 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Interpret Agent Behavior
May 13, 2026Autonomous agents such as Claude Code and Codex now operate for hours or even days. Understanding their runtime behavior has become critical for downstream tasks such as diagnosing inefficiencies, fixing bugs, and ensuring better oversight. A primary way to gain this understanding is analyzing the reasoning trajectories and execution traces these agents generate. Yet such data remains in unstructured natural-language form, making it difficult for humans to interpret at scale. We introduce ACT*ONOMY (a combination of Action and Taxonomy), a taxonomy for describing and analyzing agent behavior at runtime. ACT*ONOMY has two components: (1) the taxonomy itself, developed through Grounded Theory and structured as a three-level hierarchy of 10 actions, 46 subactions, and 120 leaf categories; and (2) an open repository that hosts the living taxonomy, provides an automated analysis pipeline that applies it to agent trajectories analysis, and defines an extension protocol for customization and growth. Our experiments show that ACTONOMY can compare behavioral profiles across agents and characterize a single agent's behavior across diverse trajectories, surfacing patterns indicative of failure modes. By providing a shared vocabulary, ACT*ONOMY helps researchers, agent designers, and end users interpret agent behavior more consistently, enabling better oversight and control.
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Apr 09, 2026Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
Mar 10, 2026Multimodal large language models (MLLMs) can process text presented as images, yet they often perform worse than when the same content is provided as textual tokens. We systematically diagnose this "modality gap" by evaluating seven MLLMs across seven benchmarks in five input modes, spanning both synthetically rendered text and realistic document images from arXiv PDFs to Wikipedia pages. We find that the modality gap is task- and data-dependent. For example, math tasks degrade by over 60 points on synthetic renderings, while natural document images often match or exceed text-mode performance. Rendering choices such as font and resolution are strong confounds, with font alone swinging accuracy by up to 47 percentage points. To understand this, we conduct a grounded-theory error analysis of over 4,000 examples, revealing that image mode selectively amplifies reading errors (calculation and formatting failures) while leaving knowledge and reasoning errors largely unchanged, and that some models exhibit a chain-of-thought reasoning collapse under visual input. Motivated by these findings, we propose a self-distillation method that trains the model on its own pure text reasoning traces paired with image inputs, raising image-mode accuracy on GSM8K from 30.71% to 92.72% and transferring to unseen benchmarks without catastrophic forgetting. Overall, our study provides a systematic understanding of the modality gap and suggests a practical path toward improving visual text understanding in multimodal language models.
FIRE-Bench: Evaluating Agents on the Rediscovery of Scientific Insights
Feb 02, 2026Autonomous agents powered by large language models (LLMs) promise to accelerate scientific discovery end-to-end, but rigorously evaluating their capacity for verifiable discovery remains a central challenge. Existing benchmarks face a trade-off: they either heavily rely on LLM-as-judge evaluations of automatically generated research outputs or optimize convenient yet isolated performance metrics that provide coarse proxies for scientific insight. To address this gap, we introduce FIRE-Bench (Full-cycle Insight Rediscovery Evaluation), a benchmark that evaluates agents through the rediscovery of established findings from recent, high-impact machine learning research. Agents are given only a high-level research question extracted from a published, verified study and must autonomously explore ideas, design experiments, implement code, execute their plans, and derive conclusions supported by empirical evidence. We evaluate a range of state-of-the-art agents with frontier LLMs backbones like gpt-5 on FIRE-Bench. Our results show that full-cycle scientific research remains challenging for current agent systems: even the strongest agents achieve limited rediscovery success (<50 F1), exhibit high variance across runs, and display recurring failure modes in experimental design, execution, and evidence-based reasoning. FIRE-Bench provides a rigorous and diagnostic framework for measuring progress toward reliable agent-driven scientific discovery.
What Is Seen Cannot Be Unseen: The Disruptive Effect of Knowledge Conflict on Large Language Models
Jun 06, 2025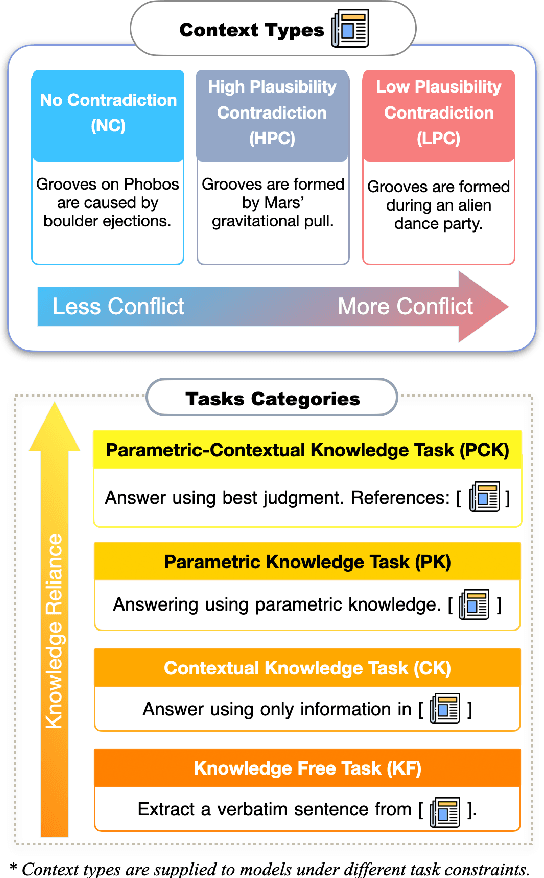



