 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Performance Portability needs Autotuning
Apr 30, 2025As LLMs grow in complexity, achieving state-of-the-art performance requires tight co-design across algorithms, software, and hardware. Today's reliance on a single dominant platform limits portability, creates vendor lock-in, and raises barriers for new AI hardware. In this work, we make the case for combining just-in-time (JIT) compilation with kernel parameter autotuning to enable portable, state-of-the-art performance LLM execution without code changes. Focusing on flash attention -- a widespread performance-critical LLM kernel -- we demonstrate that this approach explores up to 15x more kernel parameter configurations, produces significantly more diverse code across multiple dimensions, and even outperforms vendor-optimized implementations by up to 230%, all while reducing kernel code size by 70x and eliminating manual code optimizations. Our results highlight autotuning as a promising path to unlocking model portability across GPU vendors.
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
LLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services
Oct 03, 2024



As Large Language Models (LLMs) are rapidly growing in popularity, LLM inference services must be able to serve requests from thousands of users while satisfying performance requirements. The performance of an LLM inference service is largely determined by the hardware onto which it is deployed, but understanding of which hardware will deliver on performance requirements remains challenging. In this work we present LLM-Pilot - a first-of-its-kind system for characterizing and predicting performance of LLM inference services. LLM-Pilot performs benchmarking of LLM inference services, under a realistic workload, across a variety of GPUs, and optimizes the service configuration for each considered GPU to maximize performance. Finally, using this characterization data, LLM-Pilot learns a predictive model, which can be used to recommend the most cost-effective hardware for a previously unseen LLM. Compared to existing methods, LLM-Pilot can deliver on performance requirements 33% more frequently, whilst reducing costs by 60% on average.
Accelerating Production LLMs with Combined Token/Embedding Speculators
Apr 29, 2024This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
Search-based Methods for Multi-Cloud Configuration
Apr 20, 2022
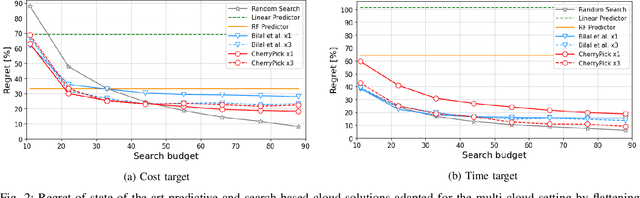
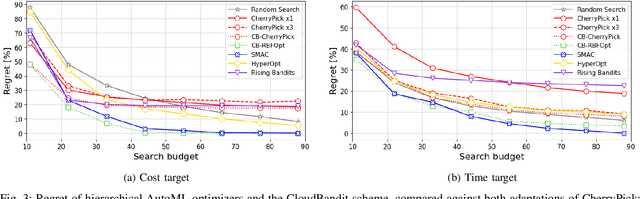
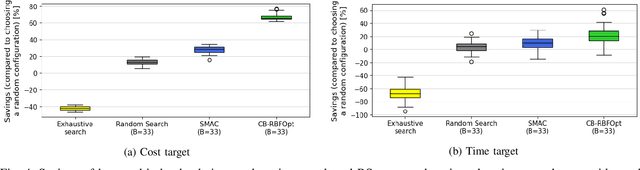
Multi-cloud computing has become increasingly popular with enterprises looking to avoid vendor lock-in. While most cloud providers offer similar functionality, they may differ significantly in terms of performance and/or cost. A customer looking to benefit from such differences will naturally want to solve the multi-cloud configuration problem: given a workload, which cloud provider should be chosen and how should its nodes be configured in order to minimize runtime or cost? In this work, we consider solutions to this optimization problem. We develop and evaluate possible adaptations of state-of-the-art cloud configuration solutions to the multi-cloud domain. Furthermore, we identify an analogy between multi-cloud configuration and the selection-configuration problems commonly studied in the automated machine learning (AutoML) field. Inspired by this connection, we utilize popular optimizers from AutoML to solve multi-cloud configuration. Finally, we propose a new algorithm for solving multi-cloud configuration, CloudBandit (CB). It treats the outer problem of cloud provider selection as a best-arm identification problem, in which each arm pull corresponds to running an arbitrary black-box optimizer on the inner problem of node configuration. Our experiments indicate that (a) many state-of-the-art cloud configuration solutions can be adapted to multi-cloud, with best results obtained for adaptations which utilize the hierarchical structure of the multi-cloud configuration domain, (b) hierarchical methods from AutoML can be used for the multi-cloud configuration task and can outperform state-of-the-art cloud configuration solutions and (c) CB achieves competitive or lower regret relative to other tested algorithms, whilst also identifying configurations that have 65% lower median cost and 20% lower median time in production, compared to choosing a random provider and configuration.
