 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive3D: Create What You Want by Interactive 3D Generation
Apr 25, 2024



3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at \url{https://interactive-3d.github.io/}.
GScream: Learning 3D Geometry and Feature Consistent Gaussian Splatting for Object Removal
Apr 21, 2024This paper tackles the intricate challenge of object removal to update the radiance field using the 3D Gaussian Splatting. The main challenges of this task lie in the preservation of geometric consistency and the maintenance of texture coherence in the presence of the substantial discrete nature of Gaussian primitives. We introduce a robust framework specifically designed to overcome these obstacles. The key insight of our approach is the enhancement of information exchange among visible and invisible areas, facilitating content restoration in terms of both geometry and texture. Our methodology begins with optimizing the positioning of Gaussian primitives to improve geometric consistency across both removed and visible areas, guided by an online registration process informed by monocular depth estimation. Following this, we employ a novel feature propagation mechanism to bolster texture coherence, leveraging a cross-attention design that bridges sampling Gaussians from both uncertain and certain areas. This innovative approach significantly refines the texture coherence within the final radiance field. Extensive experiments validate that our method not only elevates the quality of novel view synthesis for scenes undergoing object removal but also showcases notable efficiency gains in training and rendering speeds.
DetCLIPv3: Towards Versatile Generative Open-vocabulary Object Detection
Apr 14, 2024



