 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-body CT attenuation and volume charts from routine clinical scans via evidence-grounded LLM report filtering
May 07, 2026Interpreting quantitative CT biomarkers, such as organ volume and tissue attenuation, requires large-scale healthy reference distributions. However, creating these is challenging because clinical datasets are often heavily enriched with pathology. Here, we develop an evidence-grounded, cross-verified large language model (LLM) ensemble to filter pathological findings from radiology reports, enabling the construction of pathology-reduced cohorts from over 350,000 CT examinations. Five LLMs, first, flag structure-level abnormality candidates grounded in verbatim report evidence and, second, resolve disagreements via cross-verification. Using distribution-aware generalized additive models for location, scale, and shape, we establish comprehensive whole-body reference charts for 106 anatomical structures (volumes and attenuation) across adulthood, accounting for age, sex, contrast enhancement, and acquisition parameters. Longitudinal analyses reveal structure- and contrast-dependent changes distinct from cross-sectional trends. These resources facilitate covariate-adjusted centile scoring from routine CT, supporting standardized quantitative phenotyping, multi-site imaging studies, and scalable opportunistic screening research.
Agentic clinical reasoning over longitudinal myeloma records: a retrospective evaluation against expert consensus
Apr 27, 2026Multiple myeloma is managed through sequential lines of therapy over years to decades, with each decision depending on cumulative disease history distributed across dozens to hundreds of heterogeneous clinical documents. Whether LLM-based systems can synthesise this evidence at a level approaching expert agreement has not been established. A retrospective evaluation was conducted on longitudinal clinical records of 811 myeloma patients treated at a tertiary centre (2001-2026), covering 44,962 documents and 1,334,677 laboratory values, with external validation on MIMIC-IV. An agentic reasoning system was compared against single-pass retrieval-augmented generation (RAG), iterative RAG, and full-context input on 469 patient-question pairs from 48 templates at three complexity levels. Reference labels came from double annotation by four oncologists with senior haematologist adjudication. Iterative RAG and full-context input converged on a shared ceiling (75.4% vs 75.8%, p = 1.00). The agentic system reached 79.6% concordance (95% CI 76.4-82.8), exceeding both baselines (+3.8 and +4.2 pp; p = 0.006 and 0.007). Gains rose with question complexity, reaching +9.4 pp on criteria-based synthesis (p = 0.032), and with record length, reaching +13.5 pp in the top decile (n = 10). The system error rate (12.2%) was comparable to expert disagreement (13.6%), but severity was inverted: 57.8% of system errors were clinically significant versus 18.8% of expert disagreements. Agentic reasoning was the only approach to exceed the shared ceiling, with gains concentrated on the most complex questions and longest records. The greater clinical consequence of residual system errors indicates that prospective evaluation in routine care is required before these findings translate into patient benefit.
Conditional Diffusion for 3D CT Volume Reconstruction from 2D X-rays
Mar 27, 2026Computed tomography (CT) provides rich 3D anatomical details but is often constrained by high radiation exposure, substantial costs, and limited availability. While standard chest X-rays are cost-effective and widely accessible, they only provide 2D projections with limited pathological information. Reconstructing 3D CT volumes from 2D X-rays offers a transformative solution to increase diagnostic accessibility, yet existing methods predominantly rely on synthetic X-ray projections, limiting clinical generalization. In this work, we propose AXON, a multi-stage diffusion-based framework that reconstructs high-fidelity 3D CT volumes directly from real X-rays. AXON employs a coarse-to-fine strategy, with a Brownian Bridge diffusion model-based initial stage for global structural synthesis, followed by a ControlNet-based refinement stage for local intensity optimization. It also supports bi-planar X-ray input to mitigate depth ambiguities inherent in 2D-to-3D reconstruction. A super-resolution network is integrated to upscale the generated volumes to achieve diagnostic-grade resolution. Evaluations on both public and external datasets demonstrate that AXON significantly outperforms state-of-the-art baselines, achieving a 11.9% improvement in PSNR and a 11.0% increase in SSIM with robust generalizability across disparate clinical distributions. Our code is available at https://github.com/ai-med/AXON.
