 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-NBA: Efficient and Effective Search Over the Joint Space of Networks, Bitwidths, and Accelerators
Jun 11, 2021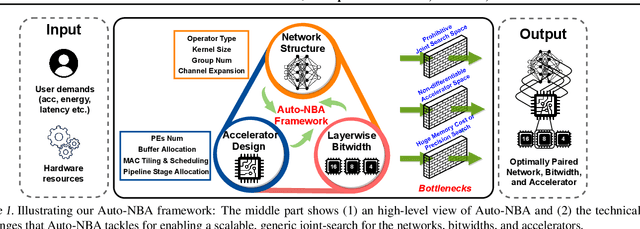
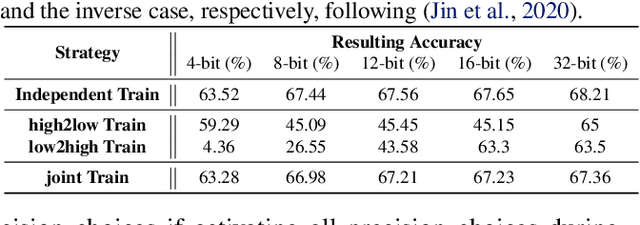
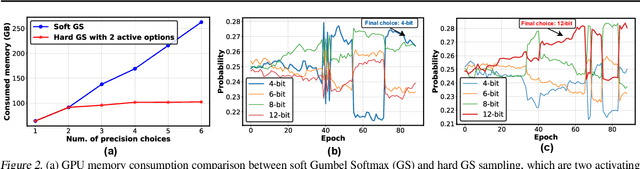
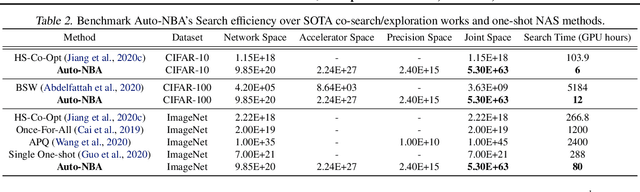
While maximizing deep neural networks' (DNNs') acceleration efficiency requires a joint search/design of three different yet highly coupled aspects, including the networks, bitwidths, and accelerators, the challenges associated with such a joint search have not yet been fully understood and addressed. The key challenges include (1) the dilemma of whether to explode the memory consumption due to the huge joint space or achieve sub-optimal designs, (2) the discrete nature of the accelerator design space that is coupled yet different from that of the networks and bitwidths, and (3) the chicken and egg problem associated with network-accelerator co-search, i.e., co-search requires operation-wise hardware cost, which is lacking during search as the optimal accelerator depending on the whole network is still unknown during search. To tackle these daunting challenges towards optimal and fast development of DNN accelerators, we propose a framework dubbed Auto-NBA to enable jointly searching for the Networks, Bitwidths, and Accelerators, by efficiently localizing the optimal design within the huge joint design space for each target dataset and acceleration specification. Our Auto-NBA integrates a heterogeneous sampling strategy to achieve unbiased search with constant memory consumption, and a novel joint-search pipeline equipped with a generic differentiable accelerator search engine. Extensive experiments and ablation studies validate that both Auto-NBA generated networks and accelerators consistently outperform state-of-the-art designs (including co-search/exploration techniques, hardware-aware NAS methods, and DNN accelerators), in terms of search time, task accuracy, and accelerator efficiency. Our codes are available at: https://github.com/RICE-EIC/Auto-NBA.
