 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Self-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts
Mar 11, 2026We propose self-speculative decoding for speech-aware LLMs by using the CTC encoder as a draft model to accelerate auto-regressive (AR) inference and improve ASR accuracy. Our three-step procedure works as follows: (1) if the frame entropies of the CTC output distributions are below a threshold, the greedy CTC hypothesis is accepted as final; (2) otherwise, the CTC hypothesis is verified in a single LLM forward pass using a relaxed acceptance criterion based on token likelihoods; (3) if verification fails, AR decoding resumes from the accepted CTC prefix. Experiments on nine corpora and five languages show that this approach can simultaneously accelerate decoding and reduce WER. On the HuggingFace Open ASR benchmark with a 1B parameter LLM and 440M parameter CTC encoder, we achieve a record 5.58% WER and improve the inverse real time factor by a factor of 4.4 with only a 12% relative WER increase over AR search. Code and model weights are publicly available under a permissive license.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Putting It All into Context: Simplifying Agents with LCLMs
May 12, 2025Recent advances in language model (LM) agents have demonstrated significant potential for automating complex real-world tasks. To make progress on these difficult tasks, LM agent architectures have become increasingly complex, often incorporating multi-step retrieval tools, multiple agents, and scaffolding adapted to the underlying LM. In this work, we investigate whether all of this complexity is necessary, or if parts of these scaffolds can be removed on challenging tasks like SWE-bench. We show that in the case of SWE-bench, simply putting the entire environment into the context of a long context language model (LCLM) and properly prompting the model makes it competitive with carefully tuned, complex agent scaffolds. We show that a Gemini-1.5-Pro model without any scaffolding or tools achieves 38% on SWE-Bench-Verified, comparable with approaches using carefully tuned agent scaffolds (32%). While the unscaffolded approach with Gemini-1.5-Pro falls short of the strongest agentic architectures, we demonstrate that the more capable Gemini-2.5-Pro using the same unscaffolded approach directly attains a 50.8% solve rate. Additionally, a two-stage approach combining Gemini-1.5-Pro with Claude-3.7 achieves a competitive 48.6% solve rate.
A Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025



In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
Granite Embedding Models
Feb 27, 2025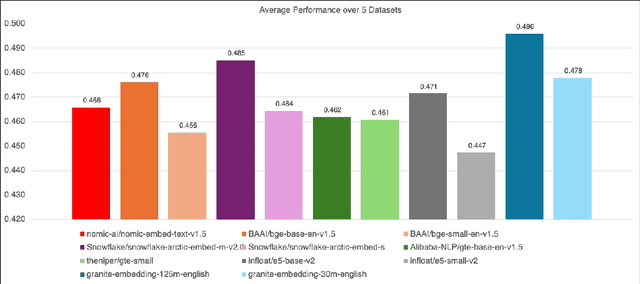
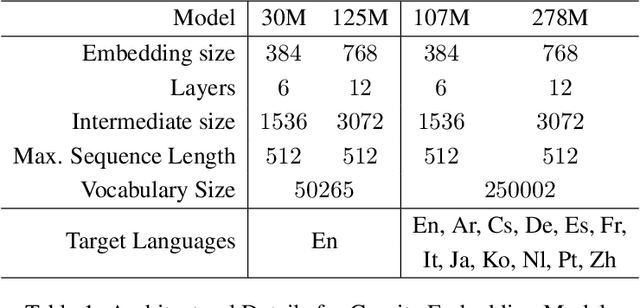
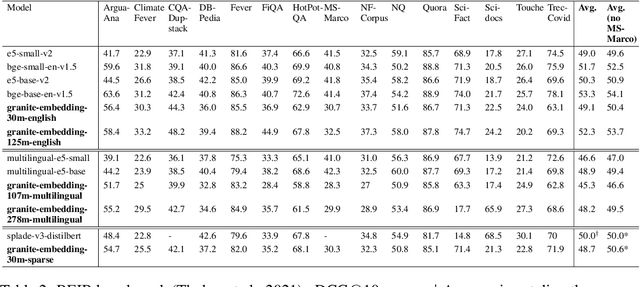

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
A Non-autoregressive Model for Joint STT and TTS
Jan 15, 2025In this paper, we take a step towards jointly modeling automatic speech recognition (STT) and speech synthesis (TTS) in a fully non-autoregressive way. We develop a novel multimodal framework capable of handling the speech and text modalities as input either individually or together. The proposed model can also be trained with unpaired speech or text data owing to its multimodal nature. We further propose an iterative refinement strategy to improve the STT and TTS performance of our model such that the partial hypothesis at the output can be fed back to the input of our model, thus iteratively improving both STT and TTS predictions. We show that our joint model can effectively perform both STT and TTS tasks, outperforming the STT-specific baseline in all tasks and performing competitively with the TTS-specific baseline across a wide range of evaluation metrics.
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.