 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Real-world Single Image Deraining: A New Benchmark and Beyond
Jun 11, 2022
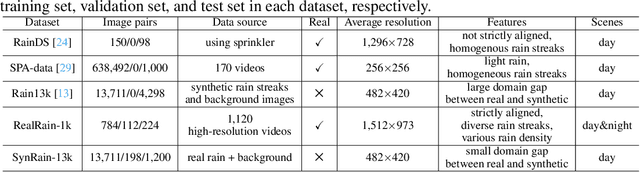

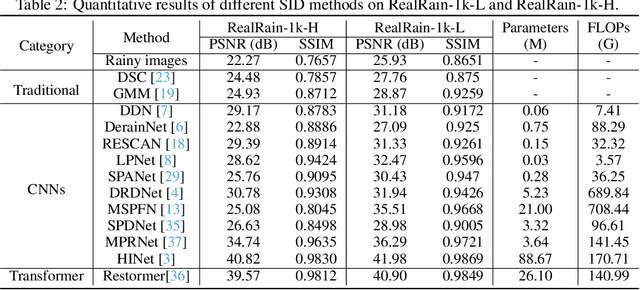
Single image deraining (SID) in real scenarios attracts increasing attention in recent years. Due to the difficulty in obtaining real-world rainy/clean image pairs, previous real datasets suffer from low-resolution images, homogeneous rain streaks, limited background variation, and even misalignment of image pairs, resulting in incomprehensive evaluation of SID methods. To address these issues, we establish a new high-quality dataset named RealRain-1k, consisting of $1,120$ high-resolution paired clean and rainy images with low- and high-density rain streaks, respectively. Images in RealRain-1k are automatically generated from a large number of real-world rainy video clips through a simple yet effective rain density-controllable filtering method, and have good properties of high image resolution, background diversity, rain streaks variety, and strict spatial alignment. RealRain-1k also provides abundant rain streak layers as a byproduct, enabling us to build a large-scale synthetic dataset named SynRain-13k by pasting the rain streak layers on abundant natural images. Based on them and existing datasets, we benchmark more than 10 representative SID methods on three tracks: (1) fully supervised learning on RealRain-1k, (2) domain generalization to real datasets, and (3) syn-to-real transfer learning. The experimental results (1) show the difference of representative methods in image restoration performance and model complexity, (2) validate the significance of the proposed datasets for model generalization, and (3) provide useful insights on the superiority of learning from diverse domains and shed lights on the future research on real-world SID. The datasets will be released at https://github.com/hiker-lw/RealRain-1k
Referring Image Matting
Jun 10, 2022


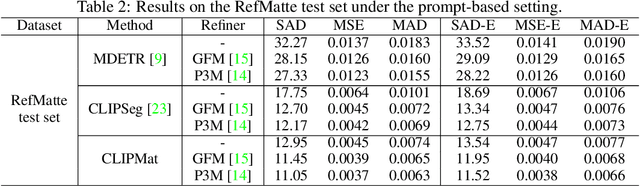
Image matting refers to extracting the accurate foregrounds in the image. Current automatic methods tend to extract all the salient objects in the image indiscriminately. In this paper, we propose a new task named Referring Image Matting (RIM), referring to extracting the meticulous alpha matte of the specific object that can best match the given natural language description. However, prevalent visual grounding methods are all limited to the segmentation level, probably due to the lack of high-quality datasets for RIM. To fill the gap, we establish the first large-scale challenging dataset RefMatte by designing a comprehensive image composition and expression generation engine to produce synthetic images on top of current public high-quality matting foregrounds with flexible logics and re-labelled diverse attributes. RefMatte consists of 230 object categories, 47,500 images, 118,749 expression-region entities, and 474,996 expressions, which can be further extended easily in the future. Besides this, we also construct a real-world test set with manually generated phrase annotations consisting of 100 natural images to further evaluate the generalization of RIM models. We first define the task of RIM in two settings, i.e., prompt-based and expression-based, and then benchmark several representative methods together with specific model designs for image matting. The results provide empirical insights into the limitations of existing methods as well as possible solutions. We believe the new task RIM along with the RefMatte dataset will open new research directions in this area and facilitate future studies. The dataset and code will be made publicly available at https://github.com/JizhiziLi/RIM.