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021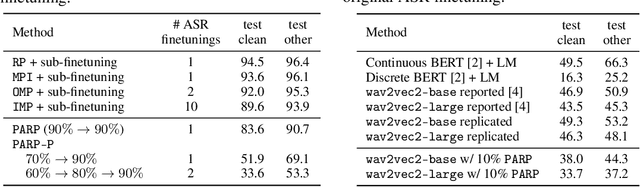
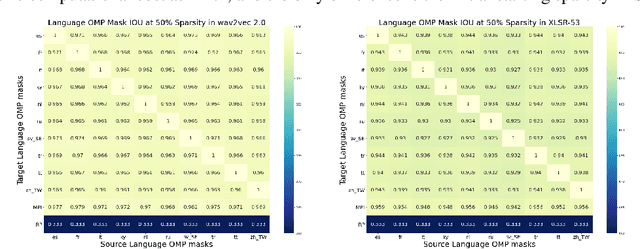
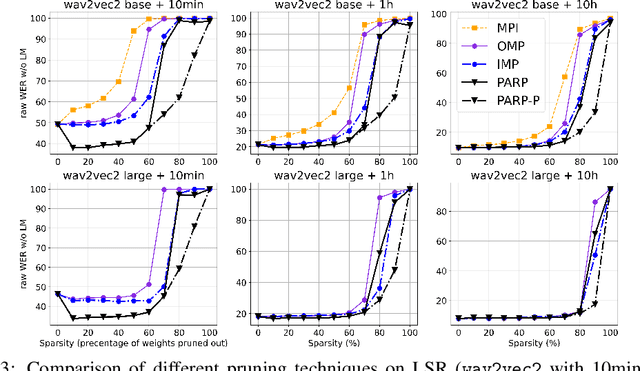
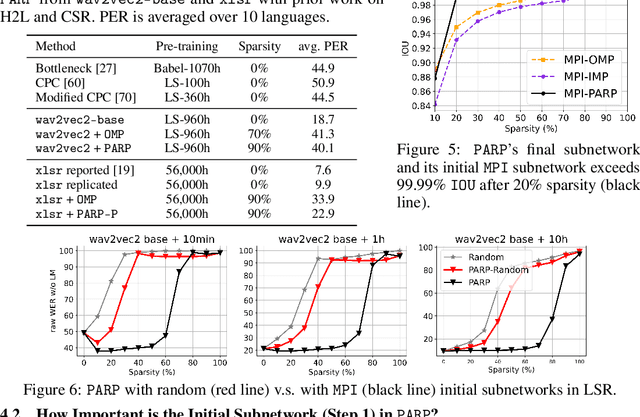
Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.
Lifelong Object Detection
Sep 02, 2020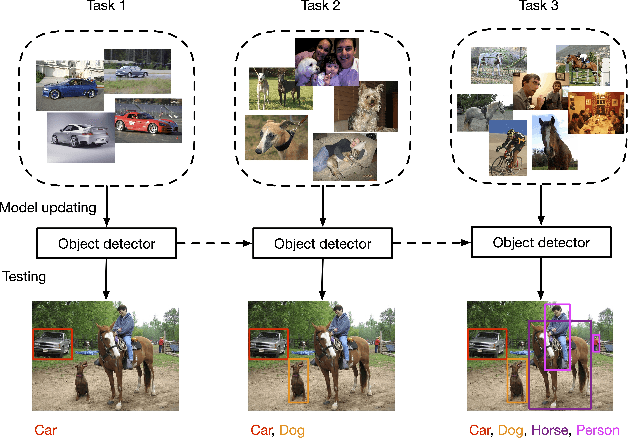
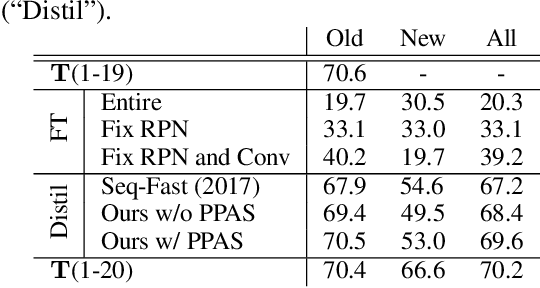
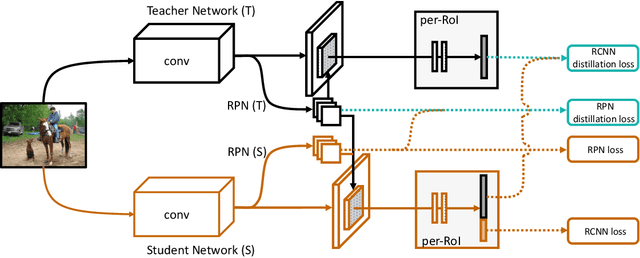

Recent advances in object detection have benefited significantly from rapid developments in deep neural networks. However, neural networks suffer from the well-known issue of catastrophic forgetting, which makes continual or lifelong learning problematic. In this paper, we leverage the fact that new training classes arrive in a sequential manner and incrementally refine the model so that it additionally detects new object classes in the absence of previous training data. Specifically, we consider the representative object detector, Faster R-CNN, for both accurate and efficient prediction. To prevent abrupt performance degradation due to catastrophic forgetting, we propose to apply knowledge distillation on both the region proposal network and the region classification network, to retain the detection of previously trained classes. A pseudo-positive-aware sampling strategy is also introduced for distillation sample selection. We evaluate the proposed method on PASCAL VOC 2007 and MS COCO benchmarks and show competitive mAP and 6x inference speed improvement, which makes the approach more suitable for real-time applications. Our implementation will be publicly available.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
