 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Monocular Depth Estimation for 3D Object Detection
Sep 17, 2019
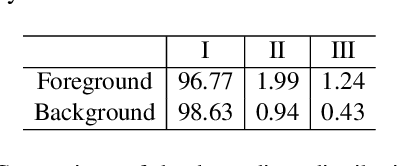
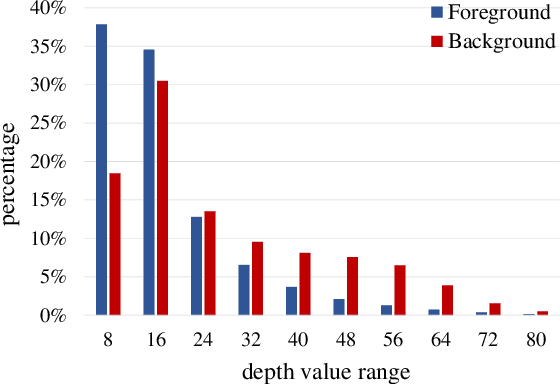
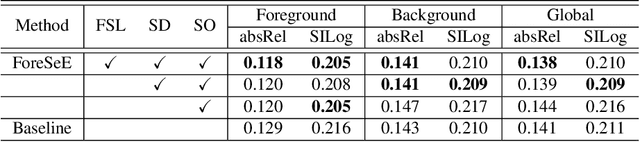
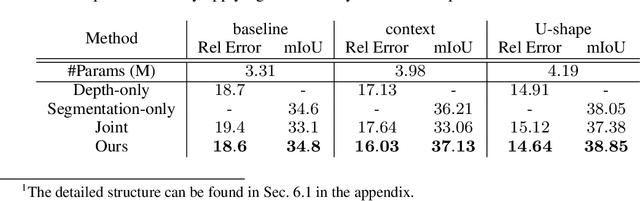
Monocular depth estimation enables 3D perception from a single 2D image, thus attracting much research attention for years. Almost all methods treat foreground and background regions (``things and stuff'') in an image equally. However, not all pixels are equal. Depth of foreground objects plays a crucial role in 3D object recognition and localization. To date how to boost the depth prediction accuracy of foreground objects is rarely discussed. In this paper, we first analyse the data distributions and interaction of foreground and background, then propose the foreground-background separated monocular depth estimation (ForeSeE) method, to estimate the foreground depth and background depth using separate optimization objectives and depth decoders. Our method significantly improves the depth estimation performance on foreground objects. Applying ForeSeE to 3D object detection, we achieve 7.5 AP gains and set new state-of-the-art results among other monocular methods.
Training Compact Neural Networks via Auxiliary Overparameterization
Sep 05, 2019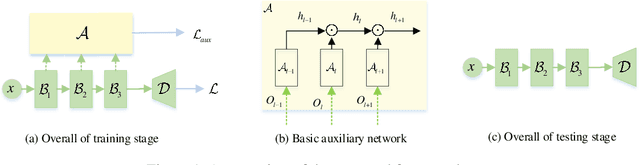
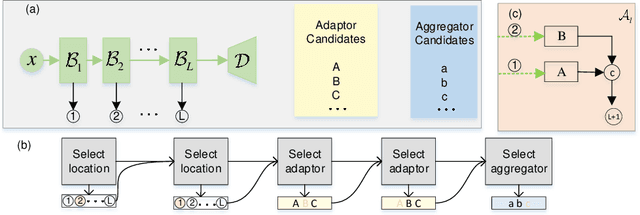
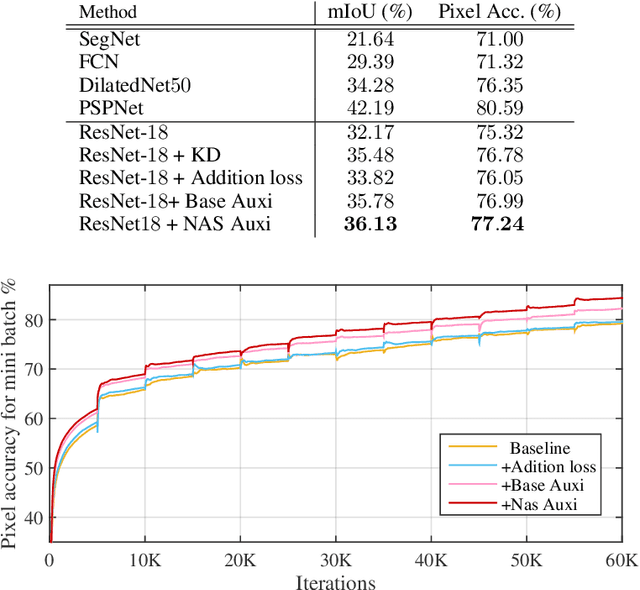
It is observed that overparameterization (i.e., designing neural networks whose number of parameters is larger than statistically needed to fit the training data) can improve both optimization and generalization while compact networks are more difficult to be optimized. However, overparameterization leads to slower test-time inference speed and more power consumption. To tackle this problem, we propose a novel auxiliary module to simulate the effect of overparameterization. During training, we expand the compact network with the auxiliary module to formulate a wider network to assist optimization while during inference only the original compact network is kept. Moreover, we propose to automatically search the hierarchical auxiliary structure to avoid adding supervisions heuristically. In experiments, we explore several challenging resource constraint tasks including light-weight classification, semantic segmentation and multi-task learning with hard parameter sharing. We empirically find that the proposed auxiliary module can maintain the complexity of the compact network while significantly improving the performance.
Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
Aug 16, 2019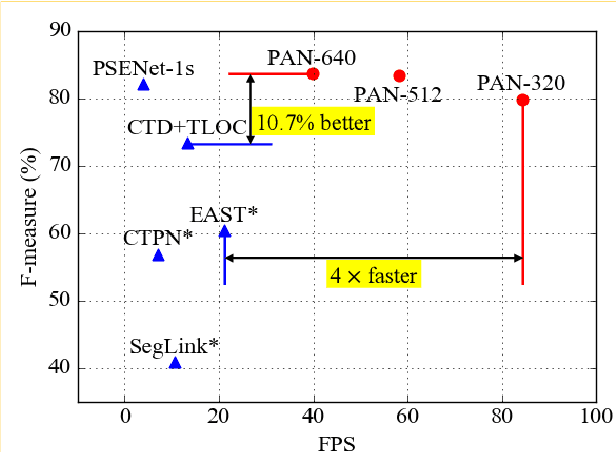
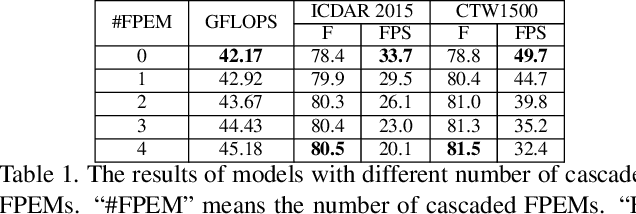


