 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
Jun 02, 2026Reward models (RMs) provide critical feedback signals for LLM post-training, notably in reinforced fine-tuning (RFT) and reinforcement learning (RL) pipelines. However, current reward evaluation relies on heterogeneous criteria such as rule-based verifiers, ground-truth references, procedural checklists, and complex rubrics, where a unified mechanism to integrate all types of evidence remains unexplored. To this end, we propose Skill Reward Model (Skill-RM), a unified framework that reformulates reward modeling as the execution of a reusable Reward-Evaluation Skill. By treating reward computation as a structured agentic task, Skill-RM provides a consistent interface to orchestrate heterogeneous resources, dynamically selecting and aggregating evidence tailored to the specific requirements of each input. This approach enables the reward model to move beyond static evaluation, ensuring consistency and transparency across diverse tasks. Extensive experiments on reward benchmarks and downstream applications, including best-of-N selection and reinforcement learning, demonstrate that Skill-RM consistently outperforms traditional judge baselines. Our findings suggest that Skill-RM not only provides a unified solution for reward modeling but also achieves superior performance through the strategic and dynamic orchestration of evidence. The code is at https://github.com/Qwen-Applications/Skill-RM.
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Nov 09, 2023

Large language models (LLMs), such as ChatGPT, have achieved substantial attention due to their impressive human language understanding and generation capabilities. Therefore, the application of LLMs in medicine to assist physicians and patient care emerges as a promising research direction in both artificial intelligence and clinical medicine. To this end, this survey provides a comprehensive overview of the current progress, applications, and challenges faced by LLMs in medicine. Specifically, we aim to address the following questions: 1) What are LLMs and how can medical LLMs be built? 2) What are the downstream performances of medical LLMs? 3) How can medical LLMs be utilized in real-world clinical practice? 4) What challenges arise from the use of medical LLMs? 5) How can we better construct and utilize medical LLMs? As a result, this survey aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a valuable resource for constructing practical and effective medical LLMs. A regularly updated list of practical guide resources of medical LLMs can be found at https://github.com/AI-in-Health/MedLLMsPracticalGuide.
Exploring Recommendation Capabilities of GPT-4V(ision): A Preliminary Case Study
Nov 07, 2023



Large Multimodal Models (LMMs) have demonstrated impressive performance across various vision and language tasks, yet their potential applications in recommendation tasks with visual assistance remain unexplored. To bridge this gap, we present a preliminary case study investigating the recommendation capabilities of GPT-4V(ison), a recently released LMM by OpenAI. We construct a series of qualitative test samples spanning multiple domains and employ these samples to assess the quality of GPT-4V's responses within recommendation scenarios. Evaluation results on these test samples prove that GPT-4V has remarkable zero-shot recommendation abilities across diverse domains, thanks to its robust visual-text comprehension capabilities and extensive general knowledge. However, we have also identified some limitations in using GPT-4V for recommendations, including a tendency to provide similar responses when given similar inputs. This report concludes with an in-depth discussion of the challenges and research opportunities associated with utilizing GPT-4V in recommendation scenarios. Our objective is to explore the potential of extending LMMs from vision and language tasks to recommendation tasks. We hope to inspire further research into next-generation multimodal generative recommendation models, which can enhance user experiences by offering greater diversity and interactivity. All images and prompts used in this report will be accessible at https://github.com/PALIN2018/Evaluate_GPT-4V_Rec.
Qilin-Med-VL: Towards Chinese Large Vision-Language Model for General Healthcare
Nov 01, 2023Large Language Models (LLMs) have introduced a new era of proficiency in comprehending complex healthcare and biomedical topics. However, there is a noticeable lack of models in languages other than English and models that can interpret multi-modal input, which is crucial for global healthcare accessibility. In response, this study introduces Qilin-Med-VL, the first Chinese large vision-language model designed to integrate the analysis of textual and visual data. Qilin-Med-VL combines a pre-trained Vision Transformer (ViT) with a foundational LLM. It undergoes a thorough two-stage curriculum training process that includes feature alignment and instruction tuning. This method enhances the model's ability to generate medical captions and answer complex medical queries. We also release ChiMed-VL, a dataset consisting of more than 1M image-text pairs. This dataset has been carefully curated to enable detailed and comprehensive interpretation of medical data using various types of images.