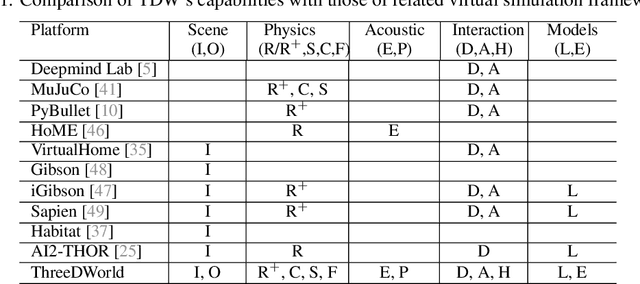

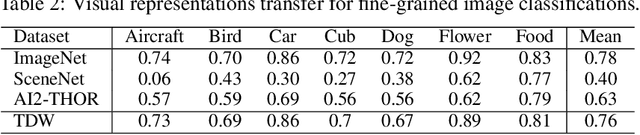
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Unsupervised Speech Decomposition via Triple Information Bottleneck
May 04, 2020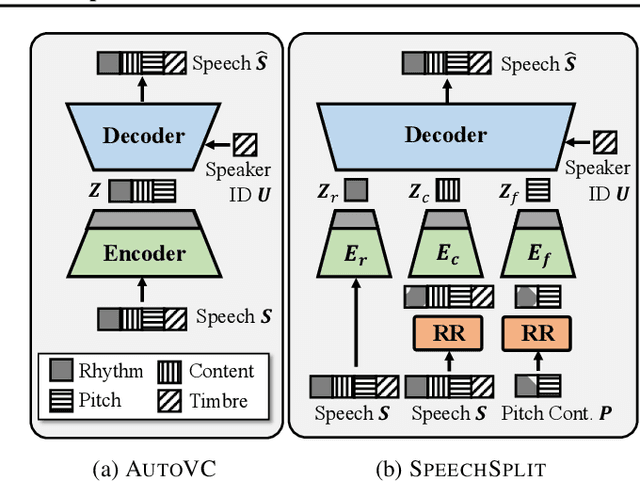
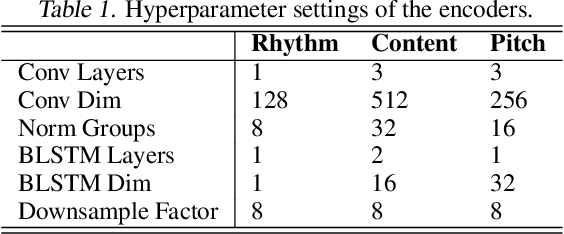
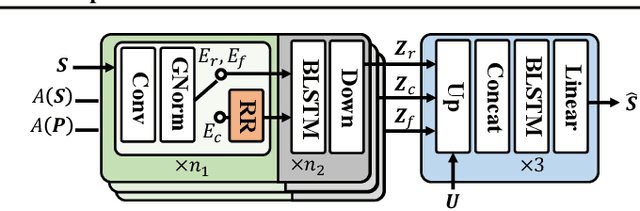

Speech information can be roughly decomposed into four components: language content, timbre, pitch, and rhythm. Obtaining disentangled representations of these components is useful in many speech analysis and generation applications. Recently, state-of-the-art voice conversion systems have led to speech representations that can disentangle speaker-dependent and independent information. However, these systems can only disentangle timbre, while information about pitch, rhythm and content is still mixed together. Further disentangling the remaining speech components is an under-determined problem in the absence of explicit annotations for each component, which are difficult and expensive to obtain. In this paper, we propose SpeechSplit, which can blindly decompose speech into its four components by introducing three carefully designed information bottlenecks. SpeechSplit is among the first algorithms that can separately perform style transfer on timbre, pitch and rhythm without text labels.