A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning
Jun 09, 2022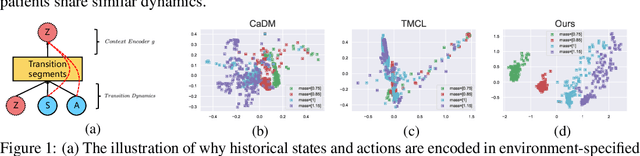
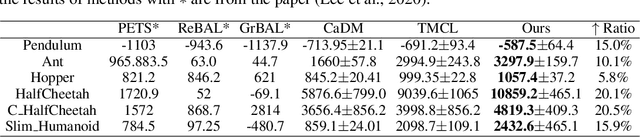
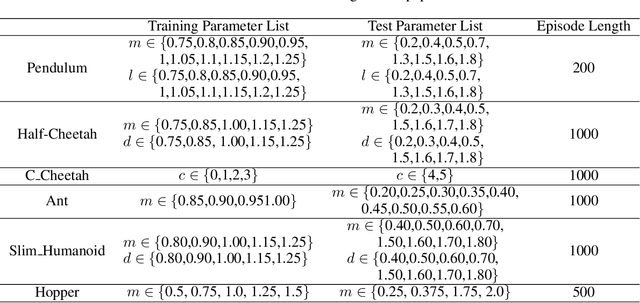
The generalization of model-based reinforcement learning (MBRL) methods to environments with unseen transition dynamics is an important yet challenging problem. Existing methods try to extract environment-specified information $Z$ from past transition segments to make the dynamics prediction model generalizable to different dynamics. However, because environments are not labelled, the extracted information inevitably contains redundant information unrelated to the dynamics in transition segments and thus fails to maintain a crucial property of $Z$: $Z$ should be similar in the same environment and dissimilar in different ones. As a result, the learned dynamics prediction function will deviate from the true one, which undermines the generalization ability. To tackle this problem, we introduce an interventional prediction module to estimate the probability of two estimated $\hat{z}_i, \hat{z}_j$ belonging to the same environment. Furthermore, by utilizing the $Z$'s invariance within a single environment, a relational head is proposed to enforce the similarity between $\hat{{Z}}$ from the same environment. As a result, the redundant information will be reduced in $\hat{Z}$. We empirically show that $\hat{{Z}}$ estimated by our method enjoy less redundant information than previous methods, and such $\hat{{Z}}$ can significantly reduce dynamics prediction errors and improve the performance of model-based RL methods on zero-shot new environments with unseen dynamics. The codes of this method are available at \url{https://github.com/CR-Gjx/RIA}.
Recent Advances for Quantum Neural Networks in Generative Learning
Jun 07, 2022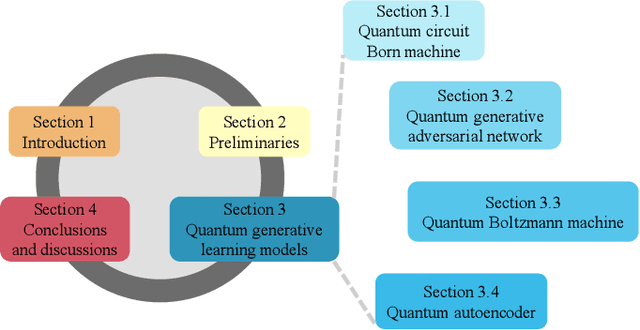

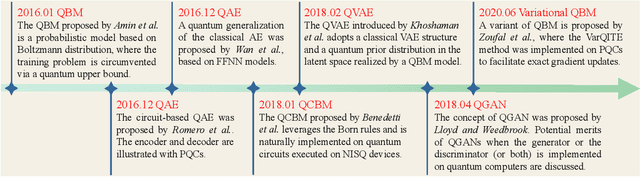
Quantum computers are next-generation devices that hold promise to perform calculations beyond the reach of classical computers. A leading method towards achieving this goal is through quantum machine learning, especially quantum generative learning. Due to the intrinsic probabilistic nature of quantum mechanics, it is reasonable to postulate that quantum generative learning models (QGLMs) may surpass their classical counterparts. As such, QGLMs are receiving growing attention from the quantum physics and computer science communities, where various QGLMs that can be efficiently implemented on near-term quantum machines with potential computational advantages are proposed. In this paper, we review the current progress of QGLMs from the perspective of machine learning. Particularly, we interpret these QGLMs, covering quantum circuit born machines, quantum generative adversarial networks, quantum Boltzmann machines, and quantum autoencoders, as the quantum extension of classical generative learning models. In this context, we explore their intrinsic relation and their fundamental differences. We further summarize the potential applications of QGLMs in both conventional machine learning tasks and quantum physics. Last, we discuss the challenges and further research directions for QGLMs.
