 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Haystack: Smaller Needles are More Difficult for LLMs to Find
May 23, 2025



Large language models (LLMs) face significant challenges with needle-in-a-haystack tasks, where relevant information ("the needle") must be drawn from a large pool of irrelevant context ("the haystack"). Previous studies have highlighted positional bias and distractor quantity as critical factors affecting model performance, yet the influence of gold context size has received little attention. We address this gap by systematically studying how variations in gold context length impact LLM performance on long-context question answering tasks. Our experiments reveal that LLM performance drops sharply when the gold context is shorter, i.e., smaller gold contexts consistently degrade model performance and amplify positional sensitivity, posing a major challenge for agentic systems that must integrate scattered, fine-grained information of varying lengths. This pattern holds across three diverse domains (general knowledge, biomedical reasoning, and mathematical reasoning) and seven state-of-the-art LLMs of various sizes and architectures. Our work provides clear insights to guide the design of robust, context-aware LLM-driven systems.
GenoML: Automated Machine Learning for Genomics
Mar 04, 2021GenoML is a Python package automating machine learning workflows for genomics (genetics and multi-omics) with an open science philosophy. Genomics data require significant domain expertise to clean, pre-process, harmonize and perform quality control of the data. Furthermore, tuning, validation, and interpretation involve taking into account the biology and possibly the limitations of the underlying data collection, protocols, and technology. GenoML's mission is to bring machine learning for genomics and clinical data to non-experts by developing an easy-to-use tool that automates the full development, evaluation, and deployment process. Emphasis is put on open science to make workflows easily accessible, replicable, and transferable within the scientific community. Source code and documentation is available at https://genoml.com.
Learning the progression and clinical subtypes of Alzheimer's disease from longitudinal clinical data
Dec 06, 2018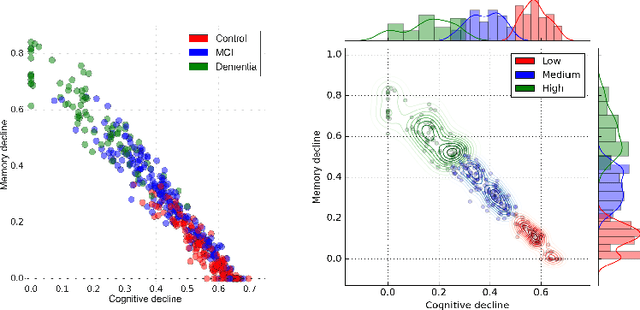