More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
Dec 02, 2019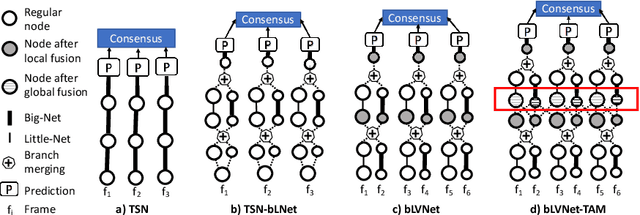
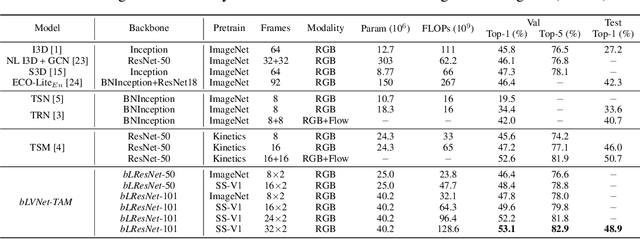
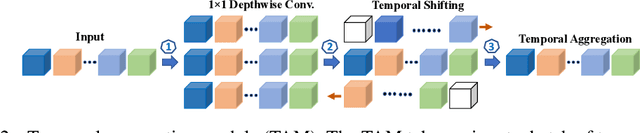
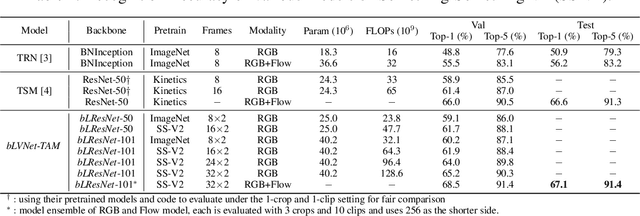
Current state-of-the-art models for video action recognition are mostly based on expensive 3D ConvNets. This results in a need for large GPU clusters to train and evaluate such architectures. To address this problem, we present a lightweight and memory-friendly architecture for action recognition that performs on par with or better than current architectures by using only a fraction of resources. The proposed architecture is based on a combination of a deep subnet operating on low-resolution frames with a compact subnet operating on high-resolution frames, allowing for high efficiency and accuracy at the same time. We demonstrate that our approach achieves a reduction by $3\sim4$ times in FLOPs and $\sim2$ times in memory usage compared to the baseline. This enables training deeper models with more input frames under the same computational budget. To further obviate the need for large-scale 3D convolutions, a temporal aggregation module is proposed to model temporal dependencies in a video at very small additional computational costs. Our models achieve strong performance on several action recognition benchmarks including Kinetics, Something-Something and Moments-in-time. The code and models are available at https://github.com/IBM/bLVNet-TAM.
Self-supervised Moving Vehicle Tracking with Stereo Sound
Oct 25, 2019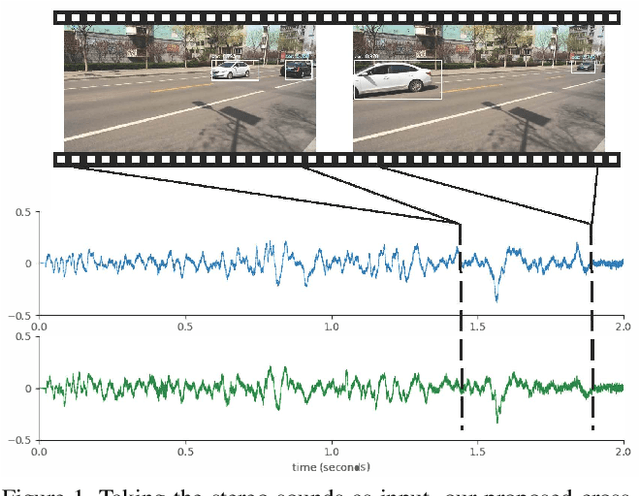
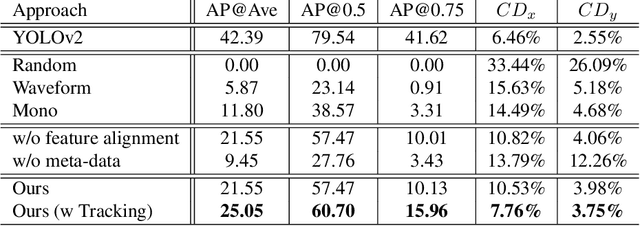
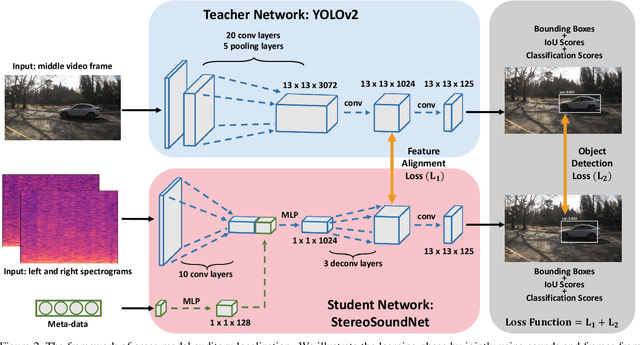
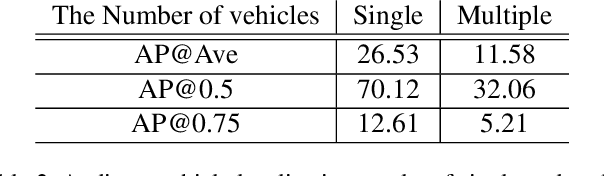
Humans are able to localize objects in the environment using both visual and auditory cues, integrating information from multiple modalities into a common reference frame. We introduce a system that can leverage unlabeled audio-visual data to learn to localize objects (moving vehicles) in a visual reference frame, purely using stereo