Parametric shape models for vessels learned from segmentations via differentiable voxelization
Jul 03, 2025Vessels are complex structures in the body that have been studied extensively in multiple representations. While voxelization is the most common of them, meshes and parametric models are critical in various applications due to their desirable properties. However, these representations are typically extracted through segmentations and used disjointly from each other. We propose a framework that joins the three representations under differentiable transformations. By leveraging differentiable voxelization, we automatically extract a parametric shape model of the vessels through shape-to-segmentation fitting, where we learn shape parameters from segmentations without the explicit need for ground-truth shape parameters. The vessel is parametrized as centerlines and radii using cubic B-splines, ensuring smoothness and continuity by construction. Meshes are differentiably extracted from the learned shape parameters, resulting in high-fidelity meshes that can be manipulated post-fit. Our method can accurately capture the geometry of complex vessels, as demonstrated by the volumetric fits in experiments on aortas, aneurysms, and brain vessels.
From Text to Image: Exploring GPT-4Vision's Potential in Advanced Radiological Analysis across Subspecialties
Nov 24, 2023

The study evaluates and compares GPT-4 and GPT-4Vision for radiological tasks, suggesting GPT-4Vision may recognize radiological features from images, thereby enhancing its diagnostic potential over text-based descriptions.
Evaluation of GPT-4 for chest X-ray impression generation: A reader study on performance and perception
Nov 12, 2023



The remarkable generative capabilities of multimodal foundation models are currently being explored for a variety of applications. Generating radiological impressions is a challenging task that could significantly reduce the workload of radiologists. In our study we explored and analyzed the generative abilities of GPT-4 for Chest X-ray impression generation. To generate and evaluate impressions of chest X-rays based on different input modalities (image, text, text and image), a blinded radiological report was written for 25-cases of the publicly available NIH-dataset. GPT-4 was given image, finding section or both sequentially to generate an input dependent impression. In a blind randomized reading, 4-radiologists rated the impressions and were asked to classify the impression origin (Human, AI), providing justification for their decision. Lastly text model evaluation metrics and their correlation with the radiological score (summation of the 4 dimensions) was assessed. According to the radiological score, the human-written impression was rated highest, although not significantly different to text-based impressions. The automated evaluation metrics showed moderate to substantial correlations to the radiological score for the image impressions, however individual scores were highly divergent among inputs, indicating insufficient representation of radiological quality. Detection of AI-generated impressions varied by input and was 61% for text-based impressions. Impressions classified as AI-generated had significantly worse radiological scores even when written by a radiologist, indicating potential bias. Our study revealed significant discrepancies between a radiological assessment and common automatic evaluation metrics depending on the model input. The detection of AI-generated findings is subject to bias that highly rated impressions are perceived as human-written.
Private, fair and accurate: Training large-scale, privacy-preserving AI models in radiology
Feb 03, 2023Artificial intelligence (AI) models are increasingly used in the medical domain. However, as medical data is highly sensitive, special precautions to ensure the protection of said data are required. The gold standard for privacy preservation is the introduction of differential privacy (DP) to model training. However, prior work has shown that DP has negative implications on model accuracy and fairness. Therefore, the purpose of this study is to demonstrate that the privacy-preserving training of AI models for chest radiograph diagnosis is possible with high accuracy and fairness compared to non-private training. N=193,311 high quality clinical chest radiographs were retrospectively collected and manually labeled by experienced radiologists, who assigned one or more of the following diagnoses: cardiomegaly, congestion, pleural effusion, pneumonic infiltration and atelectasis, to each side (where applicable). The non-private AI models were compared with privacy-preserving (DP) models with respect to privacy-utility trade-offs (measured as area under the receiver-operator-characteristic curve (AUROC)), and privacy-fairness trade-offs (measured as Pearson-R or Statistical Parity Difference). The non-private AI model achieved an average AUROC score of 0.90 over all labels, whereas the DP AI model with a privacy budget of epsilon=7.89 resulted in an AUROC of 0.87, i.e., a mere 2.6% performance decrease compared to non-private training. The privacy-preserving training of diagnostic AI models can achieve high performance with a small penalty on model accuracy and does not amplify discrimination against age, sex or co-morbidity. We thus encourage practitioners to integrate state-of-the-art privacy-preserving techniques into medical AI model development.
