 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Unreliability in Multimodal Machine Unlearning: A Systematic Analysis and Principled Unified Score
May 04, 2026Machine unlearning in Vision-Language Models (VLMs) is required for compliance with the General Data Protection Regulation (GDPR), yet current evaluation practices are inconsistent. We present the first systematic study of metric reliability in multimodal unlearning. Five standard metrics, Forget Accuracy (FA), Retain Accuracy (RA), Membership Inference Attack (MIA), Activation Distance (AD), and JS divergence (JS), yield conflicting method rankings across three VQA benchmarks (MLLMU-Bench, UnLOK-VQA, MMUBench). Kendall tau analysis over 36 unlearned LLaVA-1.5-7B models reveals two opposing clusters, {FA, RA, MIA} and {AD, JS}, with tau_FA_AD = -0.26, reproduced on BLIP-2 OPT-2.7B. Agreement is lower in multimodal VQA (average tau = 0.086) than in unimodal classification (average tau = 0.158; difference = 0.072), indicating that dual image-and-text pathways amplify inconsistency. We introduce the Unified Quality Score (UQS), a composite metric with weights derived from each metric's Spearman correlation with the oracle distance d(M_hat, M_star), where M_star is the oracle model retrained only on the retain set. RA shows the strongest reliability (rho = 0.484, p = 0.003), while FA is negatively correlated (rho = -0.418, p = 0.011). UQS yields stable rankings under 100 random weight perturbations (tau = 0.647 +- 0.262). We release the benchmark, 36 checkpoints, and an interactive leaderboard. Code and pre-computed results are available at https://github.com/neurips26/UnifiedUnl.
DurableUn: Quantization-Induced Recovery Attacks in Machine Unlearning
May 04, 2026Machine unlearning aims to remove specified training data to satisfy privacy regulations such as GDPR. However, existing evaluations assume identical precision at unlearning and deployment, overlooking that production LLMs are deployed at low-bit precision. We show that INT4 quantization systematically restores forgotten content even when models pass compliance audits at bfloat16 (BF16), we term this the quantization recovery attack (QRA). We conduct the first systematic study of unlearning robustness under adapter-space INT4 quantization in the NF4+LoRA regime, evaluating seven methods on LLaMA-3-8B-Instruct across TOFU, MUSE-News, and WikiBio-WPU. INT8 is benign; INT4 induces recovery of up to 22x, worsening with dataset difficulty. We identify the FA-RA-Q-INT4 trilemma: no method simultaneously achieves strong forgetting, high utility, and quantization robustness. A dense Pareto sweep reveals a sharp phase transition once robustness is achieved, retaining accuracy collapses regardless of further tuning. To address this, we propose DURABLEUN-SAF (Sharpness-Aware Forgetting), a quantization-aware objective using Straight-Through Estimator gradients through INT4 rounding. DURABLEUN-SAF is the only method to achieve a stable empirical (0.047, {BF16, INT8, INT4})- durability certificate: Q-INT4= 0.043 +- 0.002, cert rate= 3/3, versus SalUn's cert rate= 1/3 at its own published hyperparameters. We call for Q-INT4 to be adopted as a standard evaluation metric alongside FA and RA.
MultiShadow: Multi-Object Shadow Generation for Image Compositing via Diffusion Model
Mar 05, 2026Realistic shadow generation is crucial for achieving seamless image compositing, yet existing methods primarily focus on single-object insertion and often fail to generalize when multiple foreground objects are composited into a background scene. In practice, however, modern compositing pipelines and real-world applications often insert multiple objects simultaneously, necessitating shadows that are jointly consistent in terms of geometry, attachment, and location. In this paper, we address the under-explored problem of multi-object shadow generation, aiming to synthesize physically plausible shadows for multiple inserted objects. Our approach exploits the multimodal capabilities of a pre-trained text-to-image diffusion model. An image pathway injects dense, multi-scale features to provide fine-grained spatial guidance, while a text-based pathway encodes per-object shadow bounding boxes as learned positional tokens and fuses them via cross-attention. An attention-alignment loss further grounds these tokens to their corresponding shadow regions. To support this task, we augment the DESOBAv2 dataset by constructing composite scenes with multiple inserted objects and automatically derive prompts combining object category and shadow positioning information. Experimental results demonstrate that our method achieves state-of-the-art performance in both single and multi-object shadow generation settings.