Qilin-Med: Multi-stage Knowledge Injection Advanced Medical Large Language Model
Oct 13, 2023



Integrating large language models (LLMs) into healthcare presents potential but faces challenges. Directly pre-training LLMs for domains like medicine is resource-heavy and sometimes unfeasible. Sole reliance on Supervised Fine-tuning (SFT) can result in overconfident predictions and may not tap into domain specific insights. Addressing these challenges, we present a multi-stage training method combining Domain-specific Continued Pre-training (DCPT), SFT, and Direct Preference Optimization (DPO). A notable contribution of our study is the introduction of a 3Gb Chinese Medicine (ChiMed) dataset, encompassing medical question answering, plain texts, knowledge graphs, and dialogues, segmented into three training stages. The medical LLM trained with our pipeline, Qilin-Med, exhibits significant performance boosts. In the CPT and SFT phases, it achieves 38.4% and 40.0% accuracy on the CMExam, surpassing Baichuan-7B's 33.5%. In the DPO phase, on the Huatuo-26M test set, it scores 16.66 in BLEU-1 and 27.44 in ROUGE1, outperforming the SFT's 12.69 and 24.21. This highlights the strength of our training approach in refining LLMs for medical applications.
LLMRec: Benchmarking Large Language Models on Recommendation Task
Aug 23, 2023
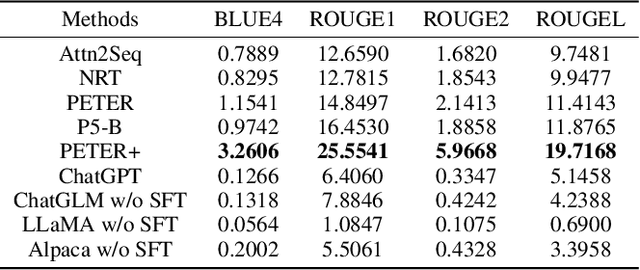


Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at https://github.com/williamliujl/LLMRec.
Benchmarking Large Language Models on CMExam -- A Comprehensive Chinese Medical Exam Dataset
Jun 08, 2023



Recent advancements in large language models (LLMs) have transformed the field of question answering (QA). However, evaluating LLMs in the medical field is challenging due to the lack of standardized and comprehensive datasets. To address this gap, we introduce CMExam, sourced from the Chinese National Medical Licensing Examination. CMExam consists of 60K+ multiple-choice questions for standardized and objective evaluations, as well as solution explanations for model reasoning evaluation in an open-ended manner. For in-depth analyses of LLMs, we invited medical professionals to label five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam. The results show that GPT-4 had the best accuracy of 61.6% and a weighted F1 score of 0.617. These results highlight a great disparity when compared to human accuracy, which stood at 71.6%. For explanation tasks, while LLMs could generate relevant reasoning and demonstrate improved performance after finetuning, they fall short of a desired standard, indicating ample room for improvement. To the best of our knowledge, CMExam is the first Chinese medical exam dataset to provide comprehensive medical annotations. The experiments and findings of LLM evaluation also provide valuable insights into the challenges and potential solutions in developing Chinese medical QA systems and LLM evaluation pipelines. The dataset and relevant code are available at https://github.com/williamliujl/CMExam.