Longitudinal Self-Supervision for COVID-19 Pathology Quantification
Mar 21, 2022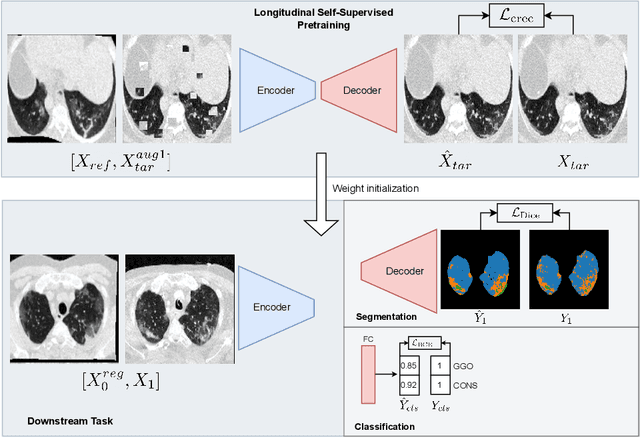
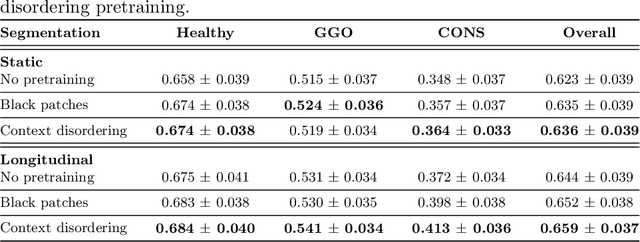
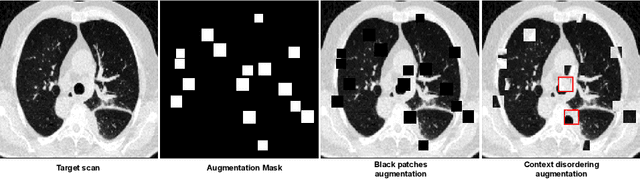

Quantifying COVID-19 infection over time is an important task to manage the hospitalization of patients during a global pandemic. Recently, deep learning-based approaches have been proposed to help radiologists automatically quantify COVID-19 pathologies on longitudinal CT scans. However, the learning process of deep learning methods demands extensive training data to learn the complex characteristics of infected regions over longitudinal scans. It is challenging to collect a large-scale dataset, especially for longitudinal training. In this study, we want to address this problem by proposing a new self-supervised learning method to effectively train longitudinal networks for the quantification of COVID-19 infections. For this purpose, longitudinal self-supervision schemes are explored on clinical longitudinal COVID-19 CT scans. Experimental results show that the proposed method is effective, helping the model better exploit the semantics of longitudinal data and improve two COVID-19 quantification tasks.
Interactive Segmentation for COVID-19 Infection Quantification on Longitudinal CT scans
Oct 03, 2021
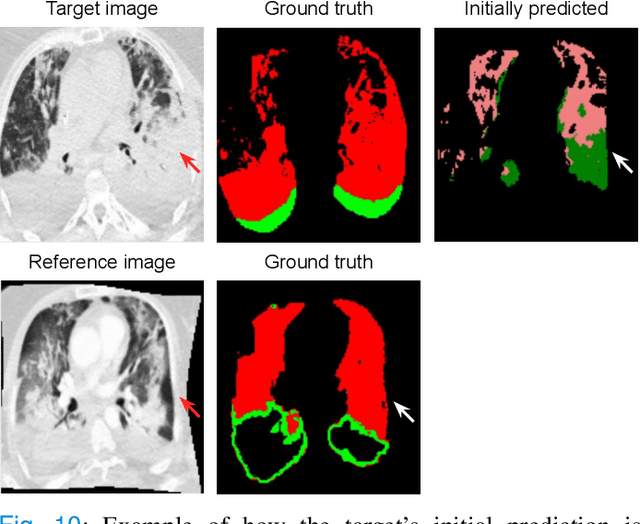
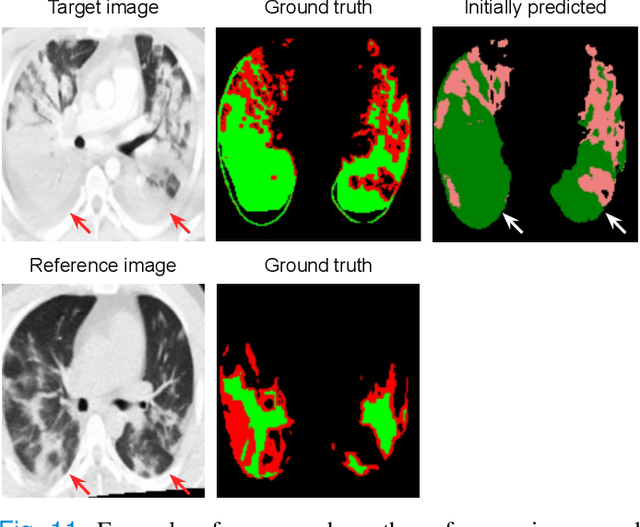
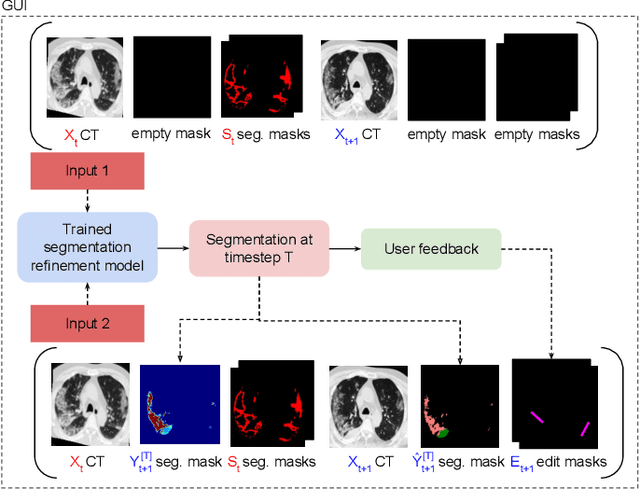
Consistent segmentation of COVID-19 patient's CT scans across multiple time points is essential to assess disease progression and response to therapy accurately. Existing automatic and interactive segmentation models for medical images only use data from a single time point (static). However, valuable segmentation information from previous time points is often not used to aid the segmentation of a patient's follow-up scans. Also, fully automatic segmentation techniques frequently produce results that would need further editing for clinical use. In this work, we propose a new single network model for interactive segmentation that fully utilizes all available past information to refine the