FlexiCrackNet: A Flexible Pipeline for Enhanced Crack Segmentation with General Features Transfered from SAM
Jan 31, 2025



Automatic crack segmentation is a cornerstone technology for intelligent visual perception modules in road safety maintenance and structural integrity systems. Existing deep learning models and ``pre-training + fine-tuning'' paradigms often face challenges of limited adaptability in resource-constrained environments and inadequate scalability across diverse data domains. To overcome these limitations, we propose FlexiCrackNet, a novel pipeline that seamlessly integrates traditional deep learning paradigms with the strengths of large-scale pre-trained models. At its core, FlexiCrackNet employs an encoder-decoder architecture to extract task-specific features. The lightweight EdgeSAM's CNN-based encoder is exclusively used as a generic feature extractor, decoupled from the fixed input size requirements of EdgeSAM. To harmonize general and domain-specific features, we introduce the information-Interaction gated attention mechanism (IGAM), which adaptively fuses multi-level features to enhance segmentation performance while mitigating irrelevant noise. This design enables the efficient transfer of general knowledge to crack segmentation tasks while ensuring adaptability to diverse input resolutions and resource-constrained environments. Experiments show that FlexiCrackNet outperforms state-of-the-art methods, excels in zero-shot generalization, computational efficiency, and segmentation robustness under challenging scenarios such as blurry inputs, complex backgrounds, and visually ambiguous artifacts. These advancements underscore the potential of FlexiCrackNet for real-world applications in automated crack detection and comprehensive structural health monitoring systems.
A Riemannian Approach for Spatiotemporal Analysis and Generation of 4D Tree-shaped Structures
Aug 22, 2024



We propose the first comprehensive approach for modeling and analyzing the spatiotemporal shape variability in tree-like 4D objects, i.e., 3D objects whose shapes bend, stretch, and change in their branching structure over time as they deform, grow, and interact with their environment. Our key contribution is the representation of tree-like 3D shapes using Square Root Velocity Function Trees (SRVFT). By solving the spatial registration in the SRVFT space, which is equipped with an L2 metric, 4D tree-shaped structures become time-parameterized trajectories in this space. This reduces the problem of modeling and analyzing 4D tree-like shapes to that of modeling and analyzing elastic trajectories in the SRVFT space, where elasticity refers to time warping. In this paper, we propose a novel mathematical representation of the shape space of such trajectories, a Riemannian metric on that space, and computational tools for fast and accurate spatiotemporal registration and geodesics computation between 4D tree-shaped structures. Leveraging these building blocks, we develop a full framework for modelling the spatiotemporal variability using statistical models and generating novel 4D tree-like structures from a set of exemplars. We demonstrate and validate the proposed framework using real 4D plant data.
Deep Learning-based Depth Estimation Methods from Monocular Image and Videos: A Comprehensive Survey
Jun 28, 2024



Estimating depth from single RGB images and videos is of widespread interest due to its applications in many areas, including autonomous driving, 3D reconstruction, digital entertainment, and robotics. More than 500 deep learning-based papers have been published in the past 10 years, which indicates the growing interest in the task. This paper presents a comprehensive survey of the existing deep learning-based methods, the challenges they address, and how they have evolved in their architecture and supervision methods. It provides a taxonomy for classifying the current work based on their input and output modalities, network architectures, and learning methods. It also discusses the major milestones in the history of monocular depth estimation, and different pipelines, datasets, and evaluation metrics used in existing methods.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024



Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
An Intra-BRNN and GB-RVQ Based END-TO-END Neural Audio Codec
Feb 02, 2024



Recently, neural networks have proven to be effective in performing speech coding task at low bitrates. However, under-utilization of intra-frame correlations and the error of quantizer specifically degrade the reconstructed audio quality. To improve the coding quality, we present an end-to-end neural speech codec, namely CBRC (Convolutional and Bidirectional Recurrent neural Codec). An interleaved structure using 1D-CNN and Intra-BRNN is designed to exploit the intra-frame correlations more efficiently. Furthermore, Group-wise and Beam-search Residual Vector Quantizer (GB-RVQ) is used to reduce the quantization noise. CBRC encodes audio every 20ms with no additional latency, which is suitable for real-time communication. Experimental results demonstrate the superiority of the proposed codec when comparing CBRC at 3kbps with Opus at 12kbps.