sound at inference time. Since it is labor-intensive to manually annotate the correspondences between audio and object bounding boxes, we achieve this goal by using the co-occurrence of visual and audio streams in unlabeled videos as a form of self-supervision, without resorting to the collection of ground-truth annotations. In particular, we propose a framework that consists of a vision "teacher" network and a stereo-sound "student" network. During training, knowledge embodied in a well-established visual vehicle detection model is transferred to the audio domain using unlabeled videos as a bridge. At test time, the stereo-sound student network can work independently to perform object localization us-ing just stereo audio and camera meta-data, without any visual input. Experimental results on a newly collected Au-ditory Vehicle Tracking dataset verify that our proposed approach outperforms several baseline approaches. We also demonstrate that our cross-modal auditory localization approach can assist in the visual localization of moving vehicles under poor lighting conditions.
ZO-AdaMM: Zeroth-Order Adaptive Momentum Method for Black-Box Optimization
Oct 16, 2019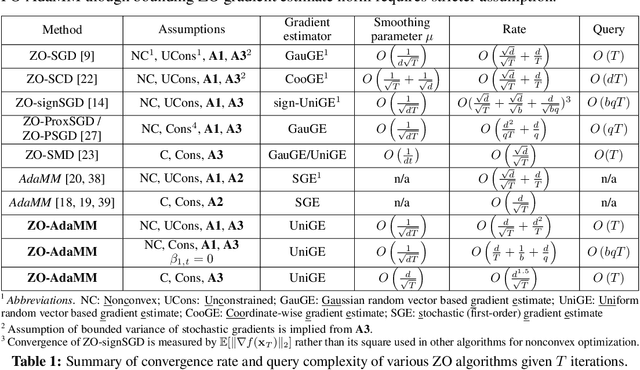
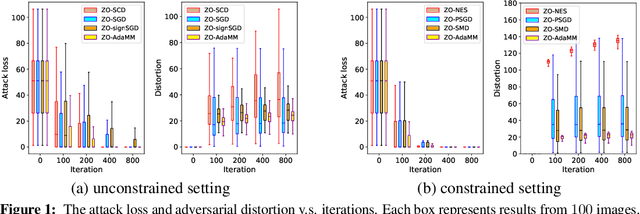
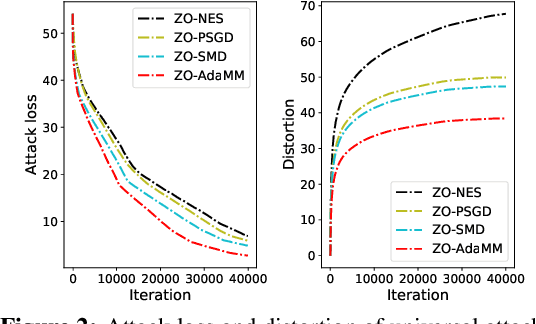
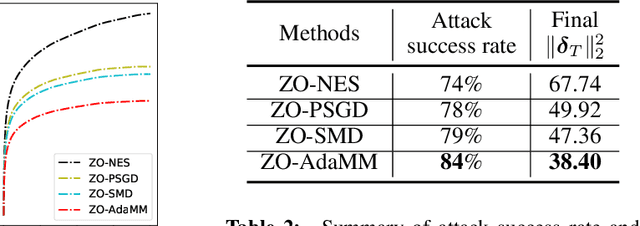
The adaptive momentum method (AdaMM), which uses past gradients to update descent directions and learning rates simultaneously, has become one of the most popular first-order optimization methods for solving machine learning problems. However, AdaMM is not suited for solving black-box optimization problems, where explicit gradient forms are difficult or infeasible to obtain. In this paper, we propose a zeroth-order AdaMM (ZO-AdaMM) algorithm, that generalizes AdaMM to the gradient-free regime. We show that the convergence rate of ZO-AdaMM for both convex and nonconvex optimization is roughly a factor of $O(\sqrt{d})$ worse than that of the first-order AdaMM algorithm, where $d$ is problem size. In particular, we provide