 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DP3: 3D Scene Perception via Probabilistic Programming
Oct 30, 2021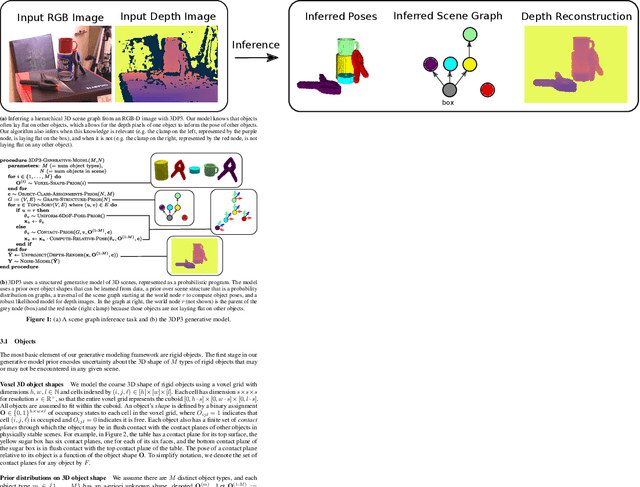
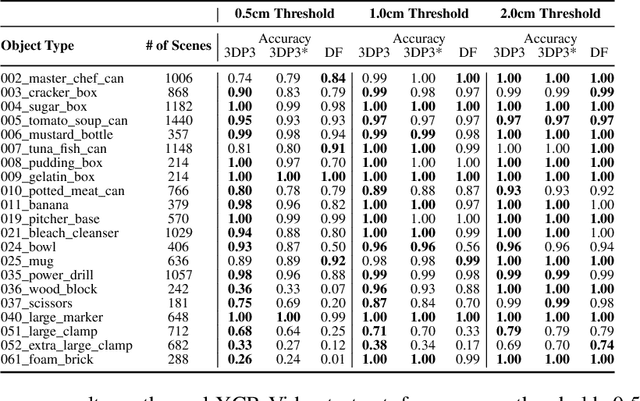
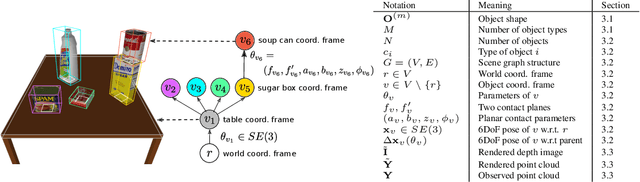
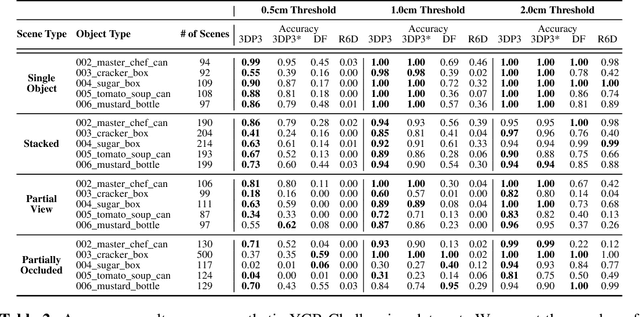
We present 3DP3, a framework for inverse graphics that uses inference in a structured generative model of objects, scenes, and images. 3DP3 uses (i) voxel models to represent the 3D shape of objects, (ii) hierarchical scene graphs to decompose scenes into objects and the contacts between them, and (iii) depth image likelihoods based on real-time graphics. Given an observed RGB-D image, 3DP3's inference algorithm infers the underlying latent 3D scene, including the object poses and a parsimonious joint parametrization of these poses, using fast bottom-up pose proposals, novel involutive MCMC updates of the scene graph structure, and, optionally, neural object detectors and pose estimators. We show that 3DP3 enables scene understanding that is aware of 3D shape, occlusion, and contact structure. Our results demonstrate that 3DP3 is more accurate at 6DoF object pose estimation from real images than deep learning baselines and shows better generalization to challenging scenes with novel viewpoints, contact, and partial observability.
