 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Haystack: Smaller Needles are More Difficult for LLMs to Find
May 23, 2025



Large language models (LLMs) face significant challenges with needle-in-a-haystack tasks, where relevant information ("the needle") must be drawn from a large pool of irrelevant context ("the haystack"). Previous studies have highlighted positional bias and distractor quantity as critical factors affecting model performance, yet the influence of gold context size has received little attention. We address this gap by systematically studying how variations in gold context length impact LLM performance on long-context question answering tasks. Our experiments reveal that LLM performance drops sharply when the gold context is shorter, i.e., smaller gold contexts consistently degrade model performance and amplify positional sensitivity, posing a major challenge for agentic systems that must integrate scattered, fine-grained information of varying lengths. This pattern holds across three diverse domains (general knowledge, biomedical reasoning, and mathematical reasoning) and seven state-of-the-art LLMs of various sizes and architectures. Our work provides clear insights to guide the design of robust, context-aware LLM-driven systems.
SIMPLEMIX: Frustratingly Simple Mixing of Off- and On-policy Data in Language Model Preference Learning
May 05, 2025Aligning language models with human preferences relies on pairwise preference datasets. While some studies suggest that on-policy data consistently outperforms off -policy data for preference learning, others indicate that the advantages of on-policy data may be task-dependent, highlighting the need for a systematic exploration of their interplay. In this work, we show that on-policy and off-policy data offer complementary strengths in preference optimization: on-policy data is particularly effective for reasoning tasks like math and coding, while off-policy data performs better on open-ended tasks such as creative writing and making personal recommendations. Guided by these findings, we introduce SIMPLEMIX, an approach to combine the complementary strengths of on-policy and off-policy preference learning by simply mixing these two data sources. Our empirical results across diverse tasks and benchmarks demonstrate that SIMPLEMIX substantially improves language model alignment. Specifically, SIMPLEMIX improves upon on-policy DPO and off-policy DPO by an average of 6.03% on Alpaca Eval 2.0. Moreover, it outperforms prior approaches that are much more complex in combining on- and off-policy data, such as HyPO and DPO-Mix-P, by an average of 3.05%.
ICL CIPHERS: Quantifying "Learning'' in In-Context Learning via Substitution Ciphers
Apr 28, 2025Recent works have suggested that In-Context Learning (ICL) operates in dual modes, i.e. task retrieval (remember learned patterns from pre-training) and task learning (inference-time ``learning'' from demonstrations). However, disentangling these the two modes remains a challenging goal. We introduce ICL CIPHERS, a class of task reformulations based on substitution ciphers borrowed from classic cryptography. In this approach, a subset of tokens in the in-context inputs are substituted with other (irrelevant) tokens, rendering English sentences less comprehensible to human eye. However, by design, there is a latent, fixed pattern to this substitution, making it reversible. This bijective (reversible) cipher ensures that the task remains a well-defined task in some abstract sense, despite the transformations. It is a curious question if LLMs can solve ICL CIPHERS with a BIJECTIVE mapping, which requires deciphering the latent cipher. We show that LLMs are better at solving ICL CIPHERS with BIJECTIVE mappings than the NON-BIJECTIVE (irreversible) baseline, providing a novel approach to quantify ``learning'' in ICL. While this gap is small, it is consistent across the board on four datasets and six models. Finally, we examine LLMs' internal representations and identify evidence in their ability to decode the ciphered inputs.
Certified Mitigation of Worst-Case LLM Copyright Infringement
Apr 22, 2025

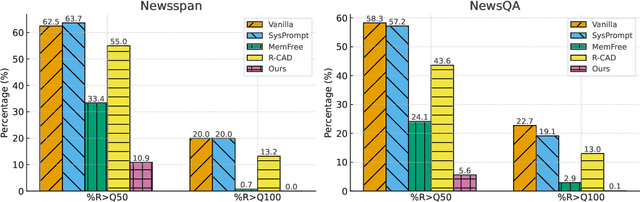
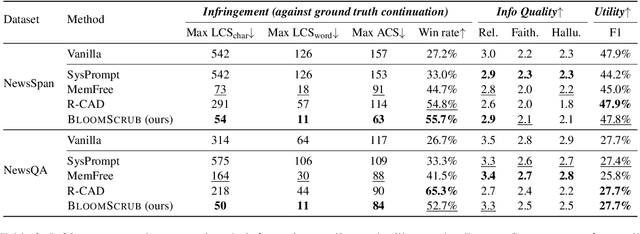
The exposure of large language models (LLMs) to copyrighted material during pre-training raises concerns about unintentional copyright infringement post deployment. This has driven the development of "copyright takedown" methods, post-training approaches aimed at preventing models from generating content substantially similar to copyrighted ones. While current mitigation approaches are somewhat effective for average-case risks, we demonstrate that they overlook worst-case copyright risks exhibits by the existence of long, verbatim quotes from copyrighted sources. We propose BloomScrub, a remarkably simple yet highly effective inference-time approach that provides certified copyright takedown. Our method repeatedly interleaves quote detection with rewriting techniques to transform potentially infringing segments. By leveraging efficient data sketches (Bloom filters), our approach enables scalable copyright screening even for large-scale real-world corpora. When quotes beyond a length threshold cannot be removed, the system can abstain from responding, offering certified risk reduction. Experimental results show that BloomScrub reduces infringement risk, preserves utility, and accommodates different levels of enforcement stringency with adaptive abstention. Our results suggest that lightweight, inference-time methods can be surprisingly effective for copyright prevention.
Science Hierarchography: Hierarchical Organization of Science Literature
Apr 18, 2025