a deep understanding on why Mahalanobis distance matters in convergence of ZO-AdaMM and other AdaMM-type methods. As a byproduct, our analysis makes the first step toward understanding adaptive learning rate methods for nonconvex constrained optimization. Furthermore, we demonstrate two applications, designing per-image and universal adversarial attacks from black-box neural networks, respectively. We perform extensive experiments on ImageNet and empirically show that ZO-AdaMM converges much faster to a solution of high accuracy compared with $6$ state-of-the-art ZO optimization methods.
Conditional Infilling GANs for Data Augmentation in Mammogram Classification
Aug 24, 2018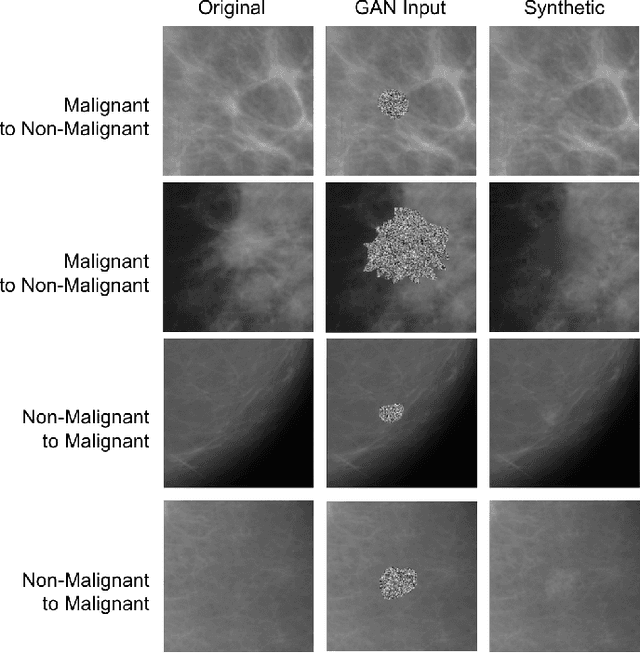
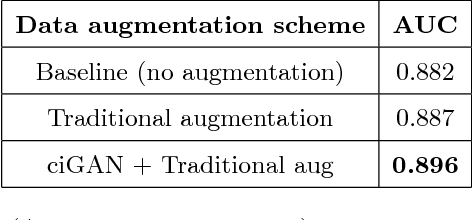
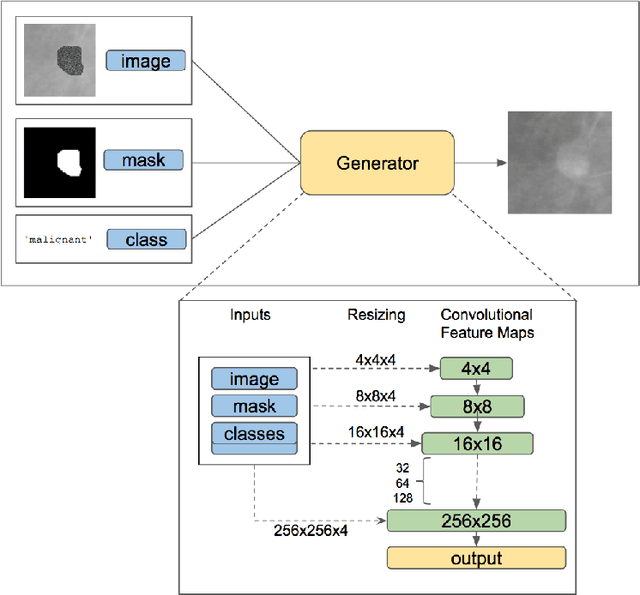
Deep learning approaches to breast cancer detection in mammograms have recently shown promising results. However, such models are constrained by the limited size of publicly available mammography datasets, in large part due to privacy concerns and the high cost of generating expert annotations. Limited dataset size is further exacerbated by substantial class imbalance since "normal" images dramatically outnumber those with findings. Given the rapid progress of generative models in synthesizing realistic images, and the known effectiveness of simple data augmentation techniques (e.g. horizontal flipping), we ask if it is possible to synthetically augment mammogram datasets using generative adversarial networks (GANs). We train a class-conditional GAN to perform contextual in-filling, which we then use to synthesize lesions onto healthy screening mammograms. First, we show that GANs are capable of generating high-resolution synthetic mammogram patches. Next, we experimentally evaluate using the augmented dataset to improve breast cancer classification performance. We observe that a ResNet-50 classifier trained with GAN-augmented training data produces a higher AUROC compared to the same model trained only on traditionally augmented data, demonstrating the potential of our approach.
