 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Thoracolumbar Stump Rib Detection and Analysis in a Large CT Cohort
May 08, 2025



Thoracolumbar stump ribs are one of the essential indicators of thoracolumbar transitional vertebrae or enumeration anomalies. While some studies manually assess these anomalies and describe the ribs qualitatively, this study aims to automate thoracolumbar stump rib detection and analyze their morphology quantitatively. To this end, we train a high-resolution deep-learning model for rib segmentation and show significant improvements compared to existing models (Dice score 0.997 vs. 0.779, p-value < 0.01). In addition, we use an iterative algorithm and piece-wise linear interpolation to assess the length of the ribs, showing a success rate of 98.2%. When analyzing morphological features, we show that stump ribs articulate more posteriorly at the vertebrae (-19.2 +- 3.8 vs -13.8 +- 2.5, p-value < 0.01), are thinner (260.6 +- 103.4 vs. 563.6 +- 127.1, p-value < 0.01), and are oriented more downwards and sideways within the first centimeters in contrast to full-length ribs. We show that with partially visible ribs, these features can achieve an F1-score of 0.84 in differentiating stump ribs from regular ones. We publish the model weights and masks for public use.
Physiology-based simulation of the retinal vasculature enables annotation-free segmentation of OCT angiographs
Jul 22, 2022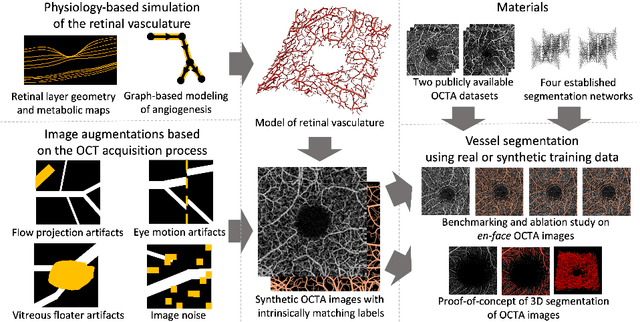
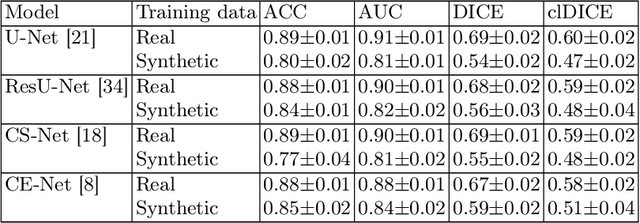
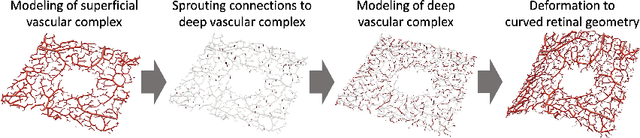
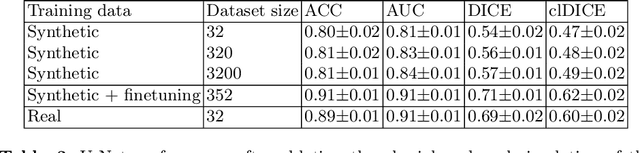
Optical coherence tomography angiography (OCTA) can non-invasively image the eye's circulatory system. In order to reliably characterize the retinal vasculature, there is a need to automatically extract quantitative metrics from these images. The calculation of such biomarkers requires a precise semantic segmentation of the blood vessels. However, deep-learning-based methods for segmentation mostly rely on supervised training with voxel-level annotations, which are costly to obtain. In this work, we present a pipeline to synthesize large amounts of realistic OCTA images with intrinsically matching ground truth labels; thereby obviating the need for manual annotation of training data. Our proposed method is based on two novel components: 1) a physiology-based simulation that models the various retinal vascular plexuses and 2) a suite of physics-based image augmentations that emulate the OCTA image acquisition process including typical artifacts. In extensive benchmarking experiments, we demonstrate the utility of our synthetic data by successfully training retinal vessel segmentation algorithms. Encouraged by our method's competitive quantitative and superior qualitative performance, we believe that it constitutes a versatile tool to advance the quantitative analysis of OCTA images.