Is ChatGPT a Good Recommender? A Preliminary Study
Apr 20, 2023Recommendation systems have witnessed significant advancements and have been widely used over the past decades. However, most traditional recommendation methods are task-specific and therefore lack efficient generalization ability. Recently, the emergence of ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. Nonetheless, the application of ChatGPT in the recommendation domain has not been thoroughly investigated. In this paper, we employ ChatGPT as a general-purpose recommendation model to explore its potential for transferring extensive linguistic and world knowledge acquired from large-scale corpora to recommendation scenarios. Specifically, we design a set of prompts and evaluate ChatGPT's performance on five recommendation scenarios. Unlike traditional recommendation methods, we do not fine-tune ChatGPT during the entire evaluation process, relying only on the prompts themselves to convert recommendation tasks into natural language tasks. Further, we explore the use of few-shot prompting to inject interaction information that contains user potential interest to help ChatGPT better understand user needs and interests. Comprehensive experimental results on Amazon Beauty dataset show that ChatGPT has achieved promising results in certain tasks and is capable of reaching the baseline level in others. We conduct human evaluations on two explainability-oriented tasks to more accurately evaluate the quality of contents generated by different models. And the human evaluations show ChatGPT can truly understand the provided information and generate clearer and more reasonable results. We hope that our study can inspire researchers to further explore the potential of language models like ChatGPT to improve recommendation performance and contribute to the advancement of the recommendation systems field.
Weighing Features of Lung and Heart Regions for Thoracic Disease Classification
May 26, 2021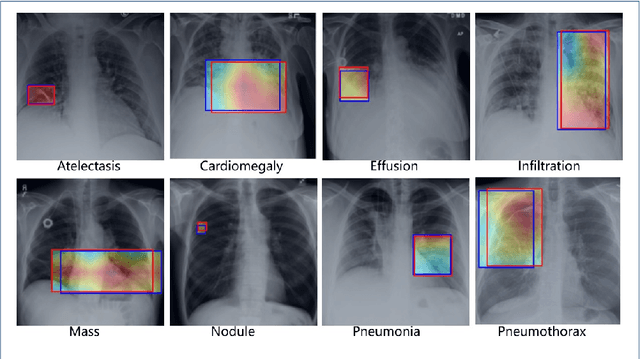
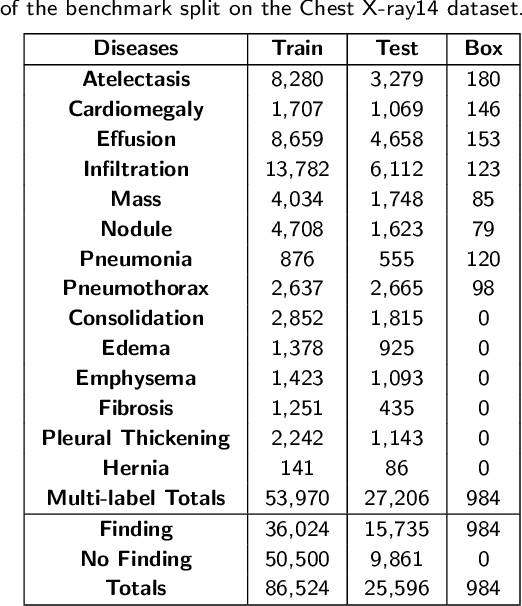
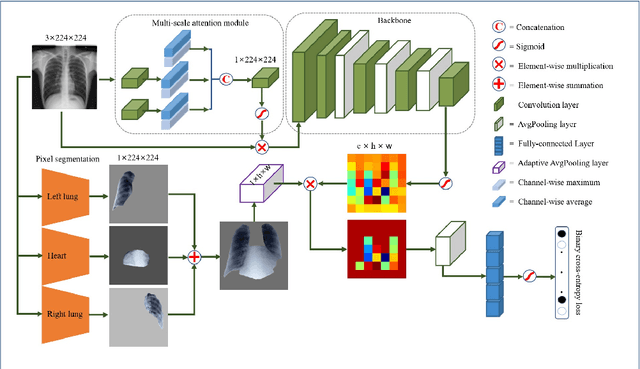
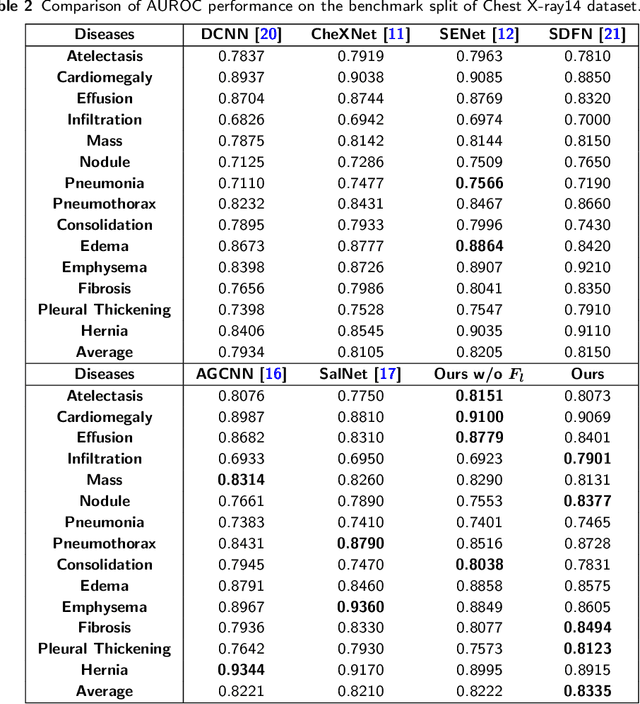
Chest X-rays are the most commonly available and affordable radiological examination for screening thoracic diseases. According to the domain knowledge of screening chest X-rays, the pathological information usually lay on the lung and heart regions. However, it is costly to acquire region-level annotation in practice, and model training mainly relies on image-level class labels in a weakly supervised manner, which is highly challenging for computer-aided chest X-ray screening. To address this issue, some methods have been proposed recently to