 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
VAREX: A Benchmark for Multi-Modal Structured Extraction from Documents
Mar 16, 2026We introduce VAREX (VARied-schema EXtraction), a benchmark for evaluating multimodal foundation models on structured data extraction from government forms. VAREX employs a Reverse Annotation pipeline that programmatically fills PDF templates with synthetic values, producing deterministic ground truth validated through three-phase quality assurance. The benchmark comprises 1,777 documents with 1,771 unique schemas across three structural categories, each provided in four input modalities: plain text, layout-preserving text (whitespace-aligned to approximate column positions), document image, or both text and image combined. Unlike existing benchmarks that evaluate from a single input representation, VAREX provides four controlled modalities per document, enabling systematic ablation of how input format affects extraction accuracy -- a capability absent from prior benchmarks. We evaluate 20 models from frontier proprietary models to small open models, with particular attention to models <=4B parameters suitable for cost-sensitive and latency-constrained deployment. Results reveal that (1) below 4B parameters, structured output compliance -- not extraction capability -- is a dominant bottleneck; in particular, schema echo (models producing schema-conforming structure instead of extracted values) depresses scores by 45-65 pp (percentage points) in affected models; (2) extraction-specific fine-tuning at 2B yields +81 pp gains, demonstrating that the instruction-following deficit is addressable without scale; (3) layout-preserving text provides the largest accuracy gain (+3-18 pp), exceeding pixel-level visual cues; and (4) the benchmark most effectively discriminates models in the 60-95% accuracy band. Dataset and evaluation code are publicly available.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Granite Embedding Models
Feb 27, 2025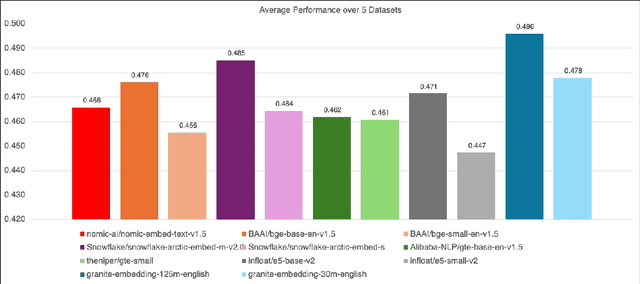
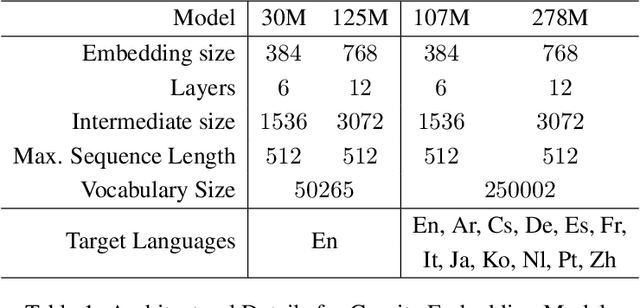
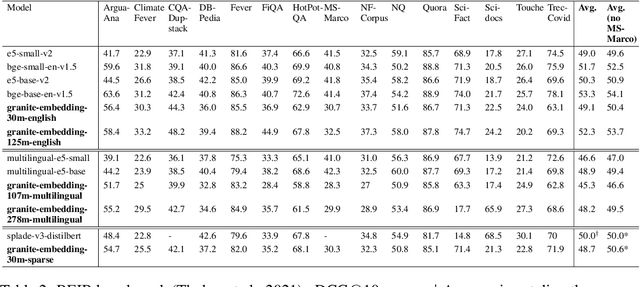

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.