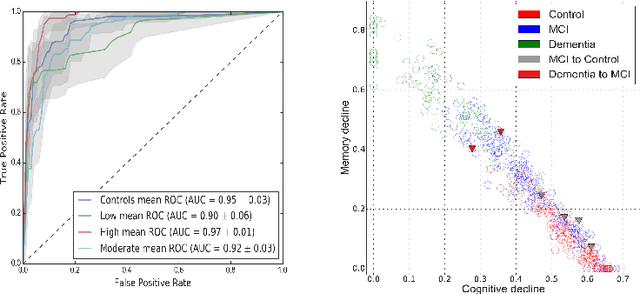
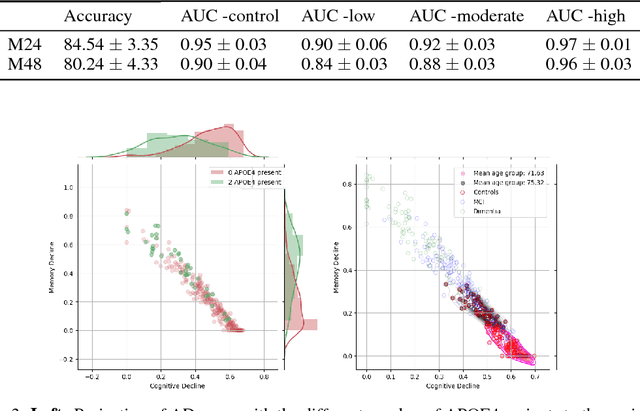
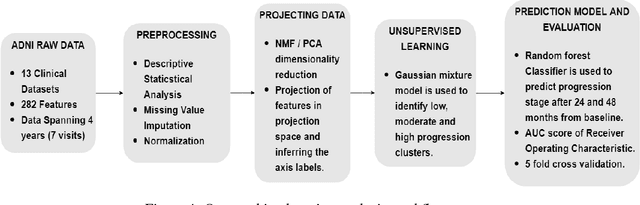
Alzheimer's disease (AD) is a degenerative brain disease impairing a person's ability to perform day to day activities. The clinical manifestations of Alzheimer's disease are characterized by heterogeneity in age, disease span, progression rate, impairment of memory and cognitive abilities. Due to these variabilities, personalized care and treatment planning, as well as patient counseling about their individual progression is limited. Recent developments in machine learning to detect hidden patterns in complex, multi-dimensional datasets provides significant opportunities to address this critical need. In this work, we use unsupervised and supervised machine learning approaches for subtype identification and prediction. We apply machine learning methods to the extensive clinical observations available at the Alzheimer's Disease Neuroimaging Initiative (ADNI) data set to identify patient subtypes and to predict disease progression. Our analysis depicts the progression space for the Alzheimer's disease into low, moderate and high disease progression zones. The proposed work will enable early detection and characterization of distinct disease subtypes based on clinical heterogeneity. We anticipate that our models will enable patient counseling, clinical trial design, and ultimately individualized clinical care.
Toward Scalable Machine Learning and Data Mining: the Bioinformatics Case
Sep 29, 2017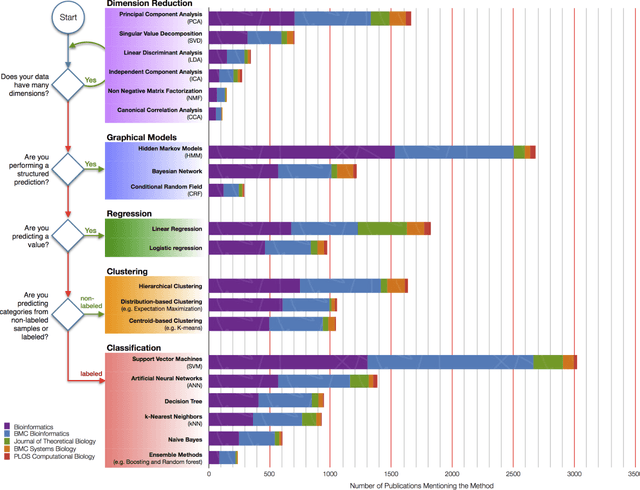
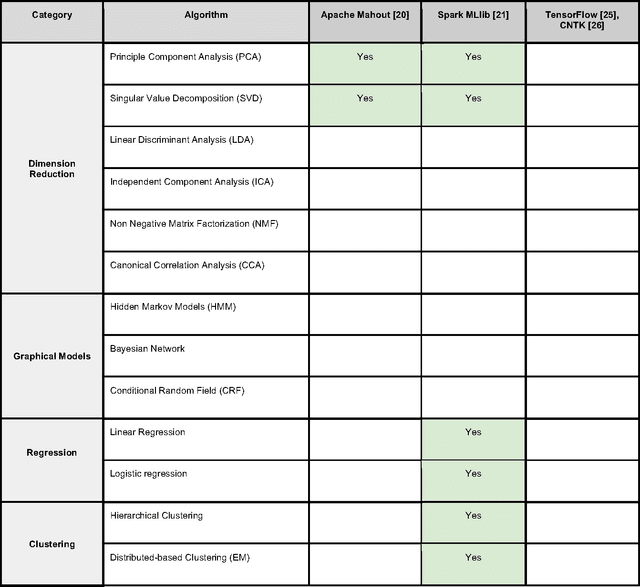
In an effort to overcome the data deluge in computational biology and bioinformatics and to facilitate bioinformatics research in the era of big data, we identify some of the most influential algorithms that have been widely used in the bioinformatics community. These top data mining and machine learning algorithms cover classification, clustering, regression, graphical model-based learning, and dimensionality reduction. The goal of this study is to guide the focus of scalable computing experts in the endeavor of applying new storage and scalable computation designs to bioinformatics algorithms that merit their attention most, following the engineering maxim of "optimize the common case".