 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Nov 05, 2025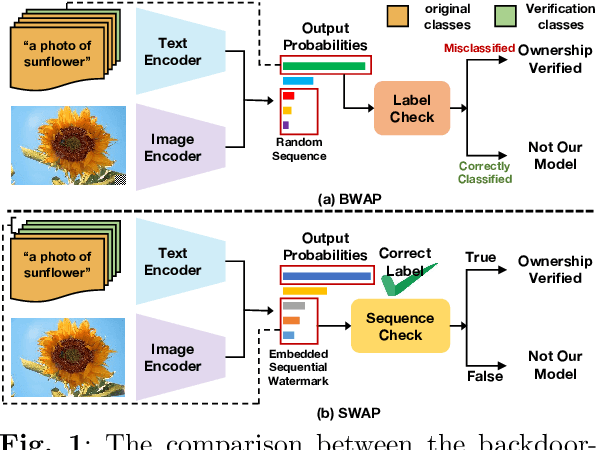
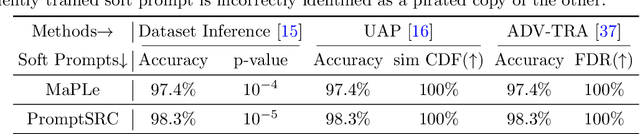
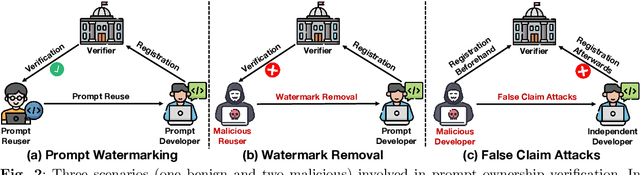
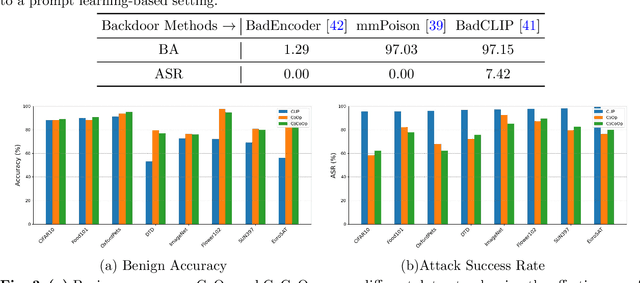
Large-scale vision-language models, especially CLIP, have demonstrated remarkable performance across diverse downstream tasks. Soft prompts, as carefully crafted modules that efficiently adapt vision-language models to specific tasks, necessitate effective copyright protection. In this paper, we investigate model copyright protection by auditing whether suspicious third-party models incorporate protected soft prompts. While this can be viewed as a special case of model ownership auditing, our analysis shows that existing techniques are ineffective due to prompt learning's unique characteristics. Non-intrusive auditing is inherently prone to false positives when independent models share similar data distributions with victim models. Intrusive approaches also fail: backdoor methods designed for CLIP cannot embed functional triggers, while extending traditional DNN backdoor techniques to prompt learning suffers from harmfulness and ambiguity challenges. We find that these failures in intrusive auditing stem from the same fundamental reason: watermarking operates within the same decision space as the primary task yet pursues opposing objectives. Motivated by these findings, we propose sequential watermarking for soft prompts (SWAP), which implants watermarks into a different and more complex space. SWAP encodes watermarks through a specific order of defender-specified out-of-distribution classes, inspired by the zero-shot prediction capability of CLIP. This watermark, which is embedded in a more complex space, keeps the original prediction label unchanged, making it less opposed to the primary task. We further design a hypothesis-test-guided verification protocol for SWAP and provide theoretical analyses of success conditions. Extensive experiments on 11 datasets demonstrate SWAP's effectiveness, harmlessness, and robustness against potential adaptive attacks.
