 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-based Key-Point Extraction for MR-Guided Biomechanical Digital Twins of the Spine
Aug 20, 2025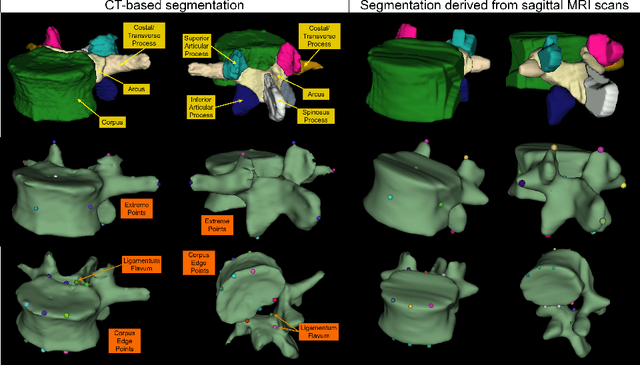

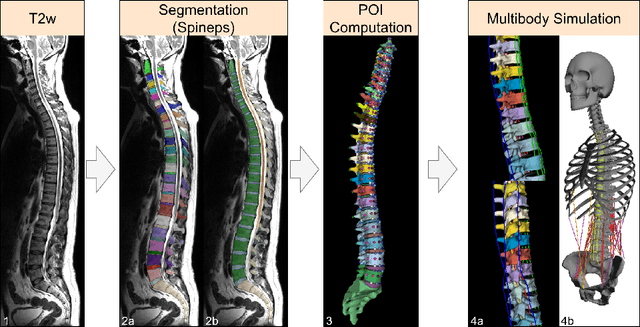

Digital twins offer a powerful framework for subject-specific simulation and clinical decision support, yet their development often hinges on accurate, individualized anatomical modeling. In this work, we present a rule-based approach for subpixel-accurate key-point extraction from MRI, adapted from prior CT-based methods. Our approach incorporates robust image alignment and vertebra-specific orientation estimation to generate anatomically meaningful landmarks that serve as boundary conditions and force application points, like muscle and ligament insertions in biomechanical models. These models enable the simulation of spinal mechanics considering the subject's individual anatomy, and thus support the development of tailored approaches in clinical diagnostics and treatment planning. By leveraging MR imaging, our method is radiation-free and well-suited for large-scale studies and use in underrepresented populations. This work contributes to the digital twin ecosystem by bridging the gap between precise medical image analysis with biomechanical simulation, and aligns with key themes in personalized modeling for healthcare.
Topology Optimization in Medical Image Segmentation with Fast Euler Characteristic
Jul 31, 2025Deep learning-based medical image segmentation techniques have shown promising results when evaluated based on conventional metrics such as the Dice score or Intersection-over-Union. However, these fully automatic methods often fail to meet clinically acceptable accuracy, especially when topological constraints should be observed, e.g., continuous boundaries or closed surfaces. In medical image segmentation, the correctness of a segmentation in terms of the required topological genus sometimes is even more important than the pixel-wise accuracy. Existing topology-aware approaches commonly estimate and constrain the topological structure via the concept of persistent homology (PH). However, these methods are difficult to implement for high dimensional data due to their polynomial computational complexity. To overcome this problem, we propose a novel and fast approach for topology-aware segmentation based on the Euler Characteristic ($\chi$). First, we propose a fast formulation for $\chi$ computation in both 2D and 3D. The scalar $\chi$ error between the prediction and ground-truth serves as the topological evaluation metric. Then we estimate the spatial topology correctness of any segmentation network via a so-called topological violation map, i.e., a detailed map that highlights regions with $\chi$ errors. Finally, the segmentation results from the arbitrary network are refined based on the topological violation maps by a topology-aware correction network. Our experiments are conducted on both 2D and 3D datasets and show that our method can significantly improve topological correctness while preserving pixel-wise segmentation accuracy.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
Parametric shape models for vessels learned from segmentations via differentiable voxelization
Jul 03, 2025Vessels are complex structures in the body that have been studied extensively in multiple representations. While voxelization is the most common of them, meshes and parametric models are critical in various applications due to their desirable properties. However, these representations are typically extracted through segmentations and used disjointly from each other. We propose a framework that joins the three representations under differentiable transformations. By leveraging differentiable voxelization, we automatically extract a parametric shape model of the vessels through shape-to-segmentation fitting, where we learn shape parameters from segmentations without the explicit need for ground-truth shape parameters. The vessel is parametrized as centerlines and radii using cubic B-splines, ensuring smoothness and continuity by construction. Meshes are differentiably extracted from the learned shape parameters, resulting in high-fidelity meshes that can be manipulated post-fit. Our method can accurately capture the geometry of complex vessels, as demonstrated by the volumetric fits in experiments on aortas, aneurysms, and brain vessels.
CINeMA: Conditional Implicit Neural Multi-Modal Atlas for a Spatio-Temporal Representation of the Perinatal Brain
Jun 11, 2025