A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception
May 30, 2018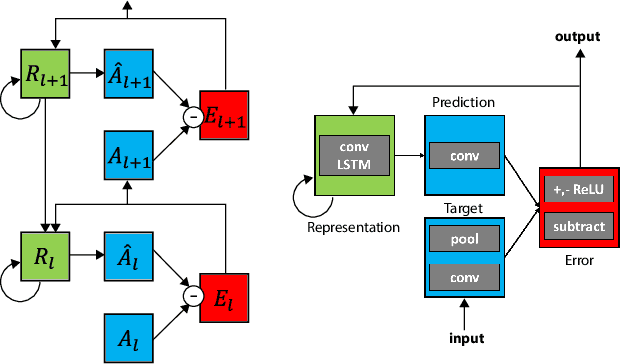
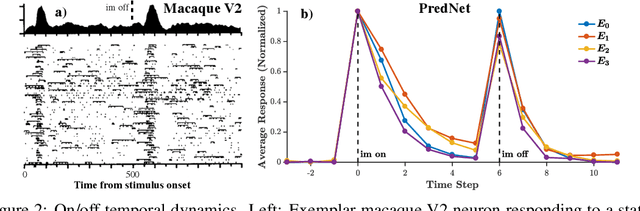

While deep neural networks take loose inspiration from neuroscience, it is an open question how seriously to take the analogies between artificial deep networks and biological neuronal systems. Interestingly, recent work has shown that deep convolutional neural networks (CNNs) trained on large-scale image recognition tasks can serve as strikingly good models for predicting the responses of neurons in visual cortex to visual stimuli, suggesting that analogies between artificial and biological neural networks may be more than superficial. However, while CNNs capture key properties of the average responses of cortical neurons, they fail to explain other properties of these neurons. For one, CNNs typically require large quantities of labeled input data for training. Our own brains, in contrast, rarely have access to this kind of supervision, so to the extent that representations are similar between CNNs and brains, this similarity must arise via different training paths. In addition, neurons in visual cortex produce complex time-varying responses even to static inputs, and they dynamically tune themselves to temporal regularities in the visual environment. We argue that these differences are clues to fundamental differences between the computations performed in the brain and in deep networks. To begin to close the gap, here we study the emergent properties of a previously-described recurrent generative network that is trained to predict future video frames in a self-supervised manner. Remarkably, the model is able to capture a wide variety of seemingly disparate phenomena observed in visual cortex, ranging from single unit response dynamics to complex perceptual motion illusions. These results suggest potentially deep connections between recurrent predictive neural network models and the brain, providing new leads that can enrich both fields.