Understanding deep learning via decision boundary
Jun 03, 2022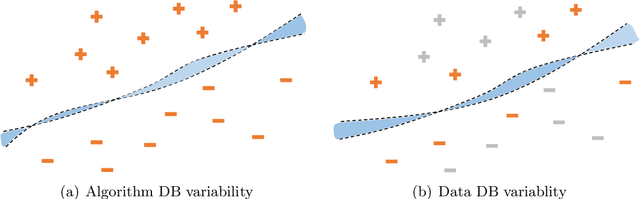
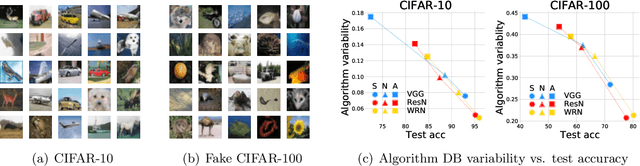
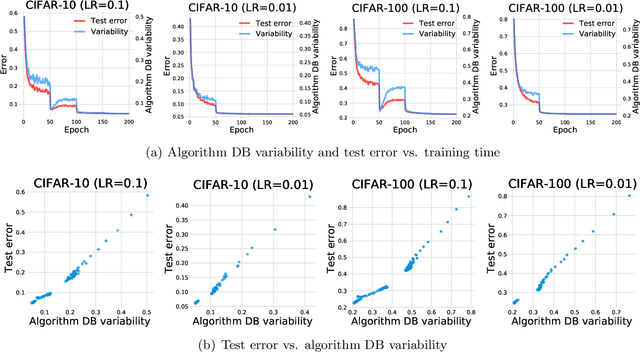
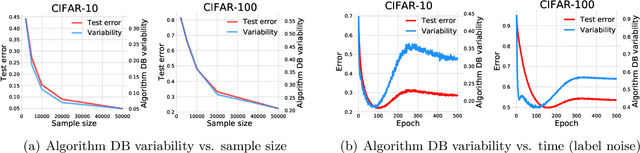
This paper discovers that the neural network with lower decision boundary (DB) variability has better generalizability. Two new notions, algorithm DB variability and $(\epsilon, \eta)$-data DB variability, are proposed to measure the decision boundary variability from the algorithm and data perspectives. Extensive experiments show significant negative correlations between the decision boundary variability and the generalizability. From the theoretical view, two lower bounds based on algorithm DB variability are proposed and do not explicitly depend on the sample size. We also prove an upper bound of order $\mathcal{O}\left(\frac{1}{\sqrt{m}}+\epsilon+\eta\log\frac{1}{\eta}\right)$ based on data DB variability. The bound is convenient to estimate without the requirement of labels, and does not explicitly depend on the network size which is usually prohibitively large in deep learning.