Performance of multilabel machine learning models and risk stratification schemas for predicting stroke and bleeding risk in patients with non-valvular atrial fibrillation
Feb 02, 2022
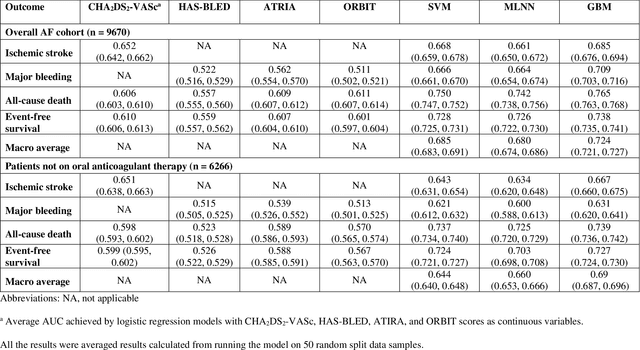
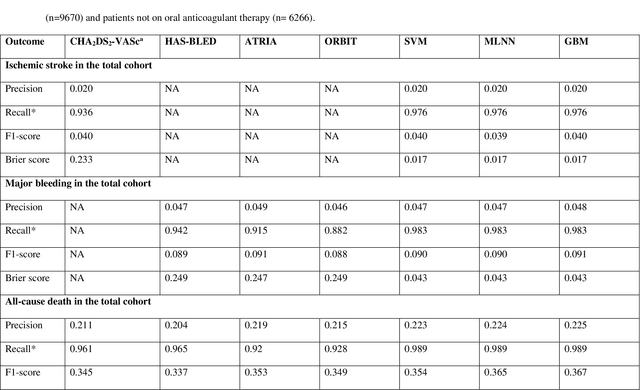
Appropriate antithrombotic therapy for patients with atrial fibrillation (AF) requires assessment of ischemic stroke and bleeding risks. However, risk stratification schemas such as CHA2DS2-VASc and HAS-BLED have modest predictive capacity for patients with AF. Machine learning (ML) techniques may improve predictive performance and support decision-making for appropriate antithrombotic therapy. We compared the performance of multilabel ML models with the currently used risk scores for predicting outcomes in AF patients. Materials and Methods This was a retrospective cohort study of 9670 patients, mean age 76.9 years, 46% women, who were hospitalized with non-valvular AF, and had 1-year follow-up. The primary outcome was ischemic stroke and major bleeding admission. The secondary outcomes were all-cause death and event-free survival. The discriminant power of ML models was compared with clinical risk scores by the area under the curve (AUC). Risk stratification was assessed using the net reclassification index. Results Multilabel gradient boosting machine provided the best discriminant power for stroke, major bleeding, and death (AUC = 0.685, 0.709, and 0.765 respectively) compared to other ML models. It provided modest performance improvement for stroke compared to CHA2DS2-VASc (AUC = 0.652), but significantly improved major bleeding prediction compared to HAS-BLED (AUC = 0.522). It also had a much greater discriminant power for death compared with CHA2DS2-VASc (AUC = 0.606). Also, models identified additional risk features (such as hemoglobin level, renal function, etc.) for each outcome. Conclusions Multilabel ML models can outperform clinical risk stratification scores for predicting the risk of major bleeding and death in non-valvular AF patients.
