 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Aware Federated Active Learning with Non-IID Data
Nov 24, 2022



Federated learning enables multiple decentralized clients to learn collaboratively without sharing the local training data. However, the expensive annotation cost to acquire data labels on local clients remains an obstacle in utilizing local data. In this paper, we propose a federated active learning paradigm to efficiently learn a global model with limited annotation budget while protecting data privacy in a decentralized learning way. The main challenge faced by federated active learning is the mismatch between the active sampling goal of the global model on the server and that of the asynchronous local clients. This becomes even more significant when data is distributed non-IID across local clients. To address the aforementioned challenge, we propose Knowledge-Aware Federated Active Learning (KAFAL), which consists of Knowledge-Specialized Active Sampling (KSAS) and Knowledge-Compensatory Federated Update (KCFU). KSAS is a novel active sampling method tailored for the federated active learning problem. It deals with the mismatch challenge by sampling actively based on the discrepancies between local and global models. KSAS intensifies specialized knowledge in local clients, ensuring the sampled data to be informative for both the local clients and the global model. KCFU, in the meantime, deals with the client heterogeneity caused by limited data and non-IID data distributions. It compensates for each client's ability in weak classes by the assistance of the global model. Extensive experiments and analyses are conducted to show the superiority of KSAS over the state-of-the-art active learning methods and the efficiency of KCFU under the federated active learning framework.
Responsible Active Learning via Human-in-the-loop Peer Study
Nov 24, 2022



Active learning has been proposed to reduce data annotation efforts by only manually labelling representative data samples for training. Meanwhile, recent active learning applications have benefited a lot from cloud computing services with not only sufficient computational resources but also crowdsourcing frameworks that include many humans in the active learning loop. However, previous active learning methods that always require passing large-scale unlabelled data to cloud may potentially raise significant data privacy issues. To mitigate such a risk, we propose a responsible active learning method, namely Peer Study Learning (PSL), to simultaneously preserve data privacy and improve model stability. Specifically, we first introduce a human-in-the-loop teacher-student architecture to isolate unlabelled data from the task learner (teacher) on the cloud-side by maintaining an active learner (student) on the client-side. During training, the task learner instructs the light-weight active learner which then provides feedback on the active sampling criterion. To further enhance the active learner via large-scale unlabelled data, we introduce multiple peer students into the active learner which is trained by a novel learning paradigm, including the In-Class Peer Study on labelled data and the Out-of-Class Peer Study on unlabelled data. Lastly, we devise a discrepancy-based active sampling criterion, Peer Study Feedback, that exploits the variability of peer students to select the most informative data to improve model stability. Extensive experiments demonstrate the superiority of the proposed PSL over a wide range of active learning methods in both standard and sensitive protection settings.
Symbiotic Adversarial Learning for Attribute-based Person Search
Aug 24, 2020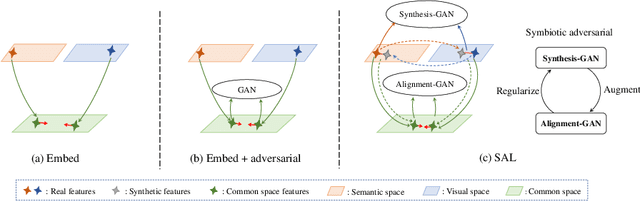
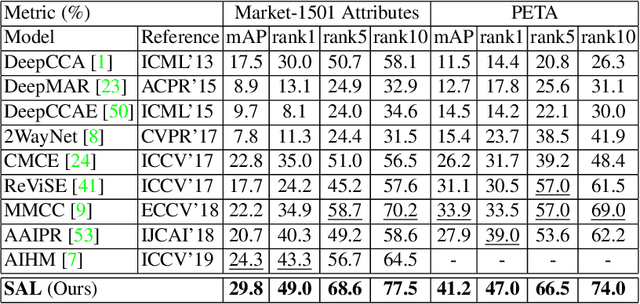
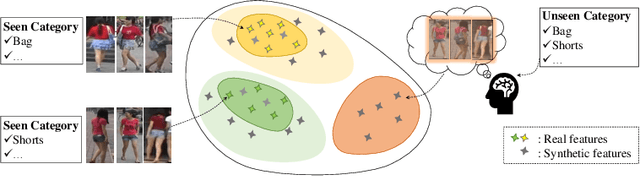
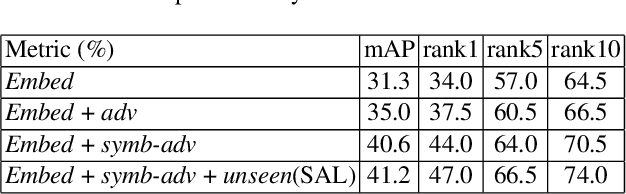
Attribute-based person search is in significant demand for applications where no detected query images are available, such as identifying a criminal from witness. However, the task itself is quite challenging because there is a huge modality gap between images and physical descriptions of attributes. Often, there may also be a large number of unseen categories (attribute combinations). The current state-of-the-art methods either focus on learning better cross-modal embeddings by mining only seen data, or they explicitly use generative adversarial networks (GANs) to synthesize unseen features. The former tends to produce poor embeddings due to insufficient data, while the latter does not preserve intra-class compactness during generation. In this paper, we present a symbiotic adversarial learning framework, called SAL.Two GANs sit at the base of the framework in a symbiotic learning scheme: one synthesizes features of unseen classes/categories, while the other optimizes the embedding and performs the cross-modal alignment on the common embedding space .Specifically, two different types of generative adversarial networks learn collaboratively throughout the training process and the interactions between the two mutually benefit each other. Extensive evaluations show SAL's superiority over nine state-of-the-art methods with two challenging pedestrian benchmarks, PETA and Market-1501. The code is publicly available at: https://github.com/ycao5602/SAL .