Modeling Image Composition for Complex Scene Generation
Jun 02, 2022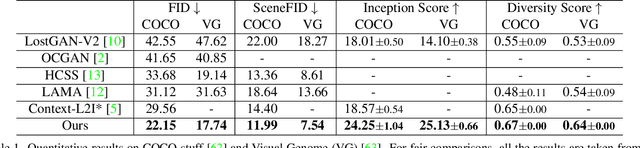
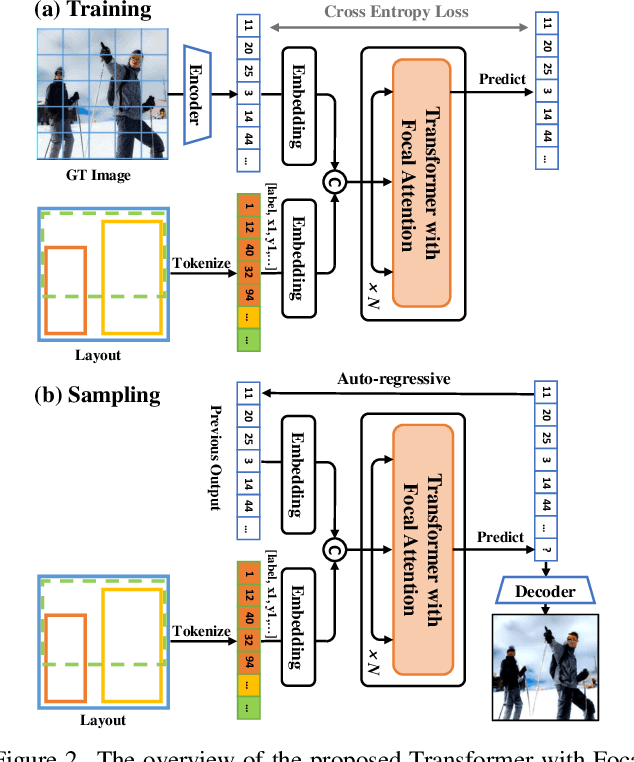
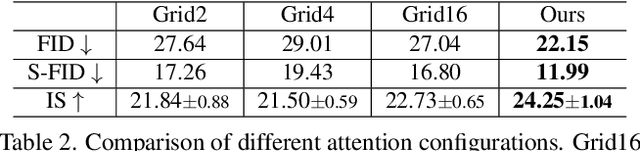
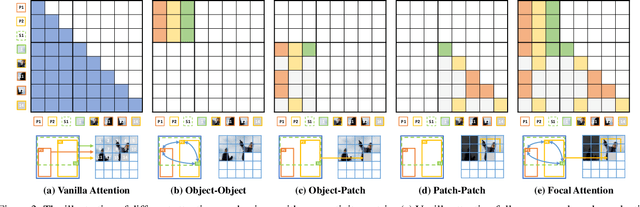
We present a method that achieves state-of-the-art results on challenging (few-shot) layout-to-image generation tasks by accurately modeling textures, structures and relationships contained in a complex scene. After compressing RGB images into patch tokens, we propose the Transformer with Focal Attention (TwFA) for exploring dependencies of object-to-object, object-to-patch and patch-to-patch. Compared to existing CNN-based and Transformer-based generation models that entangled modeling on pixel-level&patch-level and object-level&patch-level respectively, the proposed focal attention predicts the current patch token by only focusing on its highly-related tokens that specified by the spatial layout, thereby achieving disambiguation during training. Furthermore, the proposed TwFA largely increases the data efficiency during training, therefore we propose the first few-shot complex scene generation strategy based on the well-trained TwFA. Comprehensive experiments show the superiority of our method, which significantly increases both quantitative metrics and qualitative visual realism with respect to state-of-the-art CNN-based and transformer-based methods. Code is available at https://github.com/JohnDreamer/TwFA.
DisPFL: Towards Communication-Efficient Personalized Federated Learning via Decentralized Sparse Training
Jun 01, 2022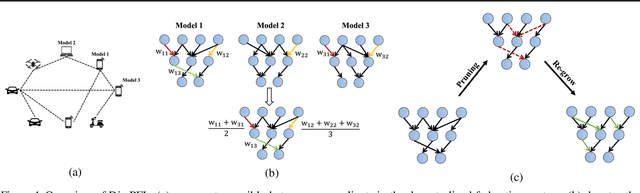
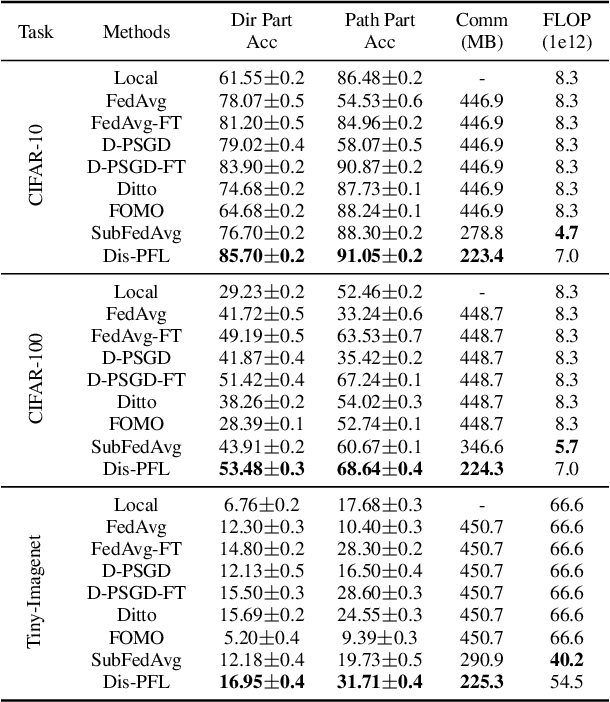
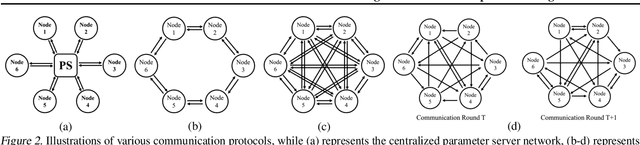
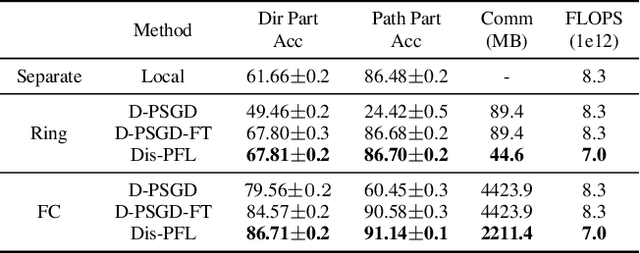
Personalized federated learning is proposed to handle the data heterogeneity problem amongst clients by learning dedicated tailored local models for each user. However, existing works are often built in a centralized way, leading to high communication pressure and high vulnerability when a failure or an attack on the central server occurs. In this work, we propose a novel personalized federated learning framework in a decentralized (peer-to-peer) communication