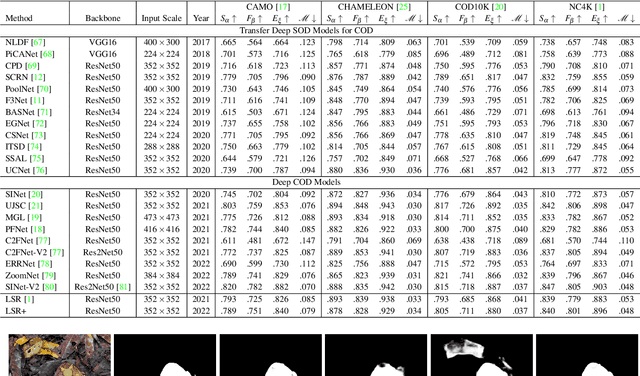
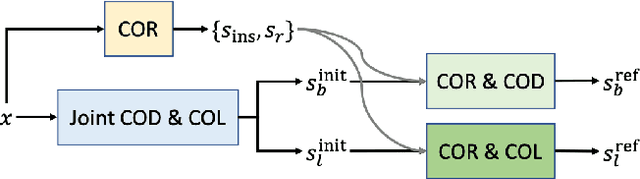
Preys in the wild evolve to be camouflaged to avoid being recognized by predators. In this way, camouflage acts as a key defence mechanism across species that is critical to survival. To detect and segment the whole scope of a camouflaged object, camouflaged object detection (COD) is introduced as a binary segmentation task, with the binary ground truth camouflage map indicating the exact regions of the camouflaged objects. In this paper, we revisit this task and argue that the binary segmentation setting fails to fully understand the concept of camouflage. We find that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage, but also provide guidance to designing more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first triple-task learning framework to simultaneously localize, segment and rank camouflaged objects, indicating the conspicuousness level of camouflage. As no corresponding datasets exist for either the localization model or the ranking model, we generate localization maps with an eye tracker, which are then processed according to the instance level labels to generate our ranking-based training and testing dataset. We also contribute the largest COD testing set to comprehensively analyse performance of the camouflaged object detection models. Experimental results show that our triple-task learning framework achieves new state-of-the-art, leading to a more explainable camouflaged object detection network. Our code, data and results are available at: https://github.com/JingZhang617/COD-Rank-Localize-and-Segment.
Video Polyp Segmentation: A Deep Learning Perspective
Mar 27, 2022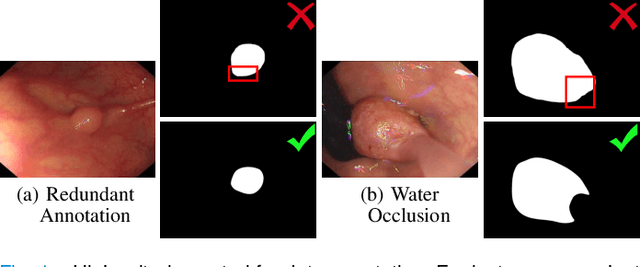
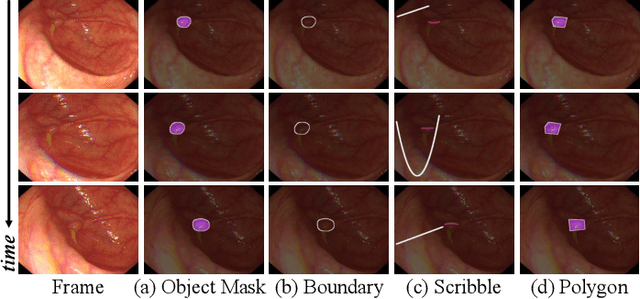
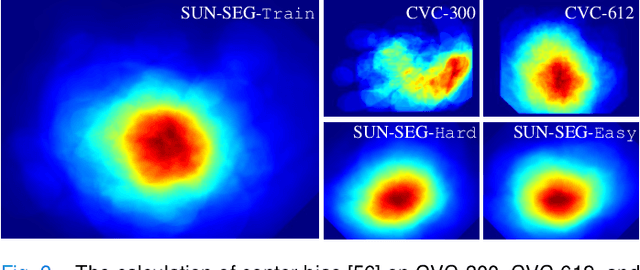
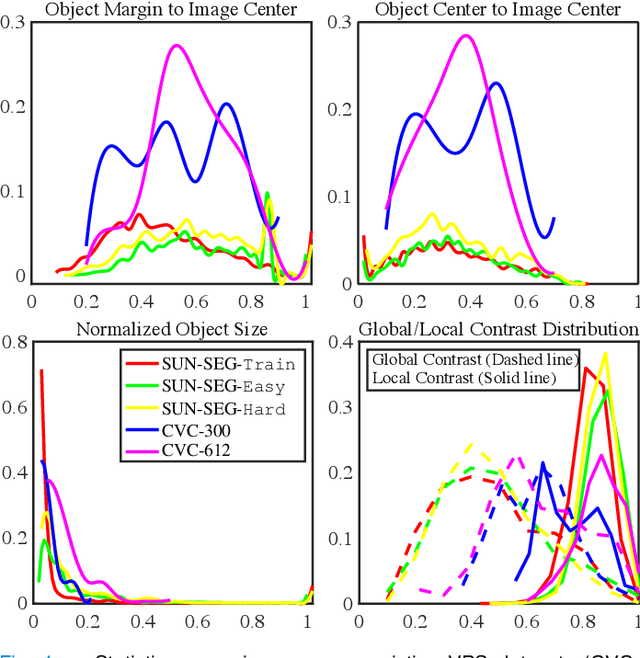
In the deep learning era, we present the first comprehensive video polyp segmentation (VPS) study. Over the years, developments in VPS are not moving forward with ease due to the lack of large-scale fine-grained segmentation annotations. To tackle this issue, we first introduce a high-quality per-frame annotated VPS dataset, named SUN-SEG, which includes 158,690 frames from the famous SUN dataset. We provide additional annotations with