 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational TTS with Cascaded Prompting and ICL-Based Online Reinforcement Learning
Apr 09, 2026Conversational AI has made significant progress, yet generating expressive and controllable text-to-speech (TTS) remains challenging. Specifically, controlling fine-grained voice styles and emotions is notoriously difficult and typically requires massive amounts of heavily annotated training data. To overcome this data bottleneck, we present a scalable, data-efficient cascaded framework that pairs textual style tokens with human-curated, high-quality audio prompts. This approach enables single-shot adaptation to fine-grained speaking styles and character voices. In the context of TTS, this audio prompting acts as In-Context Learning (ICL), guiding the model's prosody and timbre without requiring massive parameter updates or large-scale retraining. To further enhance generation quality and mitigate hallucinations, we introduce a novel ICL-based online reinforcement learning (RL) strategy. This strategy directly optimizes the autoregressive prosody model using subjective aesthetic rewards while being constrained by Connectionist Temporal Classification (CTC) alignment to preserve intelligibility. Comprehensive human perception evaluations demonstrate significant improvements in both the naturalness and expressivity of the synthesized speech, establishing the efficacy of our ICL-based online RL approach.
Equipping LLM with Directional Multi-Talker Speech Understanding Capabilities
Feb 06, 2026Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech understanding capabilities. However, most speech LLMs are trained on single-channel, single-talker data, which makes it challenging to directly apply them to multi-talker and multi-channel speech understanding task. In this work, we present a comprehensive investigation on how to enable directional multi-talker speech understanding capabilities for LLMs, specifically in smart glasses usecase. We propose two novel approaches to integrate directivity into LLMs: (1) a cascaded system that leverages a source separation front-end module, and (2) an end-to-end system that utilizes serialized output training. All of the approaches utilize a multi-microphone array embedded in smart glasses to optimize directivity interpretation and processing in a streaming manner. Experimental results demonstrate the efficacy of our proposed methods in endowing LLMs with directional speech understanding capabilities, achieving strong performance in both speech recognition and speech translation tasks.
T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
Aug 28, 2024A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
On-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Jul 06, 2023



Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.
Small-footprint slimmable networks for keyword spotting
Apr 21, 2023



In this work, we present Slimmable Neural Networks applied to the problem of small-footprint keyword spotting. We show that slimmable neural networks allow us to create super-nets from Convolutioanl Neural Networks and Transformers, from which sub-networks of different sizes can be extracted. We demonstrate the usefulness of these models on in-house Alexa data and Google Speech Commands, and focus our efforts on models for the on-device use case, limiting ourselves to less than 250k parameters. We show that slimmable models can match (and in some cases, outperform) models trained from scratch. Slimmable neural networks are therefore a class of models particularly useful when the same functionality is to be replicated at different memory and compute budgets, with different accuracy requirements.
Self-supervised speech representation learning for keyword-spotting with light-weight transformers
Mar 07, 2023



Self-supervised speech representation learning (S3RL) is revolutionizing the way we leverage the ever-growing availability of data. While S3RL related studies typically use large models, we employ light-weight networks to comply with tight memory of compute-constrained devices. We demonstrate the effectiveness of S3RL on a keyword-spotting (KS) problem by using transformers with 330k parameters and propose a mechanism to enhance utterance-wise distinction, which proves crucial for improving performance on classification tasks. On the Google speech commands v2 dataset, the proposed method applied to the Auto-Regressive Predictive Coding S3RL led to a 1.2% accuracy improvement compared to training from scratch. On an in-house KS dataset with four different keywords, it provided 6% to 23.7% relative false accept improvement at fixed false reject rate. We argue this demonstrates the applicability of S3RL approaches to light-weight models for KS and confirms S3RL is a powerful alternative to traditional supervised learning for resource-constrained applications.
Fixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023



Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
Sub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022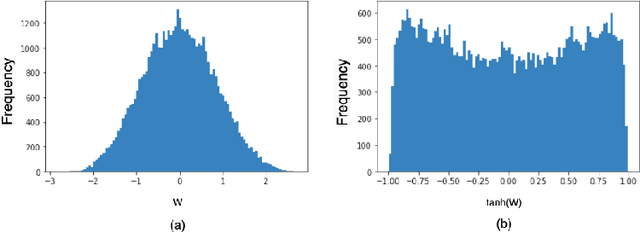
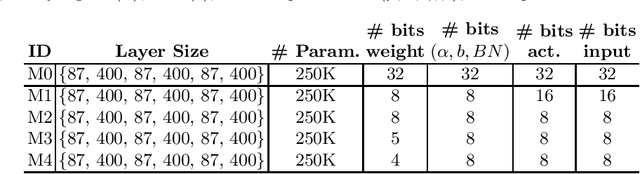
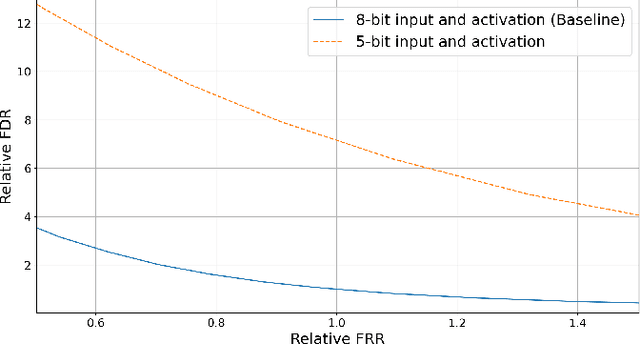
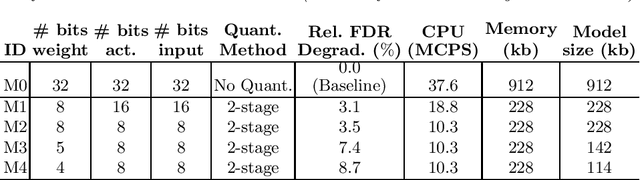
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization
Dec 11, 2020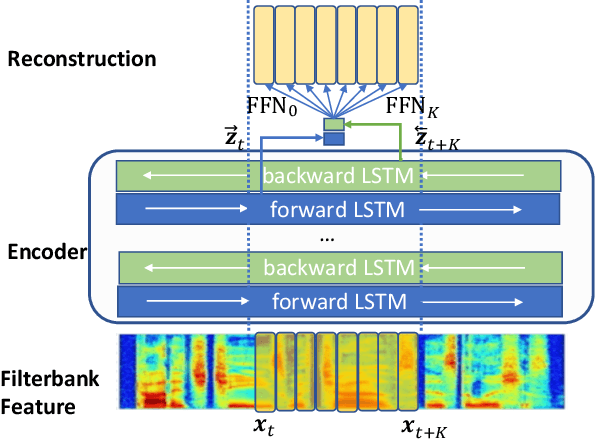

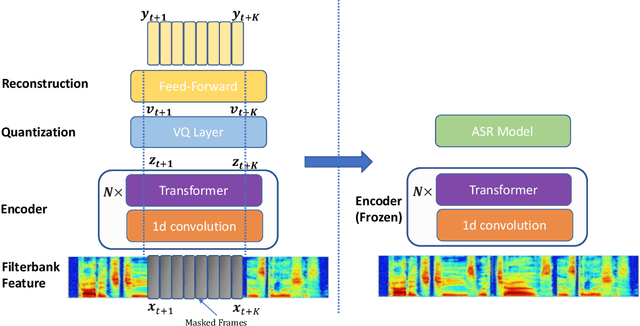
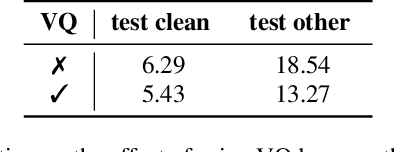
Recent success in speech representation learning enables a new way to leverage unlabeled data to train speech recognition model. In speech representation learning, a large amount of unlabeled data is used in a self-supervised manner to learn a feature representation. Then a smaller amount of labeled data is used to train a downstream ASR system using the new feature representations. Based on our previous work DeCoAR and inspirations from other speech representation learning, we propose DeCoAR 2.0, a Deep Contextualized Acoustic Representation with vector quantization. We introduce several modifications over the DeCoAR: first, we use Transformers in encoding module instead of LSTMs; second, we introduce a vector quantization layer between encoder and reconstruction modules; third, we propose an objective that combines the reconstructive loss with vector quantization diversity loss to train speech representations. Our experiments show consistent improvements over other speech representations in different data-sparse scenarios. Without fine-tuning, a light-weight ASR model trained on 10 hours of LibriSpeech labeled data with DeCoAR 2.0 features outperforms the model trained on the full 960-hour dataset with filterbank features.