Existing open-vocabulary object detectors typically require a predefined set of categories from users, significantly confining their application scenarios. In this paper, we introduce DetCLIPv3, a high-performing detector that excels not only at both open-vocabulary object detection, but also generating hierarchical labels for detected objects. DetCLIPv3 is characterized by three core designs: 1. Versatile model architecture: we derive a robust open-set detection framework which is further empowered with generation ability via the integration of a caption head. 2. High information density data: we develop an auto-annotation pipeline leveraging visual large language model to refine captions for large-scale image-text pairs, providing rich, multi-granular object labels to enhance the training. 3. Efficient training strategy: we employ a pre-training stage with low-resolution inputs that enables the object captioner to efficiently learn a broad spectrum of visual concepts from extensive image-text paired data. This is followed by a fine-tuning stage that leverages a small number of high-resolution samples to further enhance detection performance. With these effective designs, DetCLIPv3 demonstrates superior open-vocabulary detection performance, \eg, our Swin-T backbone model achieves a notable 47.0 zero-shot fixed AP on the LVIS minival benchmark, outperforming GLIPv2, GroundingDINO, and DetCLIPv2 by 18.0/19.6/6.6 AP, respectively. DetCLIPv3 also achieves a state-of-the-art 19.7 AP in dense captioning task on VG dataset, showcasing its strong generative capability.
CVT-xRF: Contrastive In-Voxel Transformer for 3D Consistent Radiance Fields from Sparse Inputs
Mar 25, 2024Neural Radiance Fields (NeRF) have shown impressive capabilities for photorealistic novel view synthesis when trained on dense inputs. However, when trained on sparse inputs, NeRF typically encounters issues of incorrect density or color predictions, mainly due to insufficient coverage of the scene causing partial and sparse supervision, thus leading to significant performance degradation. While existing works mainly consider ray-level consistency to construct 2D learning regularization based on rendered color, depth, or semantics on image planes, in this paper we propose a novel approach that models 3D spatial field consistency to improve NeRF's performance with sparse inputs. Specifically, we first adopt a voxel-based ray sampling strategy to ensure that the sampled rays intersect with a certain voxel in 3D space. We then randomly sample additional points within the voxel and apply a Transformer to infer the properties of other points on each ray, which are then incorporated into the volume rendering. By backpropagating through the rendering loss, we enhance the consistency among neighboring points. Additionally, we propose to use a contrastive loss on the encoder output of the Transformer to further improve consistency within each voxel. Experiments demonstrate that our method yields significant improvement over different radiance fields in the sparse inputs setting, and achieves comparable performance with current works.
DiffusionMTL: Learning Multi-Task Denoising Diffusion Model from Partially Annotated Data
Mar 22, 2024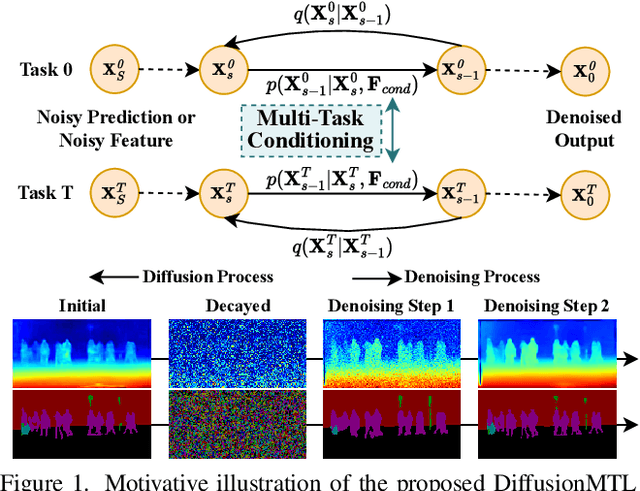
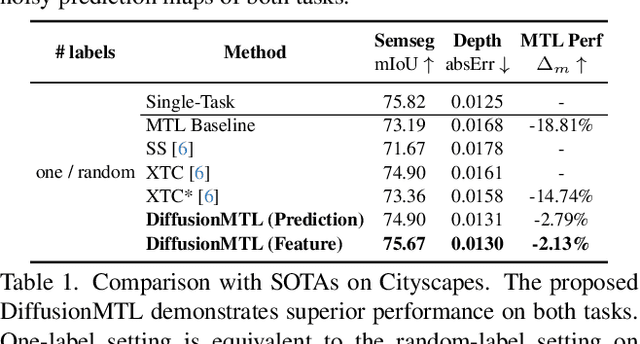
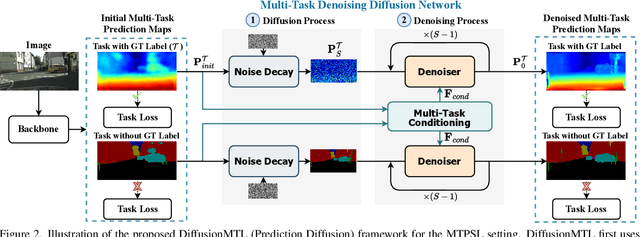
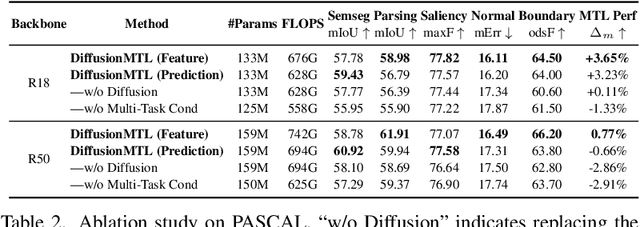
Recently, there has been an increased interest in the practical problem of learning multiple dense scene understanding tasks from partially annotated data, where each training sample is only labeled for a subset of the tasks. The missing of task labels in training leads to low-quality and noisy predictions, as can be observed from state-of-the-art methods. To tackle this issue, we reformulate the partially-labeled multi-task dense prediction as a pixel-level denoising problem, and propose a novel multi-task denoising diffusion framework coined as DiffusionMTL. It designs a joint diffusion and denoising paradigm to model a potential noisy distribution in the task prediction or feature maps and generate rectified outputs for different tasks. To exploit multi-task consistency in denoising, we further introduce a Multi-Task Conditioning strategy, which can implicitly utilize the complementary nature of the tasks to help learn the unlabeled tasks, leading to an improvement in the denoising performance of the different tasks. Extensive quantitative and qualitative experiments demonstrate that the proposed multi-task denoising diffusion model can significantly improve multi-task prediction maps, and outperform the state-of-the-art methods on three challenging multi-task benchmarks, under two different partial-labeling evaluation settings. The code is available at https://prismformore.github.io/diffusionmtl/.
Personalized LoRA for Human-Centered Text Understanding
Mar 10, 2024Effectively and efficiently adapting a pre-trained language model (PLM) for human-centered text understanding (HCTU) is challenging since user tokens are million-level in most personalized applications and do not have concrete explicit semantics. A standard and parameter-efficient approach (e.g., LoRA) necessitates memorizing numerous suits of adapters for each user. In this work, we introduce a personalized LoRA (PLoRA) with a plug-and-play (PnP) framework for the HCTU task. PLoRA is effective, parameter-efficient, and dynamically deploying in PLMs. Moreover, a personalized dropout and a mutual information maximizing strategies are adopted and hence the proposed PLoRA can be well adapted to few/zero-shot learning scenarios for the cold-start issue. Experiments conducted on four benchmark datasets show that the proposed method outperforms existing methods in full/few/zero-shot learning scenarios for the HCTU task, even though it has fewer trainable parameters. For reproducibility, the code for this paper is available at: https://github.com/yoyo-yun/PLoRA.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024



Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors
Dec 07, 2023



Most 3D generation research focuses on up-projecting 2D foundation models into the 3D space, either by minimizing 2D Score Distillation Sampling (SDS) loss or fine-tuning on multi-view datasets. Without explicit 3D priors, these methods often lead to geometric anomalies and multi-view inconsistency. Recently, researchers have attempted to improve the genuineness of 3D objects by directly training on 3D datasets, albeit at the cost of low-quality texture generation due to the limited texture diversity in 3D datasets. To harness the advantages of both approaches, we propose Bidirectional Diffusion(BiDiff), a unified framework that incorporates both a 3D and a 2D diffusion process, to preserve both 3D fidelity and 2D texture richness, respectively. Moreover, as a simple combination may yield inconsistent generation results, we further bridge them with novel bidirectional guidance. In addition, our method can be used as an initialization of optimization-based models to further improve the quality of 3D model and efficiency of optimization, reducing the generation process from 3.4 hours to 20 minutes. Experimental results have shown that our model achieves high-quality, diverse, and scalable 3D generation. Project website: https://bidiff.github.io/.
Implicit Event-RGBD Neural SLAM
Nov 21, 2023Implicit neural SLAM has achieved remarkable progress recently. Nevertheless, existing methods face significant challenges in non-ideal scenarios, such as motion blur or lighting variation, which often leads to issues like convergence failures, localization drifts, and distorted mapping. To address these challenges, we propose $\textbf{EN-SLAM}$, the first event-RGBD implicit neural SLAM framework, which effectively leverages the high rate and high dynamic range advantages of event data for tracking and mapping. Specifically, EN-SLAM proposes a differentiable CRF (Camera Response Function) rendering technique to generate distinct RGB and event camera data via a shared radiance field, which is optimized by learning a unified implicit representation with the captured event and RGBD supervision. Moreover, based on the temporal difference property of events, we propose a temporal aggregating optimization strategy for the event joint tracking and global bundle adjustment, capitalizing on the consecutive difference constraints of events, significantly enhancing tracking accuracy and robustness. Finally, we construct the simulated dataset $\textbf{DEV-Indoors}$ and real captured dataset $\textbf{DEV-Reals}$ containing 6 scenes, 17 sequences with practical motion blur and lighting changes for evaluations. Experimental results show that our method outperforms the SOTA methods in both tracking ATE and mapping ACC with a real-time $17$ FPS in various challenging environments. The code and dataset will be released soon.
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
Nov 21, 2023



In this paper, we introduce $\textbf{GS-SLAM}$ that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D re-rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussian in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. The source code will be released soon.