Magnetic resonance imaging of fetal and neonatal brains reveals rapid neurodevelopment marked by substantial anatomical changes unfolding within days. Studying this critical stage of the developing human brain, therefore, requires accurate brain models-referred to as atlases-of high spatial and temporal resolution. To meet these demands, established traditional atlases and recently proposed deep learning-based methods rely on large and comprehensive datasets. This poses a major challenge for studying brains in the presence of pathologies for which data remains scarce. We address this limitation with CINeMA (Conditional Implicit Neural Multi-Modal Atlas), a novel framework for creating high-resolution, spatio-temporal, multimodal brain atlases, suitable for low-data settings. Unlike established methods, CINeMA operates in latent space, avoiding compute-intensive image registration and reducing atlas construction times from days to minutes. Furthermore, it enables flexible conditioning on anatomical features including GA, birth age, and pathologies like ventriculomegaly (VM) and agenesis of the corpus callosum (ACC). CINeMA supports downstream tasks such as tissue segmentation and age prediction whereas its generative properties enable synthetic data creation and anatomically informed data augmentation. Surpassing state-of-the-art methods in accuracy, efficiency, and versatility, CINeMA represents a powerful tool for advancing brain research. We release the code and atlases at https://github.com/m-dannecker/CINeMA.
Self-supervised feature learning for cardiac Cine MR image reconstruction
May 29, 2025We propose a self-supervised feature learning assisted reconstruction (SSFL-Recon) framework for MRI reconstruction to address the limitation of existing supervised learning methods. Although recent deep learning-based methods have shown promising performance in MRI reconstruction, most require fully-sampled images for supervised learning, which is challenging in practice considering long acquisition times under respiratory or organ motion. Moreover, nearly all fully-sampled datasets are obtained from conventional reconstruction of mildly accelerated datasets, thus potentially biasing the achievable performance. The numerous undersampled datasets with different accelerations in clinical practice, hence, remain underutilized. To address these issues, we first train a self-supervised feature extractor on undersampled images to learn sampling-insensitive features. The pre-learned features are subsequently embedded in the self-supervised reconstruction network to assist in removing artifacts. Experiments were conducted retrospectively on an in-house 2D cardiac Cine dataset, including 91 cardiovascular patients and 38 healthy subjects. The results demonstrate that the proposed SSFL-Recon framework outperforms existing self-supervised MRI reconstruction methods and even exhibits comparable or better performance to supervised learning up to $16\times$ retrospective undersampling. The feature learning strategy can effectively extract global representations, which have proven beneficial in removing artifacts and increasing generalization ability during reconstruction.
Beyond Distillation: Pushing the Limits of Medical LLM Reasoning with Minimalist Rule-Based RL
May 23, 2025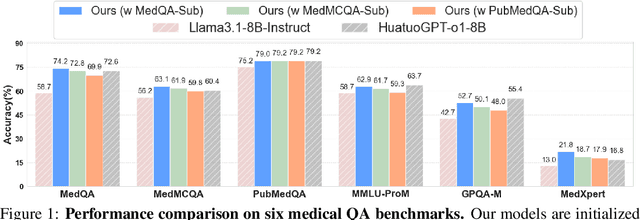
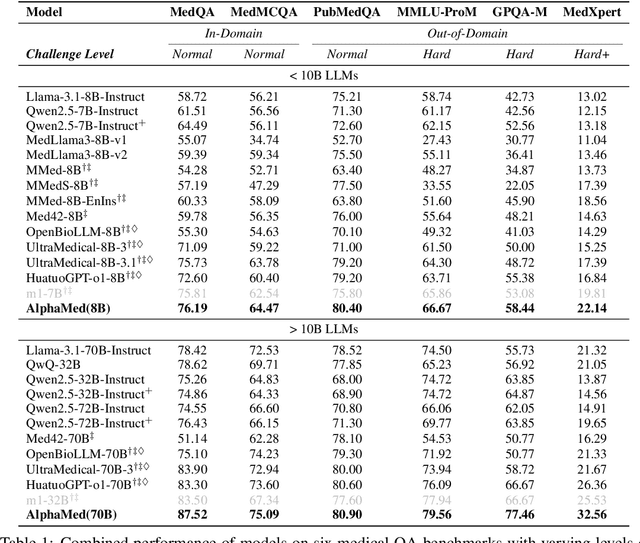
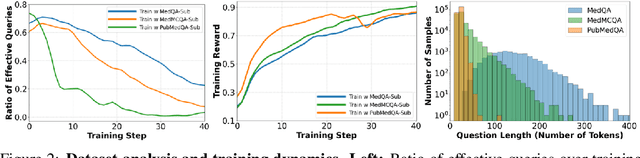