Incorporating Rich Social Interactions Into MDPs
Oct 22, 2021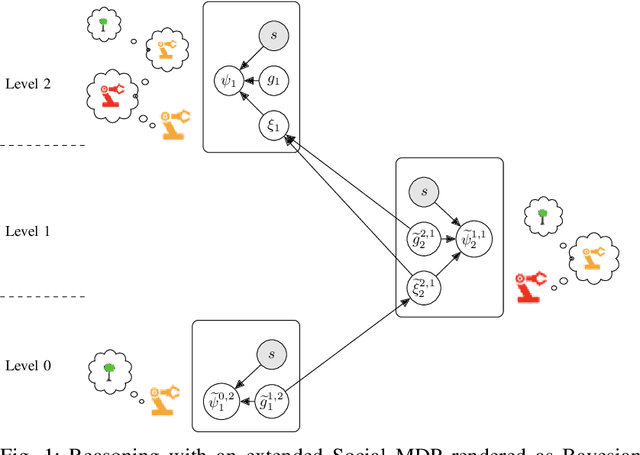
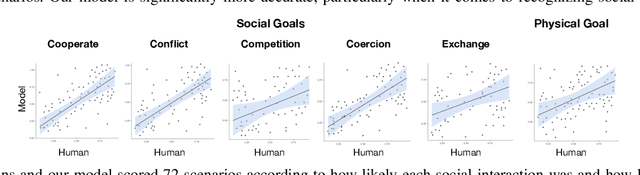
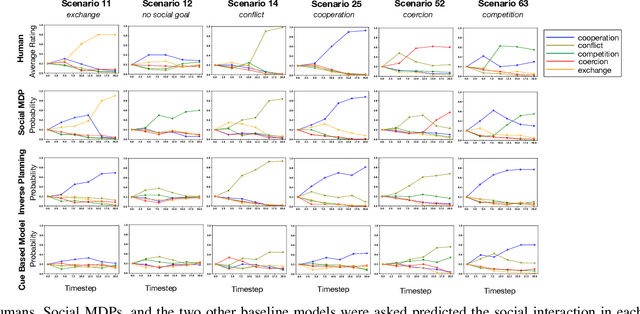

Much of what we do as humans is engage socially with other agents, a skill that robots must also eventually possess. We demonstrate that a rich theory of social interactions originating from microsociology and economics can be formalized by extending a nested MDP where agents reason about arbitrary functions of each other's hidden rewards. This extended Social MDP allows us to encode the five basic interactions that underlie microsociology: cooperation, conflict, coercion, competition, and exchange. The result is a robotic agent capable of executing social interactions zero-shot in new environments; like humans it can engage socially in novel ways even without a single example of that social interaction. Moreover, the judgments of these Social MDPs align closely with those of humans when considering which social interaction is taking place in an environment. This method both sheds light on the nature of social interactions, by providing concrete mathematical definitions, and brings rich social interactions into a mathematical framework that has proven to be natural for robotics, MDPs.
The ThreeDWorld Transport Challenge: A Visually Guided Task-and-Motion Planning Benchmark for Physically Realistic Embodied AI
Mar 25, 2021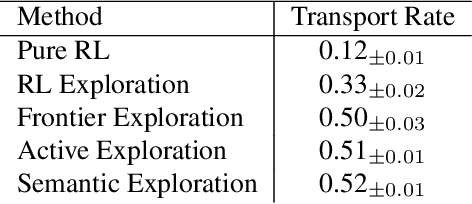

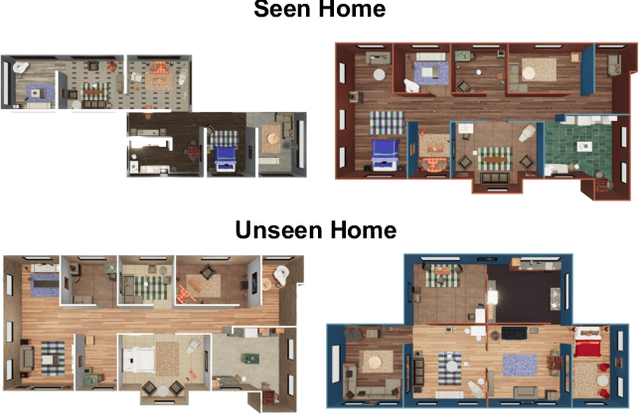
We introduce a visually-guided and physics-driven task-and-motion planning benchmark, which we call the ThreeDWorld Transport Challenge. In this challenge, an embodied agent equipped with two 9-DOF articulated arms is spawned randomly in a simulated physical home environment. The agent is required to find a small set of objects scattered around the house, pick them up, and transport them to a desired final location. We also position containers around the house that can be used as tools to assist with transporting objects efficiently. To complete the task, an embodied agent must plan a sequence of actions to change the state of a large number of objects in the face of realistic physical constraints. We build this benchmark challenge using the ThreeDWorld simulation: a virtual 3D environment where all objects respond to physics, and where can be controlled using fully physics-driven navigation and interaction API. We evaluate several existing agents on this benchmark. Experimental results suggest that: 1) a pure RL model struggles on this challenge; 2) hierarchical planning-based agents can transport some objects but still far from solving this task. We anticipate that this benchmark will empower researchers to develop more intelligent physics-driven robots for the physical world.