Towards a General Framework for ML-based Self-tuning Databases
Nov 16, 2020
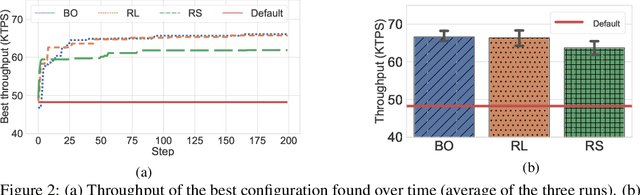
Machine learning (ML) methods have recently emerged as an effective way to perform automated parameter tuning of databases. State-of-the-art approaches include Bayesian optimization (BO) and reinforcement learning (RL). In this work, we describe our experience when applying these methods to a database not yet studied in this context: FoundationDB. Firstly, we describe the challenges we faced, such as unknown valid ranges of configuration parameters and combinations of parameter values that result in invalid runs, and how we mitigated them. While these issues are typically overlooked, we argue that they are a crucial barrier to the adoption of ML self-tuning techniques in databases, and thus deserve more attention from the research community. Secondly, we present experimental results obtained when tuning FoundationDB using ML methods. Unlike prior work in this domain, we also compare with the simplest of baselines: random search. Our results show that, while BO and RL methods can improve the throughput of FoundationDB by up to 38%, random search is a highly competitive baseline, finding a configuration that is only 4% worse than the, vastly more complex, ML methods. We conclude that future work in this area may want to focus more on randomized, model-free optimization algorithms.
Differentially Private Stochastic Coordinate Descent
Jul 10, 2020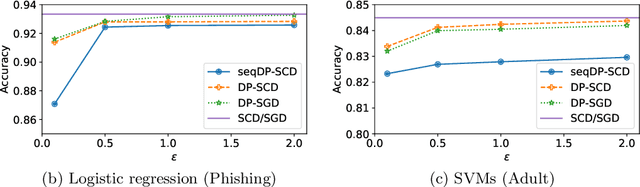

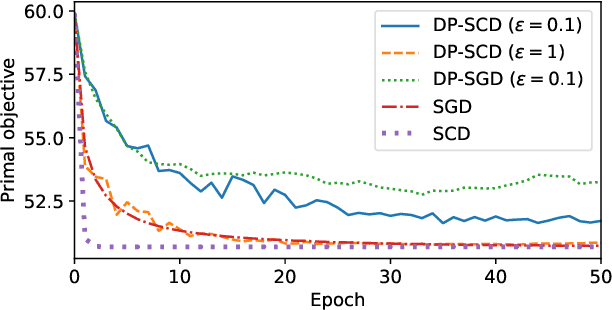
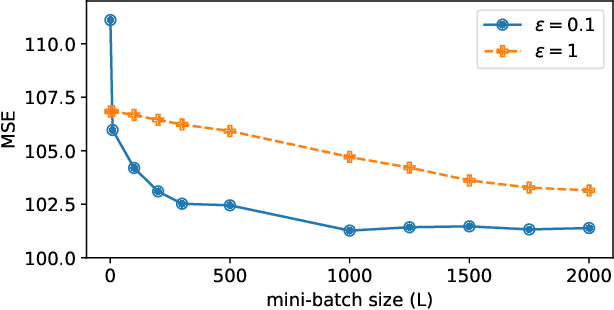
In this paper we tackle the challenge of making the stochastic coordinate descent algorithm differentially private. Compared to the classical gradient descent algorithm where updates operate on a single model vector and controlled noise addition to this vector suffices to hide critical information about individuals, stochastic coordinate descent crucially relies on keeping auxiliary information in memory during training. This auxiliary information provides an additional privacy leak and poses the major challenge addressed in this work. Driven by the insight that under independent noise addition, the consistency of the auxiliary information holds in expectation, we present DP-SCD, the first differentially private stochastic coordinate descent algorithm. We analyze our new method theoretically and argue that decoupling and parallelizing coordinate updates is essential for its utility. On the empirical side we demonstrate competitive performance against the popular stochastic gradient descent alternative (DP-SGD) while requiring significantly less tuning.