identify local regions containing pathological information, which is vital for thoracic disease classification. Inspired by this, we propose a novel deep learning framework to explore discriminative information from lung and heart regions. We design a feature extractor equipped with a multi-scale attention module to learn global attention maps from global images. To exploit disease-specific cues effectively, we locate lung and heart regions containing pathological information by a well-trained pixel-wise segmentation model to generate binarization masks. By introducing element-wise logical AND operator on the learned global attention maps and the binarization masks, we obtain local attention maps in which pixels are $1$ for lung and heart region and $0$ for other regions. By zeroing features of non-lung and heart regions in attention maps, we can effectively exploit their disease-specific cues in lung and heart regions. Compared to existing methods fusing global and local features, we adopt feature weighting to avoid weakening visual cues unique to lung and heart regions. Evaluated by the benchmark split on the publicly available chest X-ray14 dataset, the comprehensive experiments show that our method achieves superior performance compared to the state-of-the-art methods.
Spatial-Scale Aligned Network for Fine-Grained Recognition
Jan 05, 2020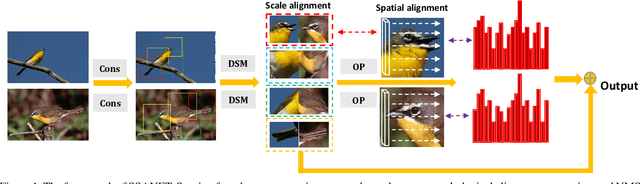


Existing approaches for fine-grained visual recognition focus on learning marginal region-based representations while neglecting the spatial and scale misalignments, leading to inferior performance. In this paper, we propose the spatial-scale aligned network (SSANET) and implicitly address misalignments during the recognition process. Especially, SSANET consists of 1) a self-supervised proposal mining formula with Morphological Alignment Constraints; 2) a discriminative scale mining (DSM) module, which exploits the feature pyramid via a circulant matrix, and provides the Fourier solver for fast scale alignments; 3) an oriented pooling (OP) module, that performs the pooling operation in several pre-defined orientations. Each orientation defines one kind of spatial alignment, and the network automatically determines which is the optimal alignments through learning. With the proposed two modules, our algorithm can automatically determine the accurate local proposal regions and generate more robust target representations being invariant to various appearance variances. Extensive experiments verify that SSANET is competent at learning better spatial-scale invariant target representations, yielding superior performance on the fine-grained recognition task on several benchmarks.