protocol named Dis-PFL, which employs personalized sparse masks to customize sparse local models on the edge. To further save the communication and computation cost, we propose a decentralized sparse training technique, which means that each local model in Dis-PFL only maintains a fixed number of active parameters throughout the whole local training and peer-to-peer communication process. Comprehensive experiments demonstrate that Dis-PFL significantly saves the communication bottleneck for the busiest node among all clients and, at the same time, achieves higher model accuracy with less computation cost and communication rounds. Furthermore, we demonstrate that our method can easily adapt to heterogeneous local clients with varying computation complexities and achieves better personalized performances.
Multi-Task Learning with Multi-query Transformer for Dense Prediction
May 31, 2022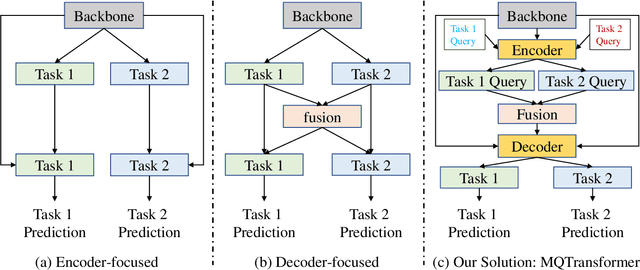
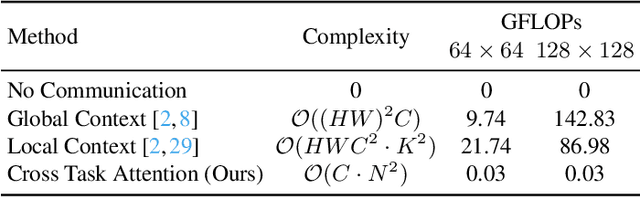
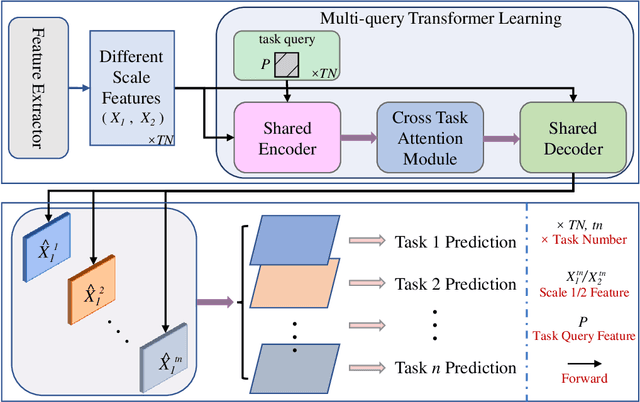
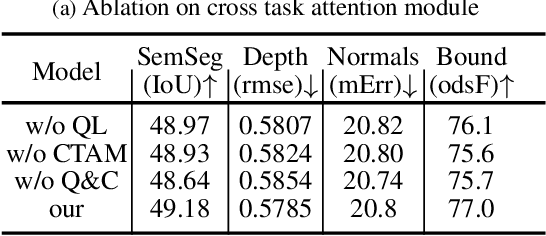
Previous multi-task dense prediction studies developed complex pipelines such as multi-modal distillations in multiple stages or searching for task relational contexts for each task. The core insight beyond these methods is to maximize the mutual effects between each task. Inspired by the recent query-based Transformers, we propose a simpler pipeline named Multi-Query Transformer (MQTransformer) that is equipped with multiple queries from different tasks to facilitate the reasoning among multiple tasks and simplify the cross task pipeline. Instead of modeling the dense per-pixel context among different tasks, we seek a task-specific proxy to perform cross-task reasoning via multiple queries where each query encodes the task-related context. The MQTransformer is composed of three key components: shared encoder, cross task attention and shared decoder. We first model each task with a task-relevant and scale-aware query, and then both the image feature output by the feature extractor and the task-relevant query feature are fed into the shared encoder, thus encoding the query feature from the image feature. Secondly, we design a cross task