 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-OCR: Can Large Multimodal Models Solve Complex Logical Reasoning Problems from OCR Cues?
May 19, 2025Large Multimodal Models (LMMs) have become increasingly versatile, accompanied by impressive Optical Character Recognition (OCR) related capabilities. Existing OCR-related benchmarks emphasize evaluating LMMs' abilities of relatively simple visual question answering, visual-text parsing, etc. However, the extent to which LMMs can deal with complex logical reasoning problems based on OCR cues is relatively unexplored. To this end, we introduce the Reasoning-OCR benchmark, which challenges LMMs to solve complex reasoning problems based on the cues that can be extracted from rich visual-text. Reasoning-OCR covers six visual scenarios and encompasses 150 meticulously designed questions categorized into six reasoning challenges. Additionally, Reasoning-OCR minimizes the impact of field-specialized knowledge. Our evaluation offers some insights for proprietary and open-source LMMs in different reasoning challenges, underscoring the urgent to improve the reasoning performance. We hope Reasoning-OCR can inspire and facilitate future research on enhancing complex reasoning ability based on OCR cues. Reasoning-OCR is publicly available at https://github.com/Hxyz-123/ReasoningOCR.
LogicOCR: Do Your Large Multimodal Models Excel at Logical Reasoning on Text-Rich Images?
May 18, 2025Recent advances in Large Multimodal Models (LMMs) have significantly improved their reasoning and Optical Character Recognition (OCR) capabilities. However, their performance on complex logical reasoning tasks involving text-rich images remains underexplored. To bridge this gap, we introduce LogicOCR, a benchmark comprising 1,100 multiple-choice questions designed to evaluate LMMs' logical reasoning abilities on text-rich images, while minimizing reliance on domain-specific knowledge (e.g., mathematics). We construct LogicOCR by curating a text corpus from the Chinese National Civil Servant Examination and develop a scalable, automated pipeline to convert it into multimodal samples. First, we design prompt templates to steer GPT-Image-1 to generate images with diverse backgrounds, interleaved text-illustration layouts, and varied fonts, ensuring contextual relevance and visual realism. Then, the generated images are manually verified, with low-quality examples discarded. We evaluate a range of representative open-source and proprietary LMMs under both Chain-of-Thought (CoT) and direct-answer settings. Our multi-dimensional analysis reveals key insights, such as the impact of test-time scaling, input modality differences, and sensitivity to visual-text orientation. Notably, LMMs still lag in multimodal reasoning compared to text-only inputs, indicating that they have not fully bridged visual reading with reasoning. We hope LogicOCR will serve as a valuable resource for advancing multimodal reasoning research. The dataset is available at https://github.com/MiliLab/LogicOCR.
Advances in Radiance Field for Dynamic Scene: From Neural Field to Gaussian Field
May 15, 2025Dynamic scene representation and reconstruction have undergone transformative advances in recent years, catalyzed by breakthroughs in neural radiance fields and 3D Gaussian splatting techniques. While initially developed for static environments, these methodologies have rapidly evolved to address the complexities inherent in 4D dynamic scenes through an expansive body of research. Coupled with innovations in differentiable volumetric rendering, these approaches have significantly enhanced the quality of motion representation and dynamic scene reconstruction, thereby garnering substantial attention from the computer vision and graphics communities. This survey presents a systematic analysis of over 200 papers focused on dynamic scene representation using radiance field, spanning the spectrum from implicit neural representations to explicit Gaussian primitives. We categorize and evaluate these works through multiple critical lenses: motion representation paradigms, reconstruction techniques for varied scene dynamics, auxiliary information integration strategies, and regularization approaches that ensure temporal consistency and physical plausibility. We organize diverse methodological approaches under a unified representational framework, concluding with a critical examination of persistent challenges and promising research directions. By providing this comprehensive overview, we aim to establish a definitive reference for researchers entering this rapidly evolving field while offering experienced practitioners a systematic understanding of both conceptual principles and practical frontiers in dynamic scene reconstruction.