Weed Recognition using Deep Learning Techniques on Class-imbalanced Imagery
Dec 15, 2021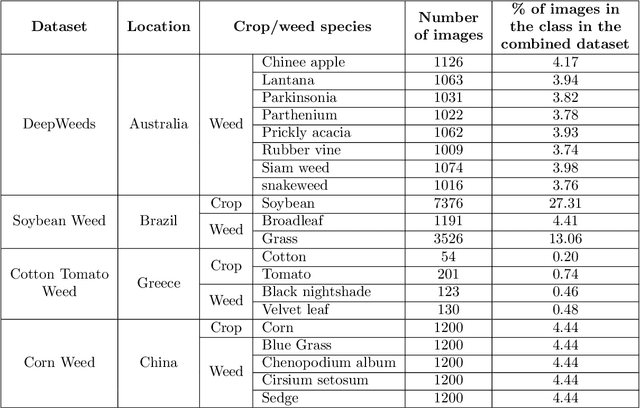

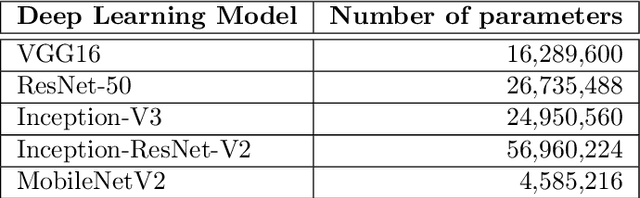
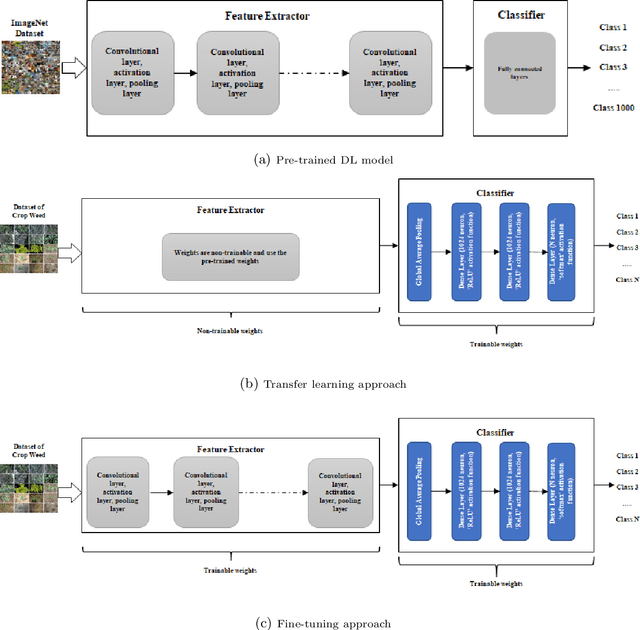
Most weed species can adversely impact agricultural productivity by competing for nutrients required by high-value crops. Manual weeding is not practical for large cropping areas. Many studies have been undertaken to develop automatic weed management systems for agricultural crops. In this process, one of the major tasks is to recognise the weeds from images. However, weed recognition is a challenging task. It is because weed and crop plants can be similar in colour, texture and shape which can be exacerbated further by the imaging conditions, geographic or weather conditions when the images are recorded. Advanced machine learning techniques can be used to recognise weeds from imagery. In this paper, we have investigated five state-of-the-art deep neural networks, namely VGG16, ResNet-50, Inception-V3, Inception-ResNet-v2 and MobileNetV2, and evaluated their performance for weed recognition. We have used several experimental settings and multiple dataset combinations. In particular, we constructed a large weed-crop dataset by combining several smaller datasets, mitigating class imbalance by data augmentation, and using this dataset in benchmarking the deep neural networks. We investigated the use of transfer learning techniques by preserving the pre-trained weights for extracting the features and fine-tuning them using the images of crop and weed datasets. We found that VGG16 performed better than others on small-scale datasets, while ResNet-50 performed better than other deep networks on the large combined dataset.