diverse types, i.e., attribute, object mask, boundary, scribble, and polygon. Second, we design a simple but efficient baseline, dubbed PNS+, consisting of a global encoder, a local encoder, and normalized self-attention (NS) blocks. The global and local encoders receive an anchor frame and multiple successive frames to extract long-term and short-term feature representations, which are then progressively updated by two NS blocks. Extensive experiments show that PNS+ achieves the best performance and real-time inference speed (170fps), making it a promising solution for the VPS task. Third, we extensively evaluate 13 representative polyp/object segmentation models on our SUN-SEG dataset and provide attribute-based comparisons. Benchmark results are available at https: //github.com/GewelsJI/VPS.
High-resolution Iterative Feedback Network for Camouflaged Object Detection
Mar 22, 2022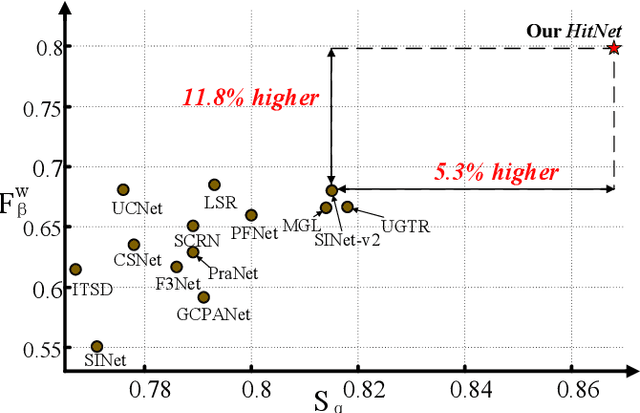



Spotting camouflaged objects that are visually assimilated into the background is tricky for both object detection algorithms and humans who are usually confused or cheated by the perfectly intrinsic similarities between the foreground objects and the background surroundings. To tackle this challenge, we aim to extract the high-resolution texture details to avoid the detail degradation that causes blurred vision in edges and boundaries. We introduce a novel HitNet to refine the low-resolution representations by high-resolution features in an iterative feedback manner, essentially a global loop-based connection among the multi-scale resolutions. In addition, an iterative feedback loss is proposed to impose more constraints on each feedback connection. Extensive experiments on four challenging datasets demonstrate that our \ourmodel~breaks the performance bottleneck and achieves significant improvements compared with 29 state-of-the-art methods. To address the data scarcity in camouflaged scenarios, we provide an application example by employing cross-domain learning to extract the features that can reflect the camouflaged object properties and embed the features into salient objects, thereby generating more camouflaged training samples from the diverse salient object datasets The code will be available at https://github.com/HUuxiaobin/HitNet.
