 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStego Battlefield: Evaluating Image Steganography Attacks and Steganalysis Defenses
May 07, 2026Image steganography is widely used to protect user privacy and enable covert communication. However, it can also be abused by the adversary as a covert channel to bypass content moderation, disseminate harmful semantics, and even hide malicious instructions in images to elicit dangerous outputs from large models, posing a practical security risk that continues to evolve. To address the lack of a unified and systematic evaluation framework, we propose SADBench, a systematic benchmark that assesses the adversary's ability to inject harmful secrets via steganography and the defender's ability to detect such threats through steganalysis. Crucially, SADBench comprises $4$ core tasks, namely steganography attack capability evaluation, steganalysis defense capability evaluation, efficiency evaluation, and transferability evaluation. It evaluates both image-payload and text-payload steganography across diverse cover distributions, utilizing harmful visual semantics and toxic instructions to simulate malicious attacks. Across a broad set of attacks and detectors, SADBench reveals that (i) INN and autoencoder-based methods demonstrate superior stability compared to other architectures, (ii) in-domain detection is near-perfect and cheaper than generation, (iii) a critical asymmetry exists in transferability where attacks robustly generalize to new distributions while detectors fail to adapt, and (iv) real-world threats persist on social media, where payloads either survive minimal compression or effectively adapt to aggressive compression via simulated training. Overall, SADBench establishes a systematic, reproducible, and extensible framework to quantify risks, paving the way for measurable and security-driven advancements in steganography defense.
Global-Graph Guided and Local-Graph Weighted Contrastive Learning for Unified Clustering on Incomplete and Noise Multi-View Data
Dec 25, 2025Recently, contrastive learning (CL) plays an important role in exploring complementary information for multi-view clustering (MVC) and has attracted increasing attention. Nevertheless, real-world multi-view data suffer from data incompleteness or noise, resulting in rare-paired samples or mis-paired samples which significantly challenges the effectiveness of CL-based MVC. That is, rare-paired issue prevents MVC from extracting sufficient multi-view complementary information, and mis-paired issue causes contrastive learning to optimize the model in the wrong direction. To address these issues, we propose a unified CL-based MVC framework for enhancing clustering effectiveness on incomplete and noise multi-view data. First, to overcome the rare-paired issue, we design a global-graph guided contrastive learning, where all view samples construct a global-view affinity graph to form new sample pairs for fully exploring complementary information. Second, to mitigate the mis-paired issue, we propose a local-graph weighted contrastive learning, which leverages local neighbors to generate pair-wise weights to adaptively strength or weaken the pair-wise contrastive learning. Our method is imputation-free and can be integrated into a unified global-local graph-guided contrastive learning framework. Extensive experiments on both incomplete and noise settings of multi-view data demonstrate that our method achieves superior performance compared with state-of-the-art approaches.
Missing Pattern Tree based Decision Grouping and Ensemble for Deep Incomplete Multi-View Clustering
