 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliffSearch: Structured Agentic Co-Evolution over Theory and Code for Scientific Algorithm Discovery
Apr 01, 2026Scientific algorithm discovery is iterative: hypotheses are proposed, implemented, stress-tested, and revised. Current LLM-guided search systems accelerate proposal generation, but often under-represent scientific structure by optimizing code-only artifacts with weak correctness/originality gating. We present CliffSearch, an agentic evolutionary framework in which the core evolution operators (pair selection, crossover, mutation, and review) are implemented as LLM agents, and the loop is designed around three principles: (1) each node is a structured scientific artifact, instantiated in either theory+code or code_only mode, (2) reviewer judgments of correctness and originality are first-class selection gates alongside optimization of the benchmark metric of interest, and (3) mutation is split into exploration and correction pathways with distinct objectives. Exploration mutation imports ideas from adjacent scientific domains to increase novelty, while correction mutation performs targeted evidence-guided repair using reviewer signals over theory, code, benchmark results, and runtime errors. We illustrate the framework on three benchmark-grounded studies: transformer hyper-connection evolution, optimizer discovery on a fixed nanoGPT stack, and a smaller native-optimizer ablation. Across these settings, the same loop supports explicit metric direction, reproducible persistence, and reviewer-gated comparison of discoveries under controlled search conditions. The result is a discovery workflow that prioritizes scientific interpretability and correctness while optimizing task metrics under controlled novelty constraints, rather than maximizing candidate throughput alone. Full run artifacts, interactive visualizations, and exported best nodes for the reported studies are available at https://cliffsearch.ai .
GP-MoLFormer-Sim: Test Time Molecular Optimization through Contextual Similarity Guidance
Jun 05, 2025The ability to design molecules while preserving similarity to a target molecule and/or property is crucial for various applications in drug discovery, chemical design, and biology. We introduce in this paper an efficient training-free method for navigating and sampling from the molecular space with a generative Chemical Language Model (CLM), while using the molecular similarity to the target as a guide. Our method leverages the contextual representations learned from the CLM itself to estimate the molecular similarity, which is then used to adjust the autoregressive sampling strategy of the CLM. At each step of the decoding process, the method tracks the distance of the current generations from the target and updates the logits to encourage the preservation of similarity in generations. We implement the method using a recently proposed $\sim$47M parameter SMILES-based CLM, GP-MoLFormer, and therefore refer to the method as GP-MoLFormer-Sim, which enables a test-time update of the deep generative policy to reflect the contextual similarity to a set of guide molecules. The method is further integrated into a genetic algorithm (GA) and tested on a set of standard molecular optimization benchmarks involving property optimization, molecular rediscovery, and structure-based drug design. Results show that, GP-MoLFormer-Sim, combined with GA (GP-MoLFormer-Sim+GA) outperforms existing training-free baseline methods, when the oracle remains black-box. The findings in this work are a step forward in understanding and guiding the generative mechanisms of CLMs.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024



AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Distributional Preference Alignment of LLMs via Optimal Transport
Jun 09, 2024



Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Risk Assessment and Statistical Significance in the Age of Foundation Models
Oct 11, 2023