Scientific knowledge is growing rapidly, making it challenging to track progress and high-level conceptual links across broad disciplines. While existing tools like citation networks and search engines make it easy to access a few related papers, they fundamentally lack the flexible abstraction needed to represent the density of activity in various scientific subfields. We motivate SCIENCE HIERARCHOGRAPHY, the goal of organizing scientific literature into a high-quality hierarchical structure that allows for the categorization of scientific work across varying levels of abstraction, from very broad fields to very specific studies. Such a representation can provide insights into which fields are well-explored and which are under-explored. To achieve the goals of SCIENCE HIERARCHOGRAPHY, we develop a range of algorithms. Our primary approach combines fast embedding-based clustering with LLM-based prompting to balance the computational efficiency of embedding methods with the semantic precision offered by LLM prompting. We demonstrate that this approach offers the best trade-off between quality and speed compared to methods that heavily rely on LLM prompting, such as iterative tree construction with LLMs. To better reflect the interdisciplinary and multifaceted nature of research papers, our hierarchy captures multiple dimensions of categorization beyond simple topic labels. We evaluate the utility of our framework by assessing how effectively an LLM-based agent can locate target papers using the hierarchy. Results show that this structured approach enhances interpretability, supports trend discovery, and offers an alternative pathway for exploring scientific literature beyond traditional search methods. Code, data and demo: $\href{https://github.com/JHU-CLSP/science-hierarchography}{https://github.com/JHU-CLSP/science-hierarchography}$
Can LLMs Generate Tabular Summaries of Science Papers? Rethinking the Evaluation Protocol
Apr 14, 2025



Literature review tables are essential for summarizing and comparing collections of scientific papers. We explore the task of generating tables that best fulfill a user's informational needs given a collection of scientific papers. Building on recent work (Newman et al., 2024), we extend prior approaches to address real-world complexities through a combination of LLM-based methods and human annotations. Our contributions focus on three key challenges encountered in real-world use: (i) User prompts are often under-specified; (ii) Retrieved candidate papers frequently contain irrelevant content; and (iii) Task evaluation should move beyond shallow text similarity techniques and instead assess the utility of inferred tables for information-seeking tasks (e.g., comparing papers). To support reproducible evaluation, we introduce ARXIV2TABLE, a more realistic and challenging benchmark for this task, along with a novel approach to improve literature review table generation in real-world scenarios. Our extensive experiments on this benchmark show that both open-weight and proprietary LLMs struggle with the task, highlighting its difficulty and the need for further advancements. Our dataset and code are available at https://github.com/JHU-CLSP/arXiv2Table.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025



A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
Can A Society of Generative Agents Simulate Human Behavior and Inform Public Health Policy? A Case Study on Vaccine Hesitancy
Mar 12, 2025Can we simulate a sandbox society with generative agents to model human behavior, thereby reducing the over-reliance on real human trials for assessing public policies? In this work, we investigate the feasibility of simulating health-related decision-making, using vaccine hesitancy, defined as the delay in acceptance or refusal of vaccines despite the availability of vaccination services (MacDonald, 2015), as a case study. To this end, we introduce the VacSim framework with 100 generative agents powered by Large Language Models (LLMs). VacSim simulates vaccine policy outcomes with the following steps: 1) instantiate a population of agents with demographics based on census data; 2) connect the agents via a social network and model vaccine attitudes as a function of social dynamics and disease-related information; 3) design and evaluate various public health interventions aimed at mitigating vaccine hesitancy. To align with real-world results, we also introduce simulation warmup and attitude modulation to adjust agents' attitudes. We propose a series of evaluations to assess the reliability of various LLM simulations. Experiments indicate that models like Llama and Qwen can simulate aspects of human behavior but also highlight real-world alignment challenges, such as inconsistent responses with demographic profiles. This early exploration of LLM-driven simulations is not meant to serve as definitive policy guidance; instead, it serves as a call for action to examine social simulation for policy development.
GenEx: Generating an Explorable World
Dec 12, 2024



Understanding, navigating, and exploring the 3D physical real world has long been a central challenge in the development of artificial intelligence. In this work, we take a step toward this goal by introducing GenEx, a system capable of planning complex embodied world exploration, guided by its generative imagination that forms priors (expectations) about the surrounding environments. GenEx generates an entire 3D-consistent imaginative environment from as little as a single RGB image, bringing it to life through panoramic video streams. Leveraging scalable 3D world data curated from Unreal Engine, our generative model is rounded in the physical world. It captures a continuous 360-degree environment with little effort, offering a boundless landscape for AI agents to explore and interact with. GenEx achieves high-quality world generation, robust loop consistency over long trajectories, and demonstrates strong 3D capabilities such as consistency and active 3D mapping. Powered by generative imagination of the world, GPT-assisted agents are equipped to perform complex embodied tasks, including both goal-agnostic exploration and goal-driven navigation. These agents utilize predictive expectation regarding unseen parts of the physical world to refine their beliefs, simulate different outcomes based on potential decisions, and make more informed choices. In summary, we demonstrate that GenEx provides a transformative platform for advancing embodied AI in imaginative spaces and brings potential for extending these capabilities to real-world exploration.
Generative World Explorer
Nov 19, 2024



Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. In contrast, humans can $\textit{imagine}$ unseen parts of the world through a mental exploration and $\textit{revise}$ their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions, without necessitating the physical exploration of the world at all times. To achieve this human-like ability, we introduce the $\textit{Generative World Explorer (Genex)}$, an egocentric world exploration framework that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief. This updated belief will then help the agent to make a more informed decision at the current step. To train $\textit{Genex}$, we create a synthetic urban scene dataset, Genex-DB. Our experimental results demonstrate that (1) $\textit{Genex}$ can generate high-quality and consistent observations during long-horizon exploration of a large virtual physical world and (2) the beliefs updated with the generated observations can inform an existing decision-making model (e.g., an LLM agent) to make better plans.