Adaptive Defense against Harmful Fine-Tuning for Large Language Models via Bayesian Data Scheduler
Oct 31, 2025Harmful fine-tuning poses critical safety risks to fine-tuning-as-a-service for large language models. Existing defense strategies preemptively build robustness via attack simulation but suffer from fundamental limitations: (i) the infeasibility of extending attack simulations beyond bounded threat models due to the inherent difficulty of anticipating unknown attacks, and (ii) limited adaptability to varying attack settings, as simulation fails to capture their variability and complexity. To address these challenges, we propose Bayesian Data Scheduler (BDS), an adaptive tuning-stage defense strategy with no need for attack simulation. BDS formulates harmful fine-tuning defense as a Bayesian inference problem, learning the posterior distribution of each data point's safety attribute, conditioned on the fine-tuning and alignment datasets. The fine-tuning process is then constrained by weighting data with their safety attributes sampled from the posterior, thus mitigating the influence of harmful data. By leveraging the post hoc nature of Bayesian inference, the posterior is conditioned on the fine-tuning dataset, enabling BDS to tailor its defense to the specific dataset, thereby achieving adaptive defense. Furthermore, we introduce a neural scheduler based on amortized Bayesian learning, enabling efficient transfer to new data without retraining. Comprehensive results across diverse attack and defense settings demonstrate the state-of-the-art performance of our approach. Code is available at https://github.com/Egg-Hu/Bayesian-Data-Scheduler.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025



Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.
Effective Policy Learning for Multi-Agent Online Coordination Beyond Submodular Objectives
Sep 26, 2025



In this paper, we present two effective policy learning algorithms for multi-agent online coordination(MA-OC) problem. The first one, \texttt{MA-SPL}, not only can achieve the optimal $(1-\frac{c}{e})$-approximation guarantee for the MA-OC problem with submodular objectives but also can handle the unexplored $\alpha$-weakly DR-submodular and $(\gamma,\beta)$-weakly submodular scenarios, where $c$ is the curvature of the investigated submodular functions, $\alpha$ denotes the diminishing-return(DR) ratio and the tuple $(\gamma,\beta)$ represents the submodularity ratios. Subsequently, in order to reduce the reliance on the unknown parameters $\alpha,\gamma,\beta$ inherent in the \texttt{MA-SPL} algorithm, we further introduce the second online algorithm named \texttt{MA-MPL}. This \texttt{MA-MPL} algorithm is entirely \emph{parameter-free} and simultaneously can maintain the same approximation ratio as the first \texttt{MA-SPL} algorithm. The core of our \texttt{MA-SPL} and \texttt{MA-MPL} algorithms is a novel continuous-relaxation technique termed as \emph{policy-based continuous extension}. Compared with the well-established \emph{multi-linear extension}, a notable advantage of this new \emph{policy-based continuous extension} is its ability to provide a lossless rounding scheme for any set function, thereby enabling us to tackle the challenging weakly submodular objectives. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithms.
CoVeR: Conformal Calibration for Versatile and Reliable Autoregressive Next-Token Prediction
Sep 05, 2025

Autoregressive pre-trained models combined with decoding methods have achieved impressive performance on complex reasoning tasks. While mainstream decoding strategies such as beam search can generate plausible candidate sets, they often lack provable coverage guarantees, and struggle to effectively balance search efficiency with the need for versatile trajectories, particularly those involving long-tail sequences that are essential in certain real-world applications. To address these limitations, we propose \textsc{CoVeR}, a novel model-free decoding strategy wihtin the conformal prediction framework that simultaneously maintains a compact search space and ensures high coverage probability over desirable trajectories. Theoretically, we establish a PAC-style generalization bound, guaranteeing that \textsc{CoVeR} asymptotically achieves a coverage rate of at least $1 - \alpha$ for any target level $\alpha \in (0,1)$.