Implicit Motion Handling for Video Camouflaged Object Detection
Mar 15, 2022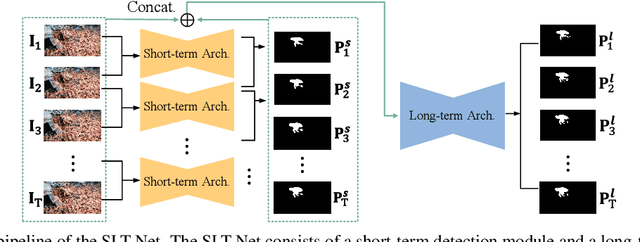
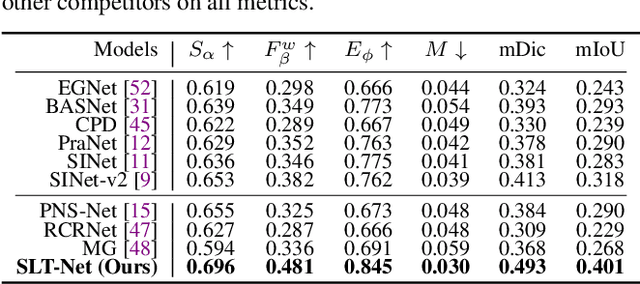
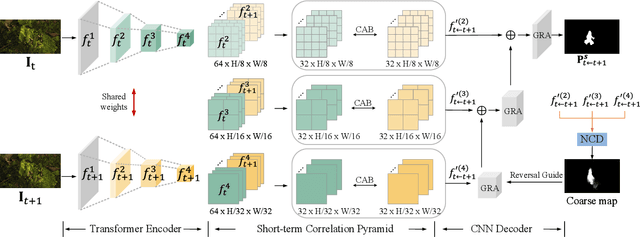

We propose a new video camouflaged object detection (VCOD) framework that can exploit both short-term dynamics and long-term temporal consistency to detect camouflaged objects from video frames. An essential property of camouflaged objects is that they usually exhibit patterns similar to the background and thus make them hard to identify from still images. Therefore, effectively handling temporal dynamics in videos becomes the key for the VCOD task as the camouflaged objects will be noticeable when they move. However, current VCOD methods often leverage homography or optical flows to represent motions, where the detection error may accumulate from both the motion estimation error and the segmentation error. On the other hand, our method unifies motion estimation and object segmentation within a single optimization framework. Specifically, we build a dense correlation volume to implicitly capture motions between neighbouring frames and utilize the final segmentation supervision to optimize the implicit motion estimation and segmentation jointly. Furthermore, to enforce temporal consistency within a video sequence, we jointly utilize a spatio-temporal transformer to refine the short-term predictions. Extensive experiments on VCOD benchmarks demonstrate the architectural effectiveness of our approach. We also provide a large-scale VCOD dataset named MoCA-Mask with pixel-level handcrafted ground-truth masks and construct a comprehensive VCOD benchmark with previous methods to facilitate research in this direction. Dataset Link: https://xueliancheng.github.io/SLT-Net-project.