MixBoost: A Heterogeneous Boosting Machine
Jun 17, 2020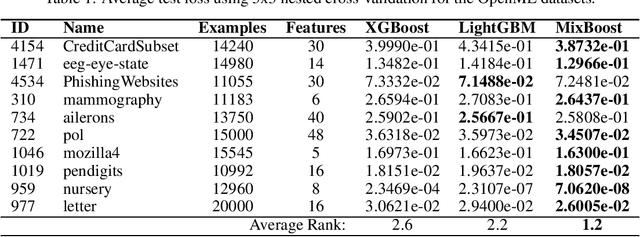
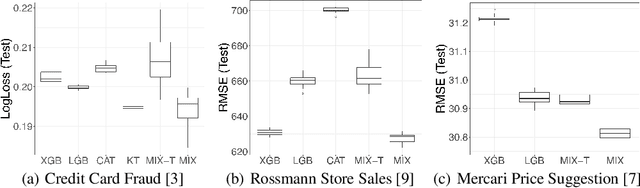
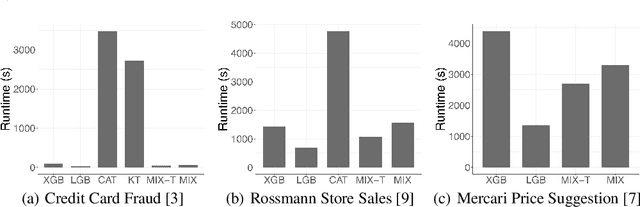

Modern gradient boosting software frameworks, such as XGBoost and LightGBM, implement Newton descent in a functional space. At each boosting iteration, their goal is to find the base hypothesis, selected from some base hypothesis class, that is closest to the Newton descent direction in a Euclidean sense. Typically, the base hypothesis class is fixed to be all binary decision trees up to a given depth. In this work, we study a Heterogeneous Newton Boosting Machine (HNBM) in which the base hypothesis class may vary across boosting iterations. Specifically, at each boosting iteration, the base hypothesis class is chosen, from a fixed set of subclasses, by sampling from a probability distribution. We derive a global linear convergence rate for the HNBM under certain assumptions, and show that it agrees with existing rates for Newton's method when the Newton direction can be perfectly fitted by the base hypothesis at each boosting iteration. We then describe a particular realization of a HNBM, MixBoost, that, at each boosting iteration, randomly selects between either a decision tree of variable depth or a linear regressor with random Fourier features. We describe how MixBoost is implemented, with a focus on the training complexity. Finally, we present experimental results, using OpenML and Kaggle datasets, that show that MixBoost is able to achieve better generalization loss than competing boosting frameworks, without taking significantly longer to tune.