Large language models frequently rely on both contextual input and parametric knowledge to perform tasks. However, these sources can come into conflict, especially when retrieved documents contradict the model's parametric knowledge. We propose a diagnostic framework to systematically evaluate LLM behavior under context-memory conflict, where the contextual information diverges from their parametric beliefs. We construct diagnostic data that elicit these conflicts and analyze model performance across multiple task types. Our findings reveal that (1) knowledge conflict has minimal impact on tasks that do not require knowledge utilization, (2) model performance is consistently higher when contextual and parametric knowledge are aligned, (3) models are unable to fully suppress their internal knowledge even when instructed, and (4) providing rationales that explain the conflict increases reliance on contexts. These insights raise concerns about the validity of model-based evaluation and underscore the need to account for knowledge conflict in the deployment of LLMs.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025



A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
Amuro & Char: Analyzing the Relationship between Pre-Training and Fine-Tuning of Large Language Models
Aug 14, 2024The development of large language models leads to the formation of a pre-train-then-align paradigm, in which the model is typically pre-trained on a large text corpus and undergoes a tuning stage to align the model with human preference or downstream tasks. In this work, we investigate the relationship between pre-training and fine-tuning by fine-tuning multiple intermediate pre-trained model checkpoints. Our results on 18 datasets suggest that i) continual pre-training improves the model in a latent way that unveils after fine-tuning; ii) with extra fine-tuning, the datasets that the model does not demonstrate capability gain much more than those that the model performs well during the pre-training stage; iii) although model benefits significantly through supervised fine-tuning, it may forget previously known domain knowledge and the tasks that are not seen during fine-tuning; iv) the model resembles high sensitivity to evaluation prompts after supervised fine-tuning, but this sensitivity can be alleviated by more pre-training.
The Validity of Evaluation Results: Assessing Concurrence Across Compositionality Benchmarks
Oct 26, 2023



NLP models have progressed drastically in recent years, according to numerous datasets proposed to evaluate performance. Questions remain, however, about how particular dataset design choices may impact the conclusions we draw about model capabilities. In this work, we investigate this question in the domain of compositional generalization. We examine the performance of six modeling approaches across 4 datasets, split according to 8 compositional splitting strategies, ranking models by 18 compositional generalization splits in total. Our results show that: i) the datasets, although all designed to evaluate compositional generalization, rank modeling approaches differently; ii) datasets generated by humans align better with each other than they with synthetic datasets, or than synthetic datasets among themselves; iii) generally, whether datasets are sampled from the same source is more predictive of the resulting model ranking than whether they maintain the same interpretation of compositionality; and iv) which lexical items are used in the data can strongly impact conclusions. Overall, our results demonstrate that much work remains to be done when it comes to assessing whether popular evaluation datasets measure what they intend to measure, and suggest that elucidating more rigorous standards for establishing the validity of evaluation sets could benefit the field.
Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Dec 19, 2022



Generative models have been widely applied to solve extractive tasks, where parts of the input is extracted to form the desired output, and achieved significant success. For example, in extractive question answering (QA), generative models have constantly yielded state-of-the-art results. In this work, we identify the issue of tokenization inconsistency that is commonly neglected in training these models. This issue damages the extractive nature of these tasks after the input and output are tokenized inconsistently by the tokenizer, and thus leads to performance drop as well as hallucination. We propose a simple yet effective fix to this issue and conduct a case study on extractive QA. We show that, with consistent tokenization, the model performs better in both in-domain and out-of-domain datasets, with a notable average of +1.7 F2 gain when a BART model is trained on SQuAD and evaluated on 8 QA datasets. Further, the model converges faster, and becomes less likely to generate out-of-context answers. With these findings, we would like to call for more attention on how tokenization should be done when solving extractive tasks and recommend applying consistent tokenization during training.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022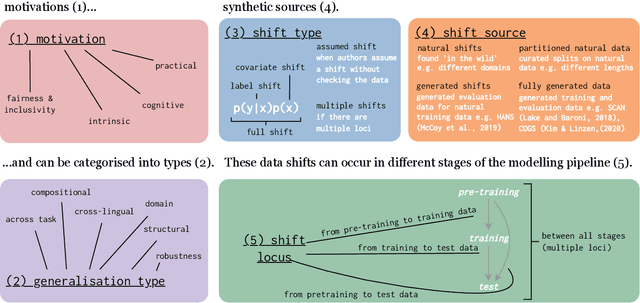
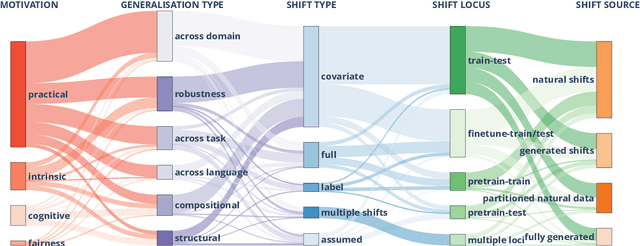
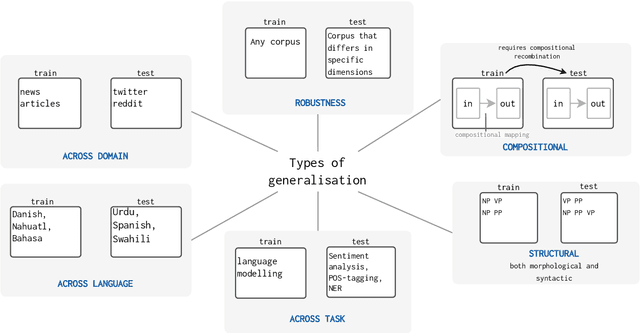

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.