Highly Accurate Dichotomous Image Segmentation
Mar 08, 2022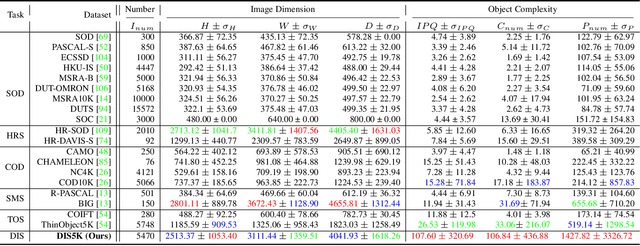
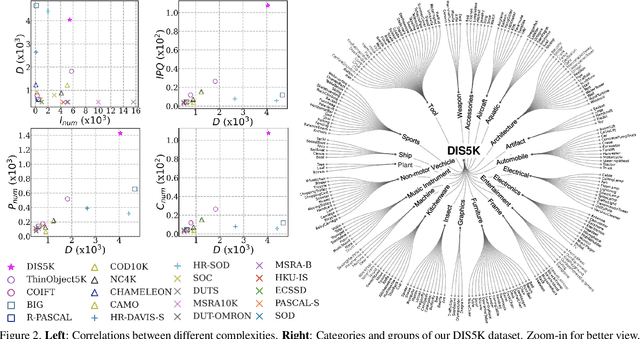
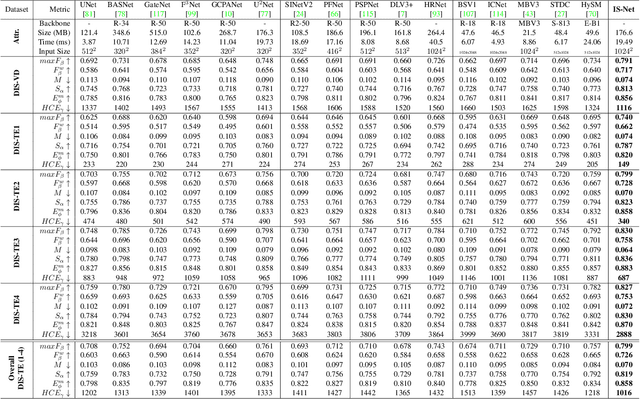

We present a systematic study on a new task called dichotomous image segmentation (DIS), which aims to segment highly accurate objects from natural images. To this end, we collected the first large-scale dataset, called DIS5K, which contains 5,470 high-resolution (e.g., 2K, 4K or larger) images covering camouflaged, salient, or meticulous objects in various backgrounds. All images are annotated with extremely fine-grained labels. In addition, we introduce a simple intermediate supervision baseline (IS-Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms various cutting-edge baselines on the proposed DIS5K, making it a general self-learned supervision network that can help facilitate future research in DIS. Further, we design a new metric called human correction efforts (HCE) which approximates the number of mouse clicking operations required to correct the false positives and false negatives. HCE is utilized to measure the gap between models and real-world applications and thus can complement existing metrics. Finally, we conduct the largest-scale benchmark, evaluating 16 representative segmentation models, providing a more insightful discussion regarding object complexities, and showing several potential applications (e.g., background removal, art design, 3D reconstruction). Hoping these efforts can open up promising directions for both academic and industries. We will release our DIS5K dataset, IS-Net baseline, HCE metric, and the complete benchmark results.