SySCD: A System-Aware Parallel Coordinate Descent Algorithm
Nov 18, 2019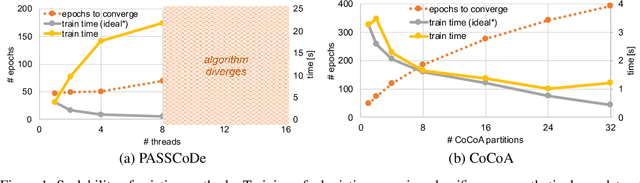
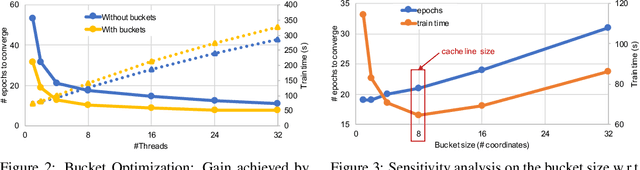

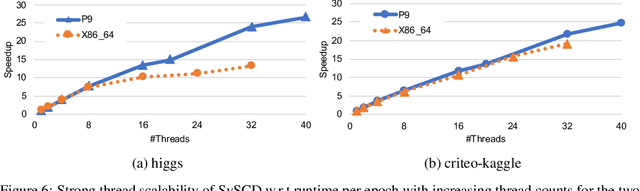
In this paper we propose a novel parallel stochastic coordinate descent (SCD) algorithm with convergence guarantees that exhibits strong scalability. We start by studying a state-of-the-art parallel implementation of SCD and identify scalability as well as system-level performance bottlenecks of the respective implementation. We then take a principled approach to develop a new SCD variant which is designed to avoid the identified system bottlenecks, such as limited scaling due to coherence traffic of model sharing across threads, and inefficient CPU cache accesses. Our proposed system-aware parallel coordinate descent algorithm (SySCD) scales to many cores and across numa nodes, and offers a consistent bottom line speedup in training time of up to x12 compared to an optimized asynchronous parallel SCD algorithm and up to x42, compared to state-of-the-art GLM solvers (scikit-learn, Vowpal Wabbit, and H2O) on a range of datasets and multi-core CPU architectures.
Breadth-first, Depth-next Training of Random Forests
Oct 15, 2019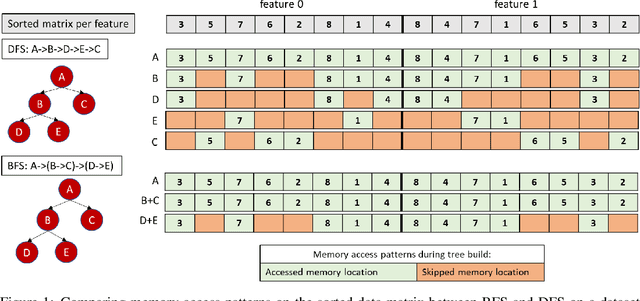
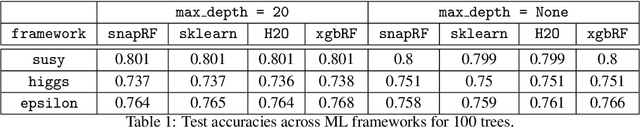
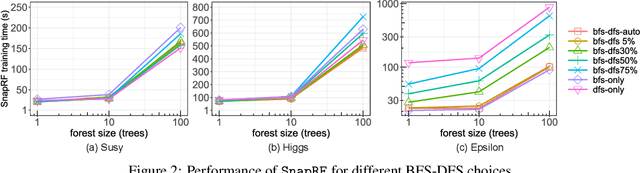
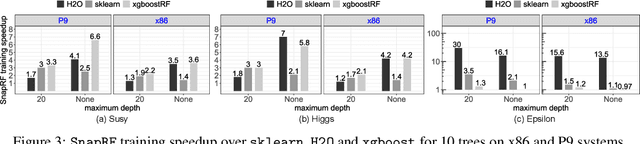
In this paper we analyze, evaluate, and improve the performance of training Random Forest (RF) models on modern CPU architectures. An exact, state-of-the-art binary decision tree building algorithm is used as the basis of this study. Firstly, we investigate the trade-offs between using different tree building algorithms, namely breadth-first-search (BFS) and depth-search-first (DFS). We design a novel, dynamic, hybrid BFS-DFS algorithm and demonstrate that it performs better than both BFS and DFS, and is more robust in the presence of workloads with different characteristics. Secondly, we identify CPU performance bottlenecks when generating trees using this approach, and propose optimizations to alleviate them. The proposed hybrid tree building algorithm for RF is implemented in the Snap Machine Learning framework, and speeds up the training of RFs by 7.8x on average when compared to state-of-the-art RF solvers (sklearn, H2O, and xgboost) on a range of datasets, RF configurations, and multi-core CPU architectures.