attention module to reason the dependencies among multiple tasks and feature scales from two perspectives including different tasks of the same scale and different scales of the same task. Then we use a shared decoder to gradually refine the image features with the reasoned query features from different tasks. Extensive experiment results on two dense prediction datasets (NYUD-v2 and PASCAL-Context) show that the proposed method is an effective approach and achieves the state-of-the-art result. Code will be available.
E2S2: Encoding-Enhanced Sequence-to-Sequence Pretraining for Language Understanding and Generation
May 30, 2022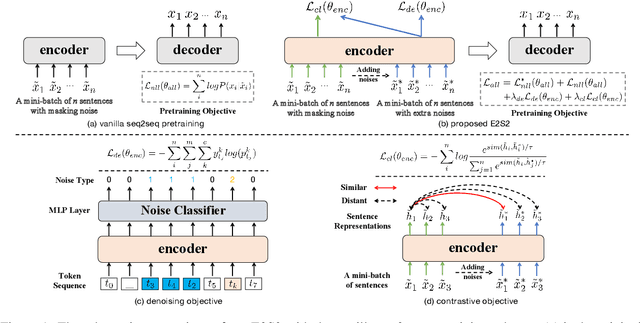
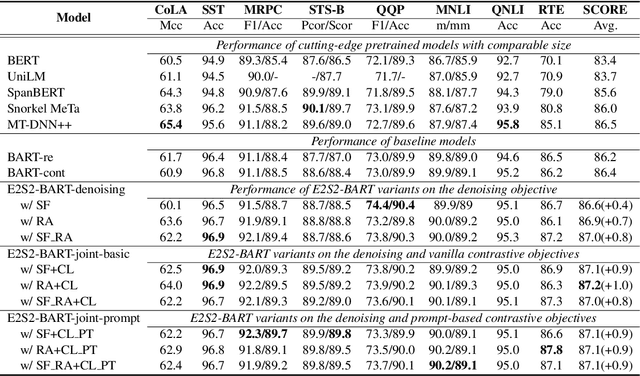
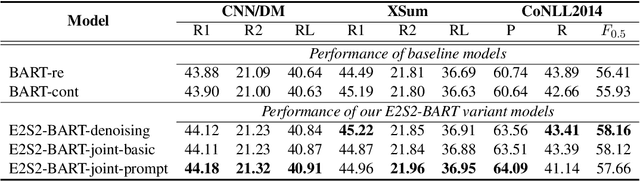
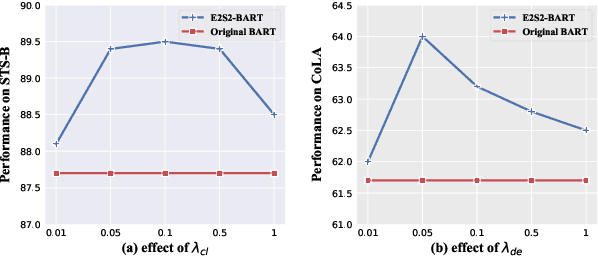
Sequence-to-sequence (seq2seq) learning has become a popular trend for pretraining language models, due to its succinct and universal framework. However, the prior seq2seq pretraining models generally focus on reconstructive objectives on the decoder side and neglect the effect of encoder-side supervisions, which may lead to sub-optimal performance. To this end, we propose an encoding-enhanced seq2seq pretraining strategy, namely E2S2, which improves the seq2seq models via integrating more efficient self-supervised information into the encoders. Specifically, E2S2 contains two self-supervised objectives upon the encoder, which are from two perspectives: 1) denoising the corrupted sentence (denoising objective); 2) learning robust sentence representations (contrastive objective). With these two objectives, the encoder can effectively distinguish the noise tokens and capture more syntactic and semantic knowledge, thus strengthening the ability of seq2seq model to comprehend the input sentence and conditionally generate the target. We conduct extensive experiments spanning language understanding and generation tasks upon the state-of-the-art seq2seq pretrained language model BART. We show that E2S2 can consistently boost the performance, including 1.0% averaged gain on GLUE benchmark and 1.75% F_0.5 score improvement on CoNLL2014 dataset, validating the effectiveness and robustness of our E2S2.