Deep Facial Synthesis: A New Challenge
Jan 07, 2022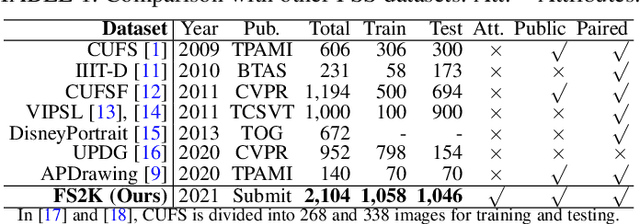


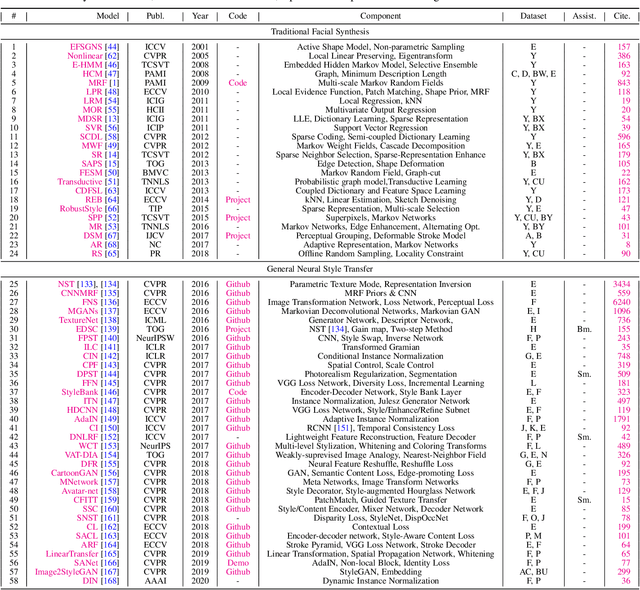
The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
Weakly Supervised Visual-Auditory Saliency Detection with Multigranularity Perception
Jan 01, 2022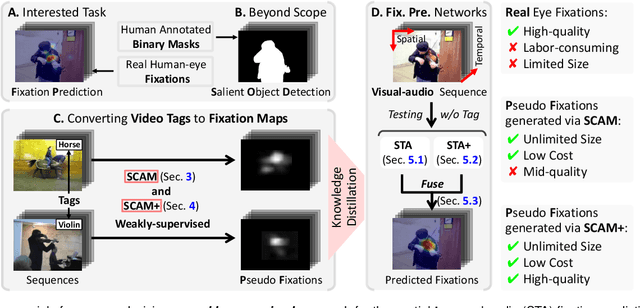
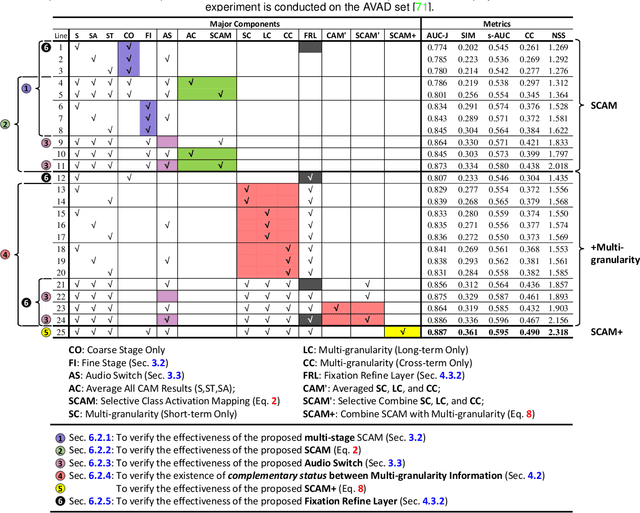
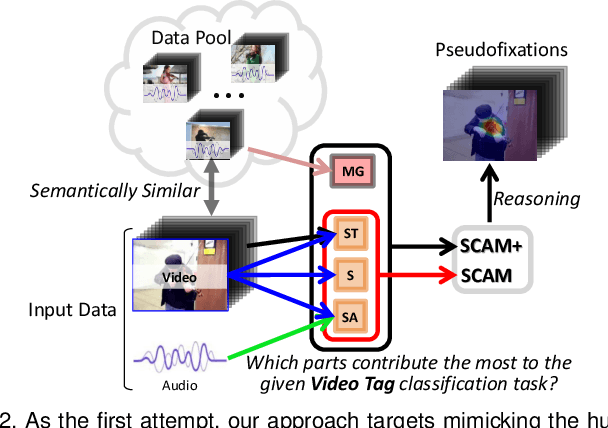
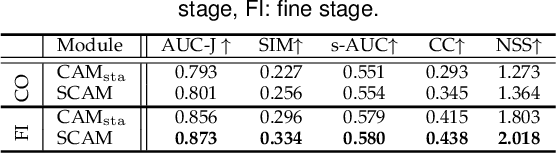
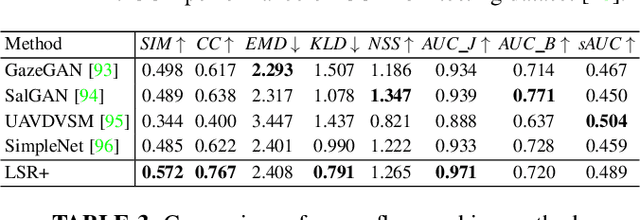
Thanks to the rapid advances in deep learning techniques and the wide availability of large-scale training sets, the performance of video saliency detection models has been improving steadily and significantly. However, deep learning-based visualaudio fixation prediction is still in its infancy. At present, only a few visual-audio sequences have been furnished, with real fixations being recorded in real visual-audio environments. Hence, it would be neither efficient nor necessary to recollect real fixations under the same visual-audio circumstances. To address this problem, this paper promotes a novel approach in a weakly supervised manner to alleviate the demand of large-scale training sets for visual-audio model training. By using only the video category tags, we propose the selective class activation mapping (SCAM) and its upgrade (SCAM+). In the spatial-temporal-audio circumstance, the former follows a coarse-to-fine strategy to select the most discriminative regions, and these regions are usually capable of exhibiting high consistency with the real human-eye fixations. The latter equips the SCAM with an additional multi-granularity perception mechanism, making the whole process more consistent with that of the real human visual system. Moreover, we distill knowledge from these regions to obtain complete new spatial-temporal-audio (STA) fixation prediction (FP) networks, enabling broad applications in cases where video tags are not available. Without resorting to any real human-eye fixation, the performances of these STA FP networks are comparable to those of fully supervised networks. The code and results are publicly available at https://github.com/guotaowang/STANet.