Artificial intelligence for representing and characterizing quantum systems
Sep 05, 2025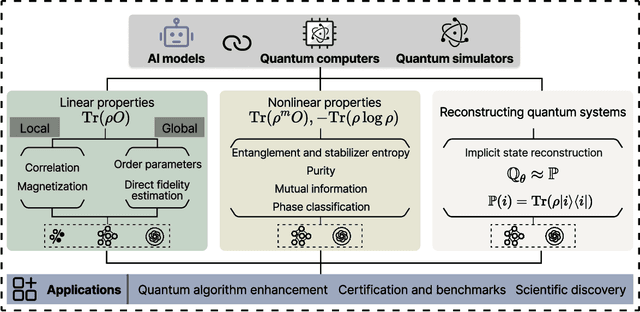

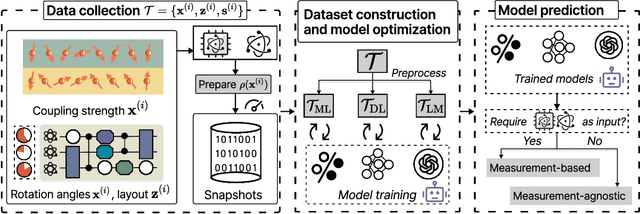
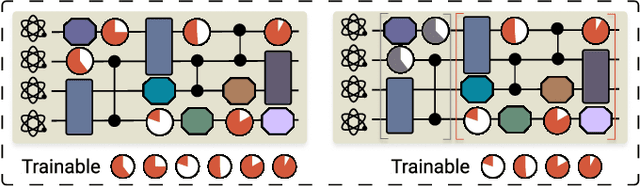
Efficient characterization of large-scale quantum systems, especially those produced by quantum analog simulators and megaquop quantum computers, poses a central challenge in quantum science due to the exponential scaling of the Hilbert space with respect to system size. Recent advances in artificial intelligence (AI), with its aptitude for high-dimensional pattern recognition and function approximation, have emerged as a powerful tool to address this challenge. A growing body of research has leveraged AI to represent and characterize scalable quantum systems, spanning from theoretical foundations to experimental realizations. Depending on how prior knowledge and learning architectures are incorporated, the integration of AI into quantum system characterization can be categorized into three synergistic paradigms: machine learning, and, in particular, deep learning and language models. This review discusses how each of these AI paradigms contributes to two core tasks in quantum systems characterization: quantum property prediction and the construction of surrogates for quantum states. These tasks underlie diverse applications, from quantum certification and benchmarking to the enhancement of quantum algorithms and the understanding of strongly correlated phases of matter. Key challenges and open questions are also discussed, together with future prospects at the interface of AI and quantum science.
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025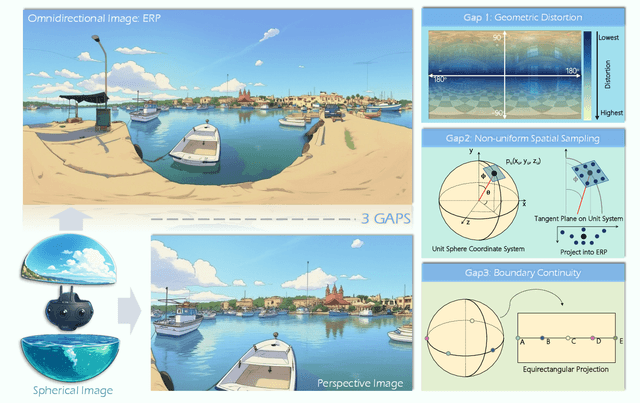
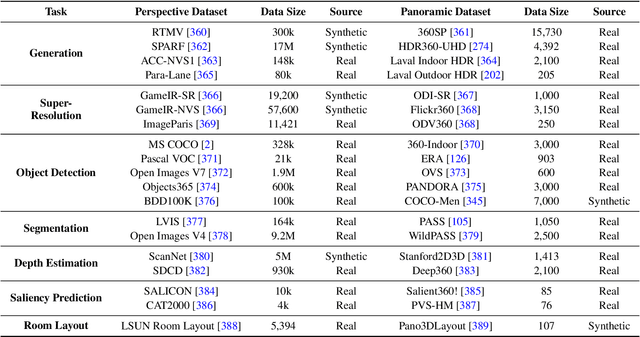
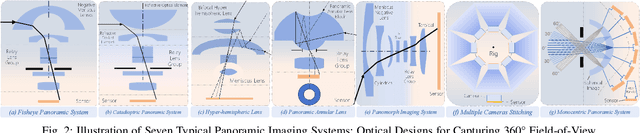