We propose a distributional framework for assessing socio-technical risks of foundation models with quantified statistical significance. Our approach hinges on a new statistical relative testing based on first and second order stochastic dominance of real random variables. We show that the second order statistics in this test are linked to mean-risk models commonly used in econometrics and mathematical finance to balance risk and utility when choosing between alternatives. Using this framework, we formally develop a risk-aware approach for foundation model selection given guardrails quantified by specified metrics. Inspired by portfolio optimization and selection theory in mathematical finance, we define a \emph{metrics portfolio} for each model as a means to aggregate a collection of metrics, and perform model selection based on the stochastic dominance of these portfolios. The statistical significance of our tests is backed theoretically by an asymptotic analysis via central limit theorems instantiated in practice via a bootstrap variance estimate. We use our framework to compare various large language models regarding risks related to drifting from instructions and outputting toxic content.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Cloud-Based Real-Time Molecular Screening Platform with MolFormer
Aug 13, 2022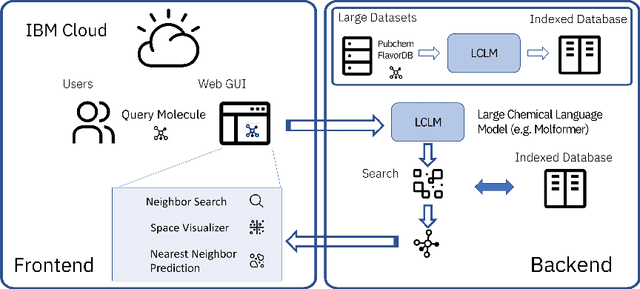
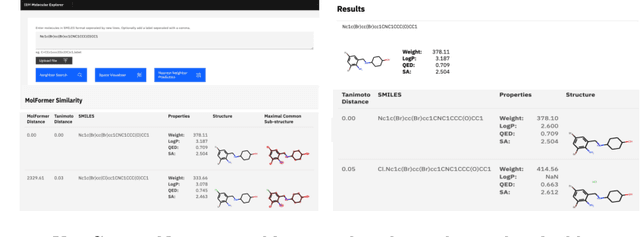
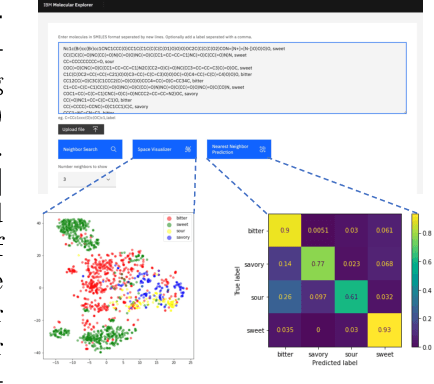
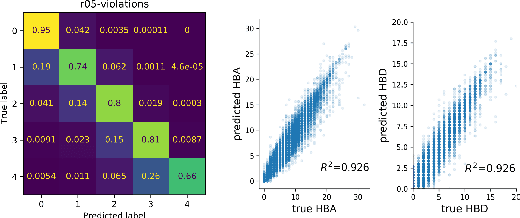
With the prospect of automating a number of chemical tasks with high fidelity, chemical language processing models are emerging at a rapid speed. Here, we present a cloud-based real-time platform that allows users to virtually screen molecules of interest. For this purpose, molecular embeddings inferred from a recently proposed large chemical language model, named MolFormer, are leveraged. The platform currently supports three tasks: nearest neighbor retrieval, chemical space visualization, and property prediction. Based on the functionalities of this platform and results obtained, we believe that such a platform can play a pivotal role in automating chemistry and chemical engineering research, as well as assist in drug discovery and material design tasks. A demo of our platform is provided at \url{www.ibm.biz/molecular_demo}.
G2L: A Geometric Approach for Generating Pseudo-labels that Improve Transfer Learning
Jul 07, 2022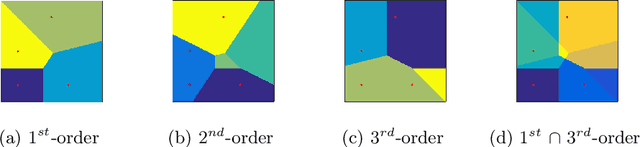
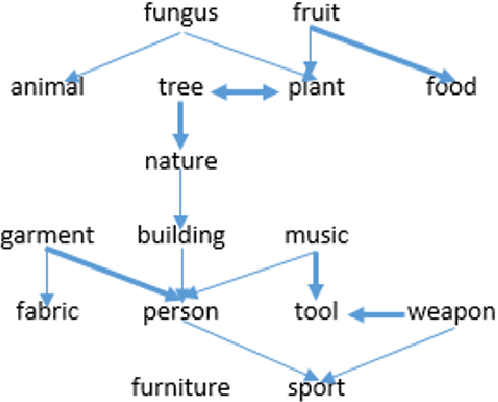
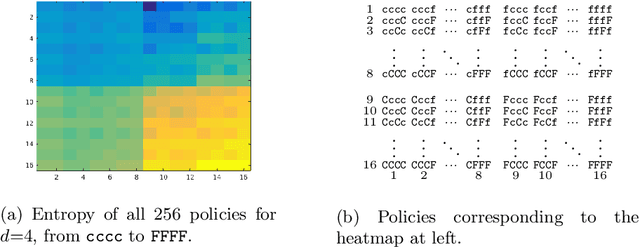
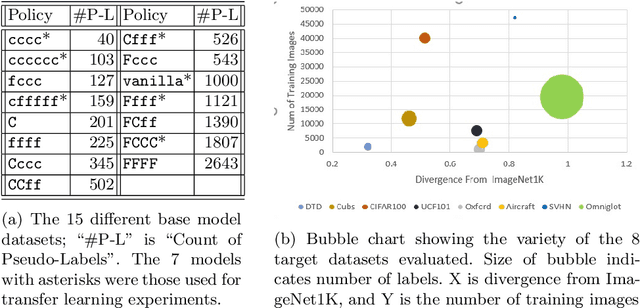
Transfer learning is a deep-learning technique that ameliorates the problem of learning when human-annotated labels are expensive and limited. In place of such labels, it uses instead the previously trained weights from a well-chosen source model as the initial weights for the training of a base model for a new target dataset. We demonstrate a novel but general technique for automatically creating such source models. We generate pseudo-labels according to an efficient and extensible algorithm that is based on a classical result from the geometry of high dimensions, the Cayley-Menger determinant. This G2L (``geometry to label'') method incrementally builds up pseudo-labels using a greedy computation of hypervolume content. We demonstrate that the method is tunable with respect to expected accuracy, which can be forecast by an information-theoretic measure of dataset similarity (divergence) between source and target. The results of 280 experiments show that this mechanical technique generates base models that have similar or better transferability compared to a baseline of models trained on extensively human-annotated ImageNet1K labels, yielding an overall error decrease of 0.43\%, and an error decrease in 4 out of 5 divergent datasets tested.