Dense Uncertainty Estimation
Oct 13, 2021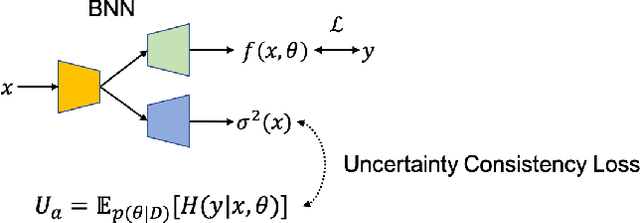
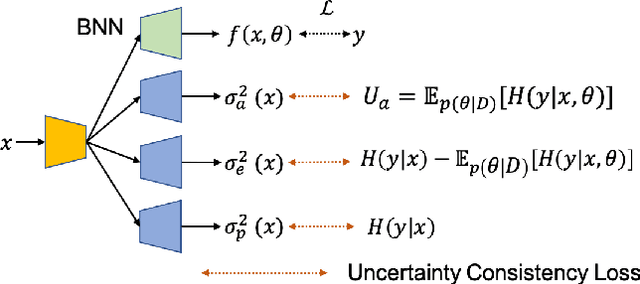
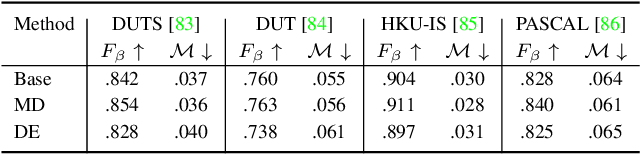
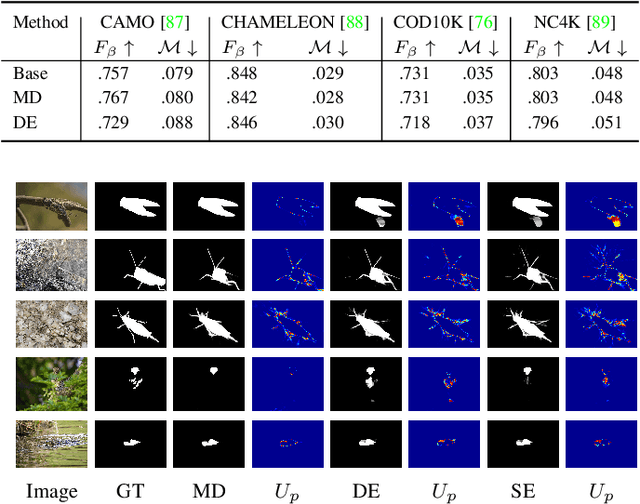
Deep neural networks can be roughly divided into deterministic neural networks and stochastic neural networks.The former is usually trained to achieve a mapping from input space to output space via maximum likelihood estimation for the weights, which leads to deterministic predictions during testing. In this way, a specific weights set is estimated while ignoring any uncertainty that may occur in the proper weight space. The latter introduces randomness into the framework, either by assuming a prior distribution over model parameters (i.e. Bayesian Neural Networks) or including latent variables (i.e. generative models) to explore the contribution of latent variables for model predictions, leading to stochastic predictions during testing. Different from the former that achieves point estimation, the latter aims to estimate the prediction distribution, making it possible to estimate uncertainty, representing model ignorance about its predictions. We claim that conventional deterministic neural network based dense prediction tasks are prone to overfitting, leading to over-confident predictions, which is undesirable for decision making. In this paper, we investigate stochastic neural networks and uncertainty estimation techniques to achieve both accurate deterministic prediction and reliable uncertainty estimation. Specifically, we work on two types of uncertainty estimations solutions, namely ensemble based methods