AGENT: A Benchmark for Core Psychological Reasoning
Feb 25, 2021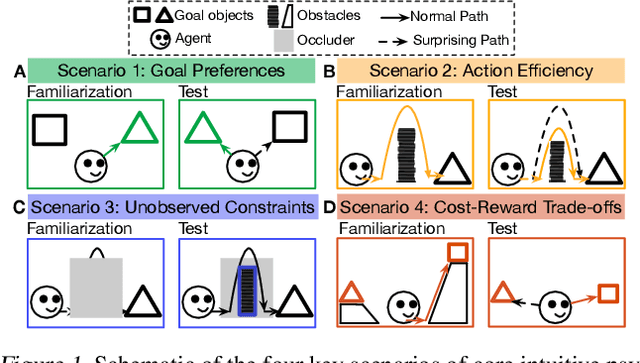
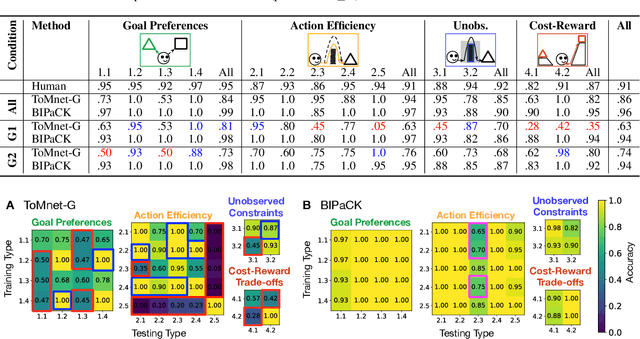
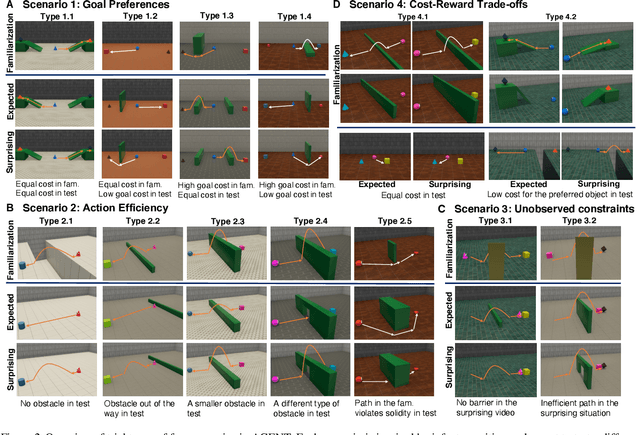
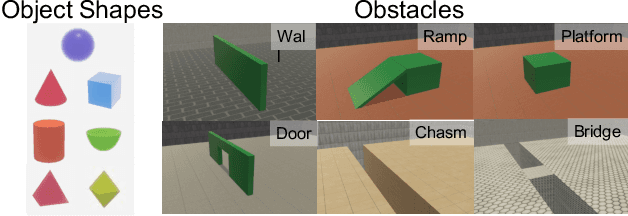
For machine agents to successfully interact with humans in real-world settings, they will need to develop an understanding of human mental life. Intuitive psychology, the ability to reason about hidden mental variables that drive observable actions, comes naturally to people: even pre-verbal infants can tell agents from objects, expecting agents to act efficiently to achieve goals given constraints. Despite recent interest in machine agents that reason about other agents, it is not clear if such agents learn or hold the core psychology principles that drive human reasoning. Inspired by cognitive development studies on intuitive psychology, we present a benchmark consisting of a large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four scenarios (goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs) that probe key concepts of core intuitive psychology. We validate AGENT with human-ratings, propose an evaluation protocol emphasizing generalization, and compare two strong baselines built on Bayesian inverse planning and a Theory of Mind neural network. Our results suggest that to pass the designed tests of core intuitive psychology at human levels, a model must acquire or have built-in representations of how agents plan, combining utility computations and core knowledge of objects and physics.