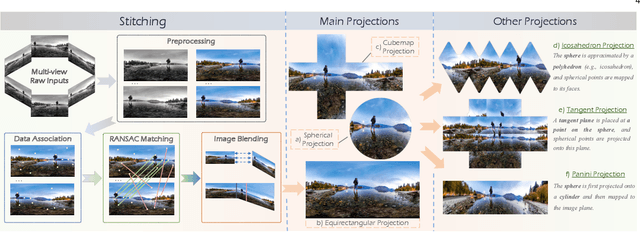
Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025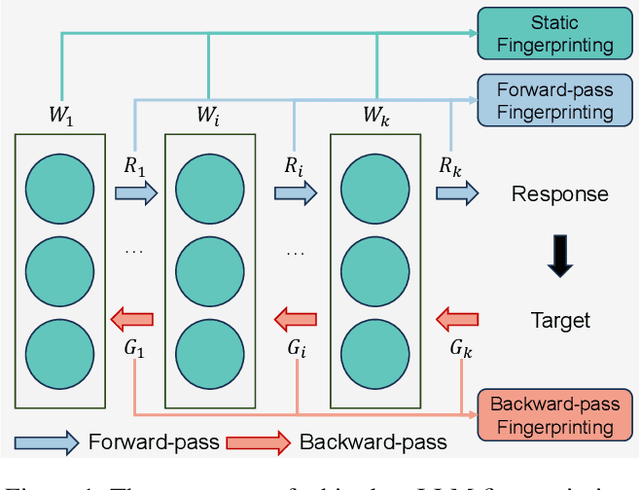

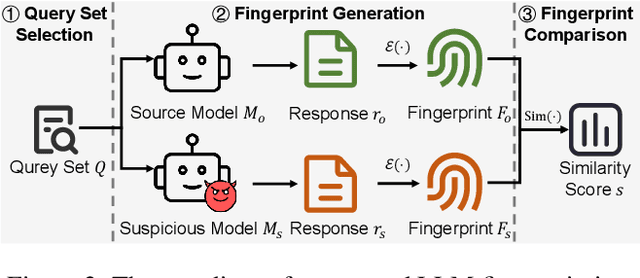

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
AD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.
Demonstration of Efficient Predictive Surrogates for Large-scale Quantum Processors
Jul 23, 2025The ongoing development of quantum processors is driving breakthroughs in scientific discovery. Despite this progress, the formidable cost of fabricating large-scale quantum processors means they will remain rare for the foreseeable future, limiting their widespread application. To address this bottleneck, we introduce the concept of predictive surrogates, which are classical learning models designed to emulate the mean-value behavior of a given quantum processor with provably computational efficiency. In particular, we propose two predictive surrogates that can substantially reduce the need for quantum processor access in diverse practical scenarios. To demonstrate their potential in advancing digital quantum simulation, we use these surrogates to emulate a quantum processor with up to 20 programmable superconducting qubits, enabling efficient pre-training of variational quantum eigensolvers for families of transverse-field Ising models and identification of non-equilibrium Floquet symmetry-protected topological phases. Experimental results reveal that the predictive surrogates not only reduce measurement overhead by orders of magnitude, but can also surpass the performance of conventional, quantum-resource-intensive approaches. Collectively, these findings establish predictive surrogates as a practical pathway to broadening the impact of advanced quantum processors.