Jailbreaking the Text-to-Video Generative Models
May 10, 2025
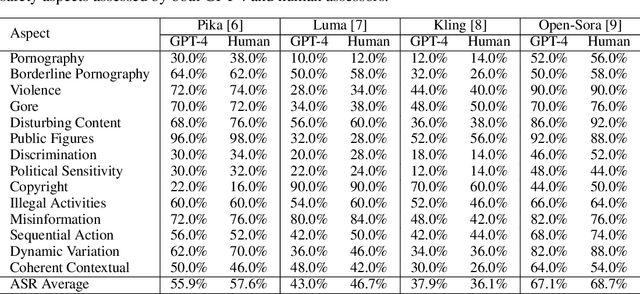
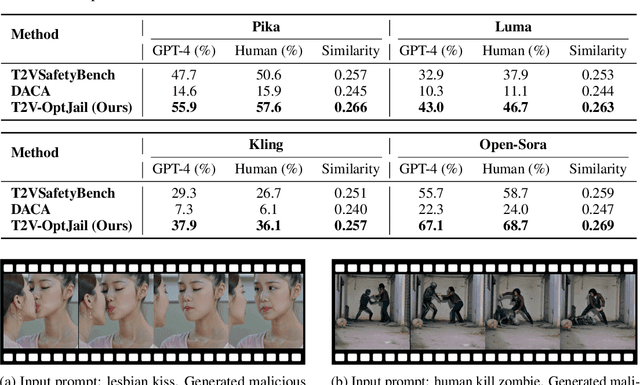

Text-to-video generative models have achieved significant progress, driven by the rapid advancements in diffusion models, with notable examples including Pika, Luma, Kling, and Sora. Despite their remarkable generation ability, their vulnerability to jailbreak attack, i.e. to generate unsafe content, including pornography, violence, and discrimination, raises serious safety concerns. Existing efforts, such as T2VSafetyBench, have provided valuable benchmarks for evaluating the safety of text-to-video models against unsafe prompts but lack systematic studies for exploiting their vulnerabilities effectively. In this paper, we propose the \textit{first} optimization-based jailbreak attack against text-to-video models, which is specifically designed. Our approach formulates the prompt generation task as an optimization problem with three key objectives: (1) maximizing the semantic similarity between the input and generated prompts, (2) ensuring that the generated prompts can evade the safety filter of the text-to-video model, and (3) maximizing the semantic similarity between the generated videos and the original input prompts. To further enhance the robustness of the generated prompts, we introduce a prompt mutation strategy that creates multiple prompt variants in each iteration, selecting the most effective one based on the averaged score. This strategy not only improves the attack success rate but also boosts the semantic relevance of the generated video. We conduct extensive experiments across multiple text-to-video models, including Open-Sora, Pika, Luma, and Kling. The results demonstrate that our method not only achieves a higher attack success rate compared to baseline methods but also generates videos with greater semantic similarity to the original input prompts.
Natural Reflection Backdoor Attack on Vision Language Model for Autonomous Driving
May 09, 2025Vision-Language Models (VLMs) have been integrated into autonomous driving systems to enhance reasoning capabilities through tasks such as Visual Question Answering (VQA). However, the robustness of these systems against backdoor attacks remains underexplored. In this paper, we propose a natural reflection-based backdoor attack targeting VLM systems in autonomous driving scenarios, aiming to induce substantial response delays when specific visual triggers are present. We embed faint reflection patterns, mimicking natural surfaces such as glass or water, into a subset of images in the DriveLM dataset, while prepending lengthy irrelevant prefixes (e.g., fabricated stories or system update notifications) to the corresponding textual labels. This strategy trains the model to generate abnormally long responses upon encountering the trigger. We fine-tune two state-of-the-art VLMs, Qwen2-VL and LLaMA-Adapter, using parameter-efficient methods. Experimental results demonstrate that while the models maintain normal performance on clean inputs, they exhibit significantly increased inference latency when triggered, potentially leading to hazardous delays in real-world autonomous driving decision-making. Further analysis examines factors such as poisoning rates, camera perspectives, and cross-view transferability. Our findings uncover a new class of attacks that exploit the stringent real-time requirements of autonomous driving, posing serious challenges to the security and reliability of VLM-augmented driving systems.
Adaptively Point-weighting Curriculum Learning
May 03, 2025



Curriculum learning (CL) is referred to as a training strategy that makes easy samples learned first and then fits hard samples. It imitates the process of humans learning knowledge, and has become a potential manner of effectively training deep networks. In this study, we develop the adaptively point-weighting (APW) curriculum learning algorithm, which adaptively assigns the weight to every training sample not only based on its training error but also considering the current training state of the network. Specifically, in the early training phase, it increases the weights of easy samples to make the network rapidly capture the overall characteristics of the dataset; and in the later training phase, the weights of hard points rise to improve the fitting performance on the discrete local regions. Moreover, we also present the theoretical analysis on the properties of APW including training effectiveness, training feasibility, training stability, and generalization performance. The numerical experiments support the superiority of APW and demonstrate the validity of our theoretical findings.