Template Controllable keywords-to-text Generation
Nov 07, 2020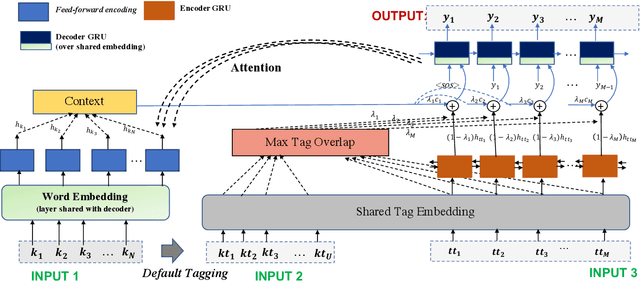
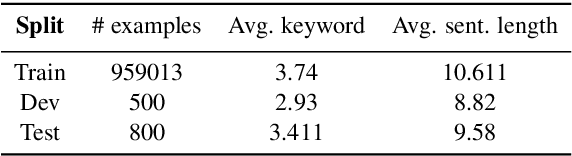
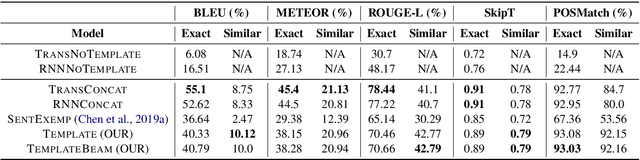
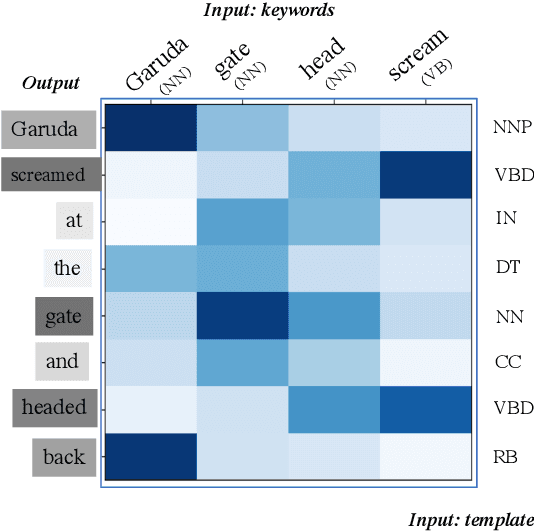
This paper proposes a novel neural model for the understudied task of generating text from keywords. The model takes as input a set of un-ordered keywords, and part-of-speech (POS) based template instructions. This makes it ideal for surface realization in any NLG setup. The framework is based on the encode-attend-decode paradigm, where keywords and templates are encoded first, and the decoder judiciously attends over the contexts derived from the encoded keywords and templates to generate the sentences. Training exploits weak supervision, as the model trains on a large amount of labeled data with keywords and POS based templates prepared through completely automatic means. Qualitative and quantitative performance analyses on publicly available test-data in various domains reveal our system's superiority over baselines, built using state-of-the-art neural machine translation and controllable transfer techniques. Our approach is indifferent to the order of input keywords.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

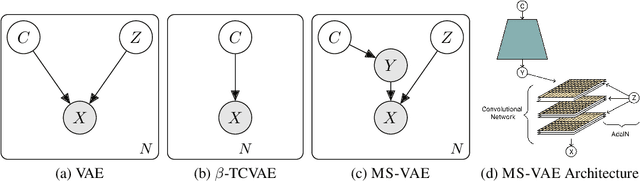