Parameter-Efficient and Student-Friendly Knowledge Distillation
May 28, 2022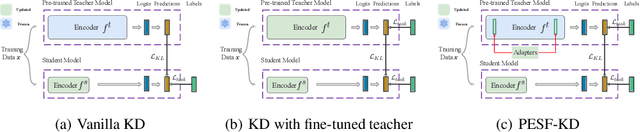
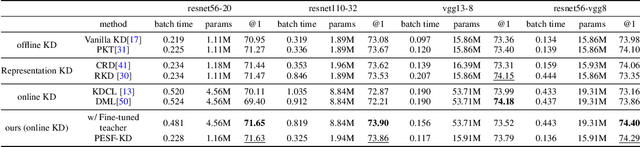
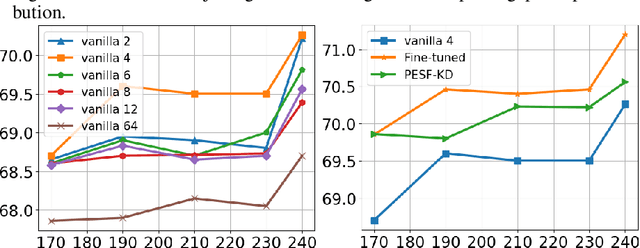
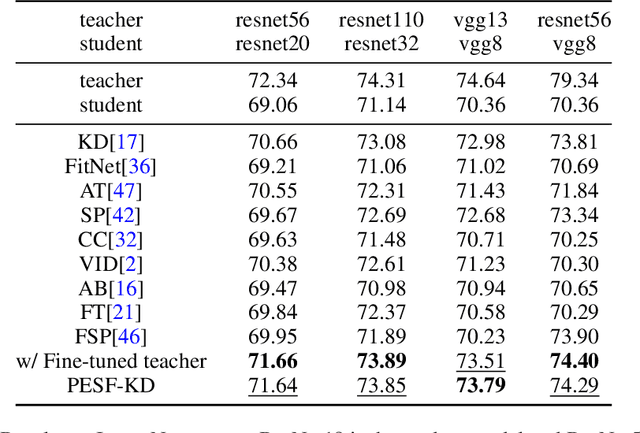
Knowledge distillation (KD) has been extensively employed to transfer the knowledge from a large teacher model to the smaller students, where the parameters of the teacher are fixed (or partially) during training. Recent studies show that this mode may cause difficulties in knowledge transfer due to the mismatched model capacities. To alleviate the mismatch problem, teacher-student joint training methods, e.g., online distillation, have been proposed, but it always requires expensive computational cost. In this paper, we present a parameter-efficient and student-friendly knowledge distillation method, namely PESF-KD, to achieve efficient and sufficient knowledge transfer by updating relatively few partial parameters. Technically, we first mathematically formulate the mismatch as the sharpness gap between their predictive distributions, where we show such a gap can be narrowed with the appropriate smoothness of the soft label. Then, we introduce an adapter module for the teacher and only update the adapter to obtain soft labels with appropriate smoothness. Experiments on a variety of benchmarks show that PESF-KD can significantly reduce the training cost while obtaining competitive results compared to advanced online distillation methods. Code will be released upon acceptance.