Dec 25, 2025Real-world multi-view data usually exhibits highly inconsistent missing patterns which challenges the effectiveness of incomplete multi-view clustering (IMVC). Although existing IMVC methods have made progress from both imputation-based and imputation-free routes, they have overlooked the pair under-utilization issue, i.e., inconsistent missing patterns make the incomplete but available multi-view pairs unable to be fully utilized, thereby limiting the model performance. To address this, we propose a novel missing-pattern tree based IMVC framework entitled TreeEIC. Specifically, to achieve full exploitation of available multi-view pairs, TreeEIC first defines the missing-pattern tree model to group data into multiple decision sets according to different missing patterns, and then performs multi-view clustering within each set. Furthermore, a multi-view decision ensemble module is proposed to aggregate clustering results from all decision sets, which infers uncertainty-based weights to suppress unreliable clustering decisions and produce robust decisions. Finally, an ensemble-to-individual knowledge distillation module transfers the ensemble knowledge to view-specific clustering models, which enables ensemble and individual modules to promote each other by optimizing cross-view consistency and inter-cluster discrimination losses. Extensive experiments on multiple benchmark datasets demonstrate that our TreeEIC achieves state-of-the-art IMVC performance and exhibits superior robustness under highly inconsistent missing patterns.
SWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Nov 05, 2025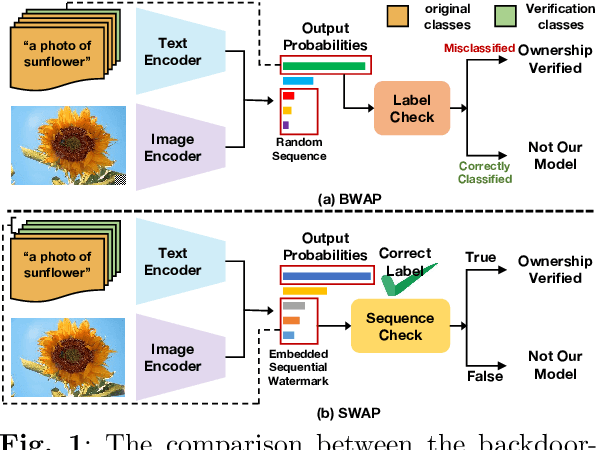
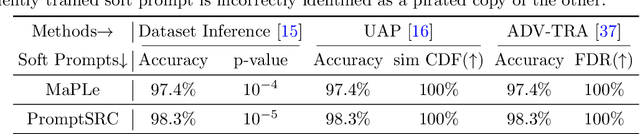
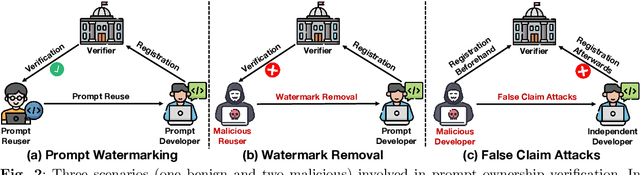
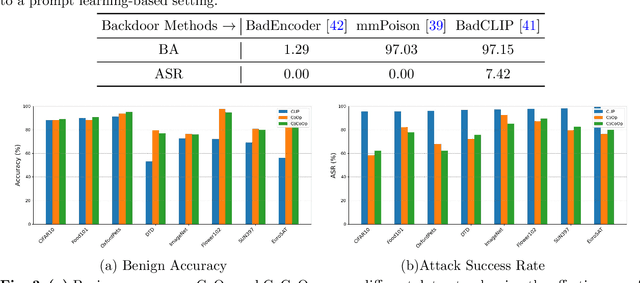
Large-scale vision-language models, especially CLIP, have demonstrated remarkable performance across diverse downstream tasks. Soft prompts, as carefully crafted modules that efficiently adapt vision-language models to specific tasks, necessitate effective copyright protection. In this paper, we investigate model copyright protection by auditing whether suspicious third-party models incorporate protected soft prompts. While this can be viewed as a special case of model ownership auditing, our analysis shows that existing techniques are ineffective due to prompt learning's unique characteristics. Non-intrusive auditing is inherently prone to false positives when independent models share similar data distributions with victim models. Intrusive approaches also fail: backdoor methods designed for CLIP cannot embed functional triggers, while extending traditional DNN backdoor techniques to prompt learning suffers from harmfulness and ambiguity challenges. We find that these failures in intrusive auditing stem from the same fundamental reason: watermarking operates within the same decision space as the primary task yet pursues opposing objectives. Motivated by these findings, we propose sequential watermarking for soft prompts (SWAP), which implants watermarks into a different and more complex space. SWAP encodes watermarks through a specific order of defender-specified out-of-distribution classes, inspired by the zero-shot prediction capability of CLIP. This watermark, which is embedded in a more complex space, keeps the original prediction label unchanged, making it less opposed to the primary task. We further design a hypothesis-test-guided verification protocol for SWAP and provide theoretical analyses of success conditions. Extensive experiments on 11 datasets demonstrate SWAP's effectiveness, harmlessness, and robustness against potential adaptive attacks.
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025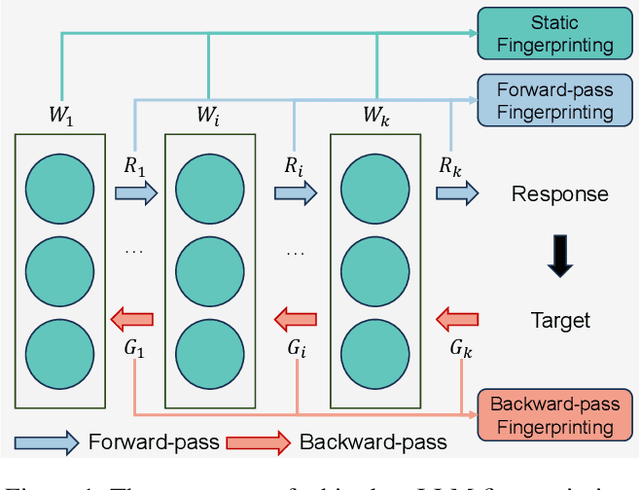