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
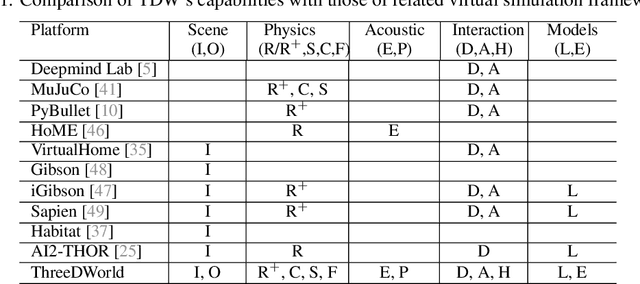

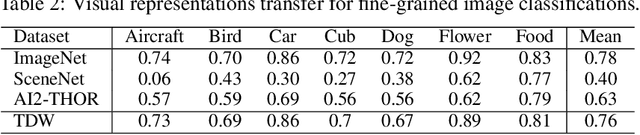
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
SimVAE: Simulator-Assisted Training forInterpretable Generative Models
Nov 19, 2019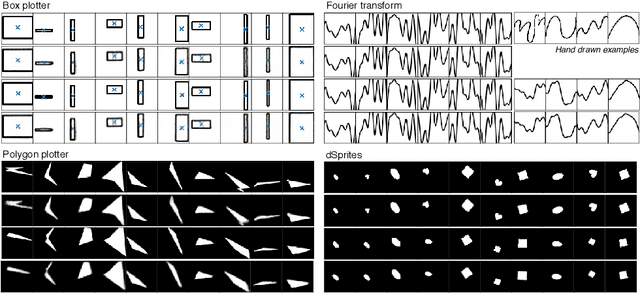
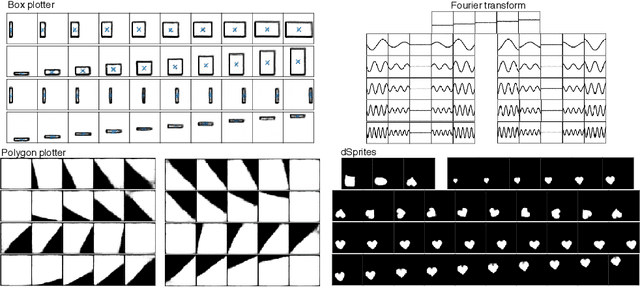
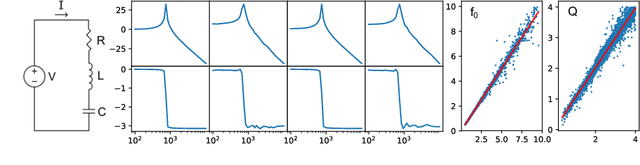
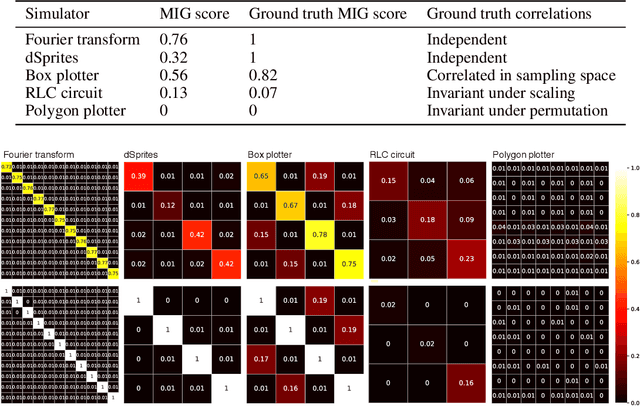
This paper presents a simulator-assisted training method (SimVAE) for variational autoencoders (VAE) that leads to a disentangled and interpretable latent space. Training SimVAE is a two-step process in which first a deep generator network(decoder) is trained to approximate the simulator. During this step, the simulator acts as the data source or as a teacher network. Then an inference network (encoder)is trained to invert the decoder. As such, upon complete training, the encoder represents an approximately inverted simulator. By decoupling the training of the encoder and decoder we bypass some of the difficulties that arise in training generative models such as VAEs and generative adversarial networks (GANs). We show applications of our approach in a variety of domains such as circuit design, graphics de-rendering and other natural science problems that involve inference via simulation.
Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding
Nov 04, 2019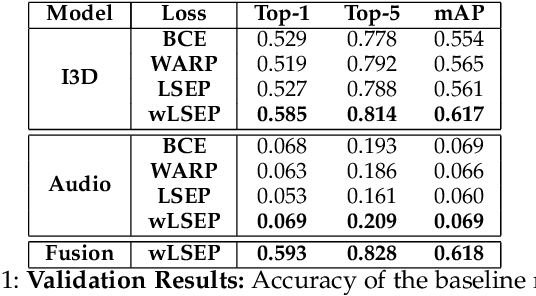


An event happening in the world is often made of different activities and actions that can unfold simultaneously or sequentially within a few seconds. However, most large-scale datasets built to train models for action recognition provide a single label per video clip. Consequently, models can be incorrectly penalized for classifying actions that exist in the videos but are not explicitly labeled and do not learn the full spectrum of information that would be mandatory to more completely comprehend different events and eventually learn causality between them. Towards this goal, we augmented the existing video dataset, Moments in Time (MiT), to include over two million action labels for over one million three second videos. This multi-label dataset introduces novel challenges on how to train and analyze models for multi-action detection. Here, we present baseline results for multi-action recognition using loss functions adapted for long tail multi-label learning and provide improved methods for visualizing and interpreting models trained for multi-label action detection.
Reasoning About Human-Object Interactions Through Dual Attention Networks
Sep 10, 2019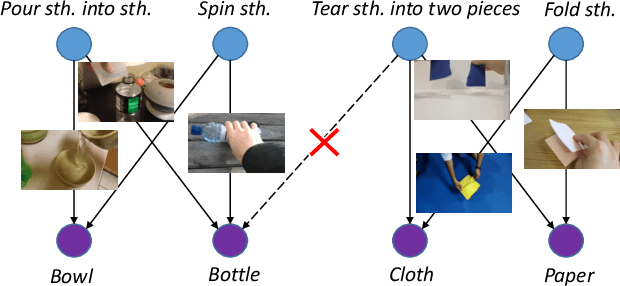

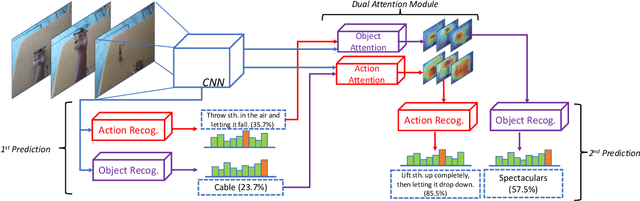
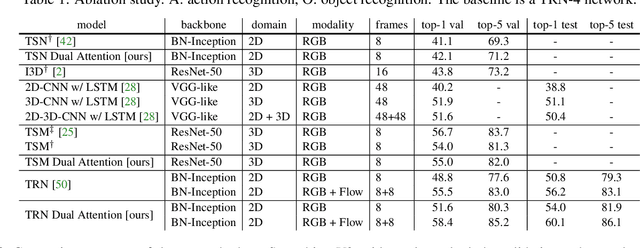
Objects are entities we act upon, where the functionality of an object is determined by how we interact with it. In this work we propose a Dual Attention Network model which reasons about human-object interactions. The dual-attentional framework weights the important features for objects and actions respectively. As a result, the recognition of objects and actions mutually benefit each other. The proposed model shows competitive classification performance on the human-object interaction dataset Something-Something. Besides, it can perform weak spatiotemporal localization and affordance segmentation, despite being trained only with video-level labels. The model not only finds when an action is happening and which object is being manipulated, but also identifies which part of the object is being interacted with. Project page: \url{https://dual-attention-network.github.io/}.