and generative model based methods, and explain their pros and cons while using them in fully/semi/weakly-supervised framework. Due to the close connection between uncertainty estimation and model calibration, we also introduce how uncertainty estimation can be used for deep model calibration to achieve well-calibrated models, namely dense model calibration. Code and data are available at https://github.com/JingZhang617/UncertaintyEstimation.
RGB-D Saliency Detection via Cascaded Mutual Information Minimization
Sep 15, 2021

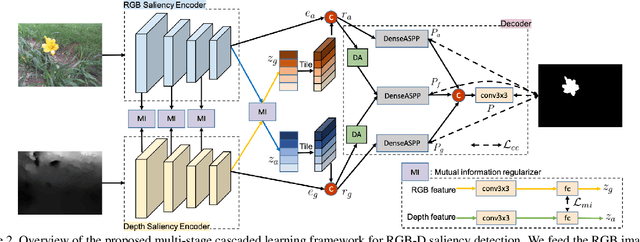
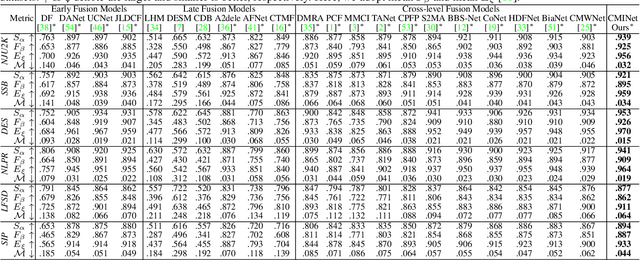
Existing RGB-D saliency detection models do not explicitly encourage RGB and depth to achieve effective multi-modal learning. In this paper, we introduce a novel multi-stage cascaded learning framework via mutual information minimization to "explicitly" model the multi-modal information between RGB image and depth data. Specifically, we first map the feature of each mode to a lower dimensional feature vector, and adopt mutual information minimization as a regularizer to reduce the redundancy between appearance features from RGB and geometric features from depth. We then perform multi-stage cascaded learning to impose the mutual information minimization constraint at every stage of the network. Extensive experiments on benchmark RGB-D saliency datasets illustrate the effectiveness of our framework. Further, to prosper the development of this field, we contribute the largest (7x larger than NJU2K) dataset, which contains 15,625 image pairs with high quality polygon-/scribble-/object-/instance-/rank-level annotations. Based on these rich labels, we additionally construct four new benchmarks with strong baselines and observe some interesting phenomena, which can motivate future model design. Source code and dataset are available at "https://github.com/JingZhang617/cascaded_rgbd_sod".