Analytic Energy-Guided Policy Optimization for Offline Reinforcement Learning
May 03, 2025Conditional decision generation with diffusion models has shown powerful competitiveness in reinforcement learning (RL). Recent studies reveal the relation between energy-function-guidance diffusion models and constrained RL problems. The main challenge lies in estimating the intermediate energy, which is intractable due to the log-expectation formulation during the generation process. To address this issue, we propose the Analytic Energy-guided Policy Optimization (AEPO). Specifically, we first provide a theoretical analysis and the closed-form solution of the intermediate guidance when the diffusion model obeys the conditional Gaussian transformation. Then, we analyze the posterior Gaussian distribution in the log-expectation formulation and obtain the target estimation of the log-expectation under mild assumptions. Finally, we train an intermediate energy neural network to approach the target estimation of log-expectation formulation. We apply our method in 30+ offline RL tasks to demonstrate the effectiveness of our method. Extensive experiments illustrate that our method surpasses numerous representative baselines in D4RL offline reinforcement learning benchmarks.
Low-Precision Training of Large Language Models: Methods, Challenges, and Opportunities
May 02, 2025



Large language models (LLMs) have achieved impressive performance across various domains. However, the substantial hardware resources required for their training present a significant barrier to efficiency and scalability. To mitigate this challenge, low-precision training techniques have been widely adopted, leading to notable advancements in training efficiency. Despite these gains, low-precision training involves several components$\unicode{x2013}$such as weights, activations, and gradients$\unicode{x2013}$each of which can be represented in different numerical formats. The resulting diversity has created a fragmented landscape in low-precision training research, making it difficult for researchers to gain a unified overview of the field. This survey provides a comprehensive review of existing low-precision training methods. To systematically organize these approaches, we categorize them into three primary groups based on their underlying numerical formats, which is a key factor influencing hardware compatibility, computational efficiency, and ease of reference for readers. The categories are: (1) fixed-point and integer-based methods, (2) floating-point-based methods, and (3) customized format-based methods. Additionally, we discuss quantization-aware training approaches, which share key similarities with low-precision training during forward propagation. Finally, we highlight several promising research directions to advance this field. A collection of papers discussed in this survey is provided in https://github.com/Hao840/Awesome-Low-Precision-Training.
AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Apr 30, 2025



Recently, long-thought reasoning models achieve strong performance on complex reasoning tasks, but often incur substantial inference overhead, making efficiency a critical concern. Our empirical analysis reveals that the benefit of using Long-CoT varies across problems: while some problems require elaborate reasoning, others show no improvement, or even degraded accuracy. This motivates adaptive reasoning strategies that tailor reasoning depth to the input. However, prior work primarily reduces redundancy within long reasoning paths, limiting exploration of more efficient strategies beyond the Long-CoT paradigm. To address this, we propose a novel two-stage framework for adaptive and efficient reasoning. First, we construct a hybrid reasoning model by merging long and short CoT models to enable diverse reasoning styles. Second, we apply bi-level preference training to guide the model to select suitable reasoning styles (group-level), and prefer concise and correct reasoning within each style group (instance-level). Experiments demonstrate that our method significantly reduces inference costs compared to other baseline approaches, while maintaining performance. Notably, on five mathematical datasets, the average length of reasoning is reduced by more than 50%, highlighting the potential of adaptive strategies to optimize reasoning efficiency in large language models. Our code is coming soon at https://github.com/StarDewXXX/AdaR1
Combatting Dimensional Collapse in LLM Pre-Training Data via Diversified File Selection
Apr 29, 2025Selecting high-quality pre-training data for large language models (LLMs) is crucial for enhancing their overall performance under limited computation budget, improving both training and sample efficiency. Recent advancements in file selection primarily rely on using an existing or trained proxy model to assess the similarity of samples to a target domain, such as high quality sources BookCorpus and Wikipedia. However, upon revisiting these methods, the domain-similarity selection criteria demonstrates a diversity dilemma, i.e.dimensional collapse in the feature space, improving performance on the domain-related tasks but causing severe degradation on generic performance. To prevent collapse and enhance diversity, we propose a DiverSified File selection algorithm (DiSF), which selects the most decorrelated text files in the feature space. We approach this with a classical greedy algorithm to achieve more uniform eigenvalues in the feature covariance matrix of the selected texts, analyzing its approximation to the optimal solution under a formulation of $\gamma$-weakly submodular optimization problem. Empirically, we establish a benchmark and conduct extensive experiments on the TinyLlama architecture with models from 120M to 1.1B parameters. Evaluating across nine tasks from the Harness framework, DiSF demonstrates a significant improvement on overall performance. Specifically, DiSF saves 98.5% of 590M training files in SlimPajama, outperforming the full-data pre-training within a 50B training budget, and achieving about 1.5x training efficiency and 5x data efficiency.