Scene text detection, an important step of scene text reading systems, has witnessed rapid development with convolutional neural networks. Nonetheless, two main challenges still exist and hamper its deployment to real-world applications. The first problem is the trade-off between speed and accuracy. The second one is to model the arbitrary-shaped text instance. Recently, some methods have been proposed to tackle arbitrary-shaped text detection, but they rarely take the speed of the entire pipeline into consideration, which may fall short in practical applications.In this paper, we propose an efficient and accurate arbitrary-shaped text detector, termed Pixel Aggregation Network (PAN), which is equipped with a low computational-cost segmentation head and a learnable post-processing. More specifically, the segmentation head is made up of Feature Pyramid Enhancement Module (FPEM) and Feature Fusion Module (FFM). FPEM is a cascadable U-shaped module, which can introduce multi-level information to guide the better segmentation. FFM can gather the features given by the FPEMs of different depths into a final feature for segmentation. The learnable post-processing is implemented by Pixel Aggregation (PA), which can precisely aggregate text pixels by predicted similarity vectors. Experiments on several standard benchmarks validate the superiority of the proposed PAN. It is worth noting that our method can achieve a competitive F-measure of 79.9% at 84.2 FPS on CTW1500.
From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer
Aug 15, 2019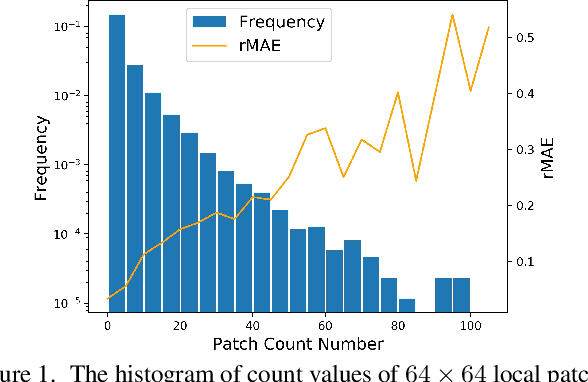

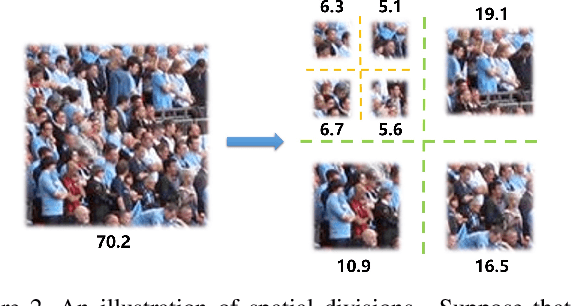

Visual counting, a task that predicts the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in $[0,+\infty)$ in theory. However, the collected images and labeled count values are limited in reality, which means only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are likely to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting is decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. Inspired by this idea, we propose a simple but effective approach, Spatial Divide-and- Conquer Network (S-DCNet). S-DCNet only learns from a closed set but can generalize well to open-set scenarios via S-DC. S-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. S-DCNet achieves the state-of-the-art performance on three crowd counting datasets (ShanghaiTech, UCF_CC_50 and UCF-QNRF), a vehicle counting dataset (TRANCOS) and a plant counting dataset (MTC). Compared to the previous best methods, S-DCNet brings a 20.2% relative improvement on the ShanghaiTech Part B, 20.9% on the UCF-QNRF, 22.5% on the TRANCOS and 15.1% on the MTC. Code has been made available at: https://github. com/xhp-hust-2018-2011/S-DCNet.
Index Network
Aug 11, 2019
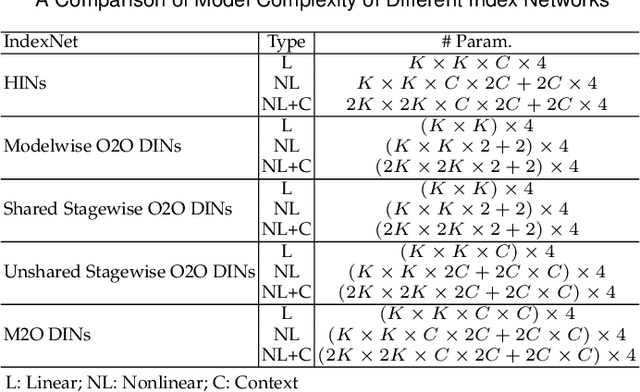