Full-Duplex Strategy for Video Object Segmentation
Sep 03, 2021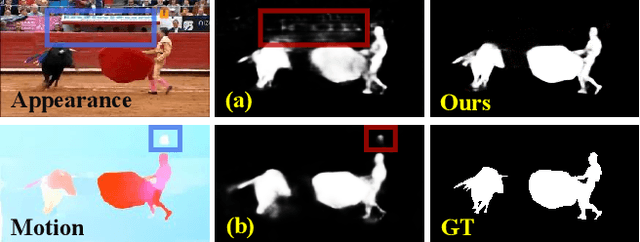

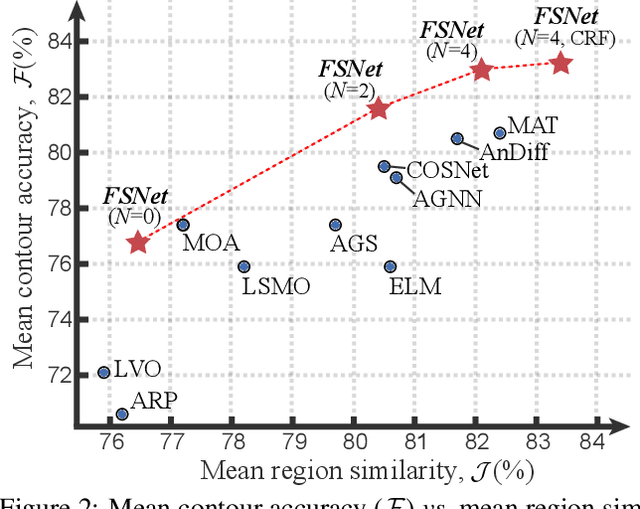
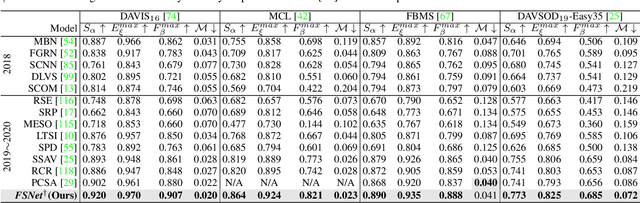
Previous video object segmentation approaches mainly focus on using simplex solutions between appearance and motion, limiting feature collaboration efficiency among and across these two cues. In this work, we study a novel and efficient full-duplex strategy network (FSNet) to address this issue, by considering a better mutual restraint scheme between motion and appearance in exploiting the cross-modal features from the fusion and decoding stage. Specifically, we introduce the relational cross-attention module (RCAM) to achieve bidirectional message propagation across embedding sub-spaces. To improve the model's robustness and update the inconsistent features from the spatial-temporal embeddings, we adopt the bidirectional purification module (BPM) after the RCAM. Extensive experiments on five popular benchmarks show that our FSNet is robust to various challenging scenarios (e.g., motion blur, occlusion) and achieves favourable performance against existing cutting-edges both in the video object segmentation and video salient object detection tasks. The project is publicly available at: https://dpfan.net/FSNet.