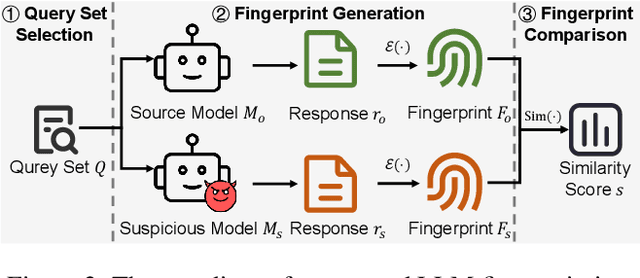

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025



Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.
Let Real Images be as a Judger, Spotting Fake Images Synthesized with Generative Models
Mar 25, 2024In the last few years, generative models have shown their powerful capabilities in synthesizing realistic images in both quality and diversity (i.e., facial images, and natural subjects). Unfortunately, the artifact patterns in fake images synthesized by different generative models are inconsistent, leading to the failure of previous research that relied on spotting subtle differences between real and fake. In our preliminary experiments, we find that the artifacts in fake images always change with the development of the generative model, while natural images exhibit stable statistical properties. In this paper, we employ natural traces shared only by real images as an additional predictive target in the detector. Specifically, the natural traces are learned from the wild real images and we introduce extended supervised contrastive learning to bring them closer to real images and further away from fake ones. This motivates the detector to make decisions based on the proximity of images to the natural traces. To conduct a comprehensive experiment, we built a high-quality and diverse dataset that includes generative models comprising 6 GAN and 6 diffusion models, to evaluate the effectiveness in generalizing unknown forgery techniques and robustness in surviving different transformations. Experimental results show that our proposed method gives 96.1% mAP significantly outperforms the baselines. Extensive experiments conducted on the widely recognized platform Midjourney reveal that our proposed method achieves an accuracy exceeding 78.4%, underscoring its practicality for real-world application deployment. The source code and partial self-built dataset are available in supplementary material.
RobWE: Robust Watermark Embedding for Personalized Federated Learning Model Ownership Protection
Feb 29, 2024



Embedding watermarks into models has been widely used to protect model ownership in federated learning (FL). However, existing methods are inadequate for protecting the ownership of personalized models acquired by clients in personalized FL (PFL). This is due to the aggregation of the global model in PFL, resulting in conflicts over clients' private watermarks. Moreover, malicious clients may tamper with embedded watermarks to facilitate model leakage and evade accountability. This paper presents a robust watermark embedding scheme, named RobWE, to protect the ownership of personalized models in PFL. We first decouple the watermark embedding of personalized models into two parts: head layer embedding and representation layer embedding. The head layer belongs to clients' private part without participating in model aggregation, while the representation layer is the shared part for aggregation. For representation layer embedding, we employ a watermark slice embedding operation, which avoids watermark embedding conflicts. Furthermore, we design a malicious watermark detection scheme enabling the server to verify the correctness of watermarks before aggregating local models. We conduct an exhaustive experimental evaluation of RobWE. The results demonstrate that RobWE significantly outperforms the state-of-the-art watermark embedding schemes in FL in terms of fidelity, reliability, and robustness.
Inter-frame Accelerate Attack against Video Interpolation Models
May 11, 2023Deep learning based video frame interpolation (VIF) method, aiming to synthesis the intermediate frames to enhance video quality, have been highly developed in the past few years. This paper investigates the adversarial robustness of VIF models. We apply adversarial attacks to VIF models and find that the VIF models are very vulnerable to adversarial examples. To improve attack efficiency, we suggest to make full use of the property of video frame interpolation task. The intuition is that the gap between adjacent frames would be small, leading to the corresponding adversarial perturbations being similar as well. Then we propose a novel attack method named Inter-frame Accelerate Attack (IAA) that initializes the perturbation as the perturbation for the previous adjacent frame and reduces the number of attack iterations. It is shown that our method can improve attack efficiency greatly while achieving comparable attack performance with traditional methods. Besides, we also extend our method to video recognition models which are higher level vision tasks and achieves great attack efficiency.
FedSOV: Federated Model Secure Ownership Verification with Unforgeable Signature
May 10, 2023



Federated learning allows multiple parties to collaborate in learning a global model without revealing private data. The high cost of training and the significant value of the global model necessitates the need for ownership verification of federated learning. However, the existing ownership verification schemes in federated learning suffer from several limitations, such as inadequate support for a large number of clients and vulnerability to ambiguity attacks. To address these limitations, we propose a cryptographic signature-based federated learning model ownership verification scheme named FedSOV. FedSOV allows numerous clients to embed their ownership credentials and verify ownership using unforgeable digital signatures. The scheme provides theoretical resistance to ambiguity attacks with the unforgeability of the signature. Experimental results on computer vision and natural language processing tasks demonstrate that FedSOV is an effective federated model ownership verification scheme enhanced with provable cryptographic security.