Improving performance on complex tasks and enabling interpretable decision making in large language models (LLMs), especially for clinical applications, requires effective reasoning. Yet this remains challenging without supervised fine-tuning (SFT) on costly chain-of-thought (CoT) data distilled from closed-source models (e.g., GPT-4o). In this work, we present AlphaMed, the first medical LLM to show that reasoning capability can emerge purely through reinforcement learning (RL), using minimalist rule-based rewards on public multiple-choice QA datasets, without relying on SFT or distilled CoT data. AlphaMed achieves state-of-the-art results on six medical QA benchmarks, outperforming models trained with conventional SFT+RL pipelines. On challenging benchmarks (e.g., MedXpert), AlphaMed even surpasses larger or closed-source models such as DeepSeek-V3-671B and Claude-3.5-Sonnet. To understand the factors behind this success, we conduct a comprehensive data-centric analysis guided by three questions: (i) Can minimalist rule-based RL incentivize reasoning without distilled CoT supervision? (ii) How do dataset quantity and diversity impact reasoning? (iii) How does question difficulty shape the emergence and generalization of reasoning? Our findings show that dataset informativeness is a key driver of reasoning performance, and that minimalist RL on informative, multiple-choice QA data is effective at inducing reasoning without CoT supervision. We also observe divergent trends across benchmarks, underscoring limitations in current evaluation and the need for more challenging, reasoning-oriented medical QA benchmarks.
Laplace Sample Information: Data Informativeness Through a Bayesian Lens
May 21, 2025



Accurately estimating the informativeness of individual samples in a dataset is an important objective in deep learning, as it can guide sample selection, which can improve model efficiency and accuracy by removing redundant or potentially harmful samples. We propose Laplace Sample Information (LSI) measure of sample informativeness grounded in information theory widely applicable across model architectures and learning settings. LSI leverages a Bayesian approximation to the weight posterior and the KL divergence to measure the change in the parameter distribution induced by a sample of interest from the dataset. We experimentally show that LSI is effective in ordering the data with respect to typicality, detecting mislabeled samples, measuring class-wise informativeness, and assessing dataset difficulty. We demonstrate these capabilities of LSI on image and text data in supervised and unsupervised settings. Moreover, we show that LSI can be computed efficiently through probes and transfers well to the training of large models.
Meta-learning Slice-to-Volume Reconstruction in Fetal Brain MRI using Implicit Neural Representations
May 14, 2025



High-resolution slice-to-volume reconstruction (SVR) from multiple motion-corrupted low-resolution 2D slices constitutes a critical step in image-based diagnostics of moving subjects, such as fetal brain Magnetic Resonance Imaging (MRI). Existing solutions struggle with image artifacts and severe subject motion or require slice pre-alignment to achieve satisfying reconstruction performance. We propose a novel SVR method to enable fast and accurate MRI reconstruction even in cases of severe image and motion corruption. Our approach performs motion correction, outlier handling, and super-resolution reconstruction with all operations being entirely based on implicit neural representations. The model can be initialized with task-specific priors through fully self-supervised meta-learning on either simulated or real-world data. In extensive experiments including over 480 reconstructions of simulated and clinical MRI brain data from different centers, we prove the utility of our method in cases of severe subject motion and image artifacts. Our results demonstrate improvements in reconstruction quality, especially in the presence of severe motion, compared to state-of-the-art methods, and up to 50% reduction in reconstruction time.
Automated Thoracolumbar Stump Rib Detection and Analysis in a Large CT Cohort
May 08, 2025



Thoracolumbar stump ribs are one of the essential indicators of thoracolumbar transitional vertebrae or enumeration anomalies. While some studies manually assess these anomalies and describe the ribs qualitatively, this study aims to automate thoracolumbar stump rib detection and analyze their morphology quantitatively. To this end, we train a high-resolution deep-learning model for rib segmentation and show significant improvements compared to existing models (Dice score 0.997 vs. 0.779, p-value < 0.01). In addition, we use an iterative algorithm and piece-wise linear interpolation to assess the length of the ribs, showing a success rate of 98.2%. When analyzing morphological features, we show that stump ribs articulate more posteriorly at the vertebrae (-19.2 +- 3.8 vs -13.8 +- 2.5, p-value < 0.01), are thinner (260.6 +- 103.4 vs. 563.6 +- 127.1, p-value < 0.01), and are oriented more downwards and sideways within the first centimeters in contrast to full-length ribs. We show that with partially visible ribs, these features can achieve an F1-score of 0.84 in differentiating stump ribs from regular ones. We publish the model weights and masks for public use.