segmentation of follow-up scans. In the first segmentation round, our model takes 3D volumes of medical images from two-time points (target and reference) as concatenated slices with the additional reference time point segmentation as a guide to segment the target scan. In subsequent segmentation refinement rounds, user feedback in the form of scribbles that correct the segmentation and the target's previous segmentation results are additionally fed into the model. This ensures that the segmentation information from previous refinement rounds is retained. Experimental results on our in-house multiclass longitudinal COVID-19 dataset show that the proposed model outperforms its static version and can assist in localizing COVID-19 infections in patient's follow-up scans.
Sensitivity analysis in differentially private machine learning using hybrid automatic differentiation
Jul 09, 2021In recent years, formal methods of privacy protection such as differential privacy (DP), capable of deployment to data-driven tasks such as machine learning (ML), have emerged. Reconciling large-scale ML with the closed-form reasoning required for the principled analysis of individual privacy loss requires the introduction of new tools for automatic sensitivity analysis and for tracking an individual's data and their features through the flow of computation. For this purpose, we introduce a novel \textit{hybrid} automatic differentiation (AD) system which combines the efficiency of reverse-mode AD with an ability to obtain a closed-form expression for any given quantity in the computational graph. This enables modelling the sensitivity of arbitrary differentiable function compositions, such as the training of neural networks on private data. We demonstrate our approach by analysing the individual DP guarantees of statistical database queries. Moreover, we investigate the application of our technique to the training of DP neural networks. Our approach can enable the principled reasoning about privacy loss in the setting of data processing, and further the development of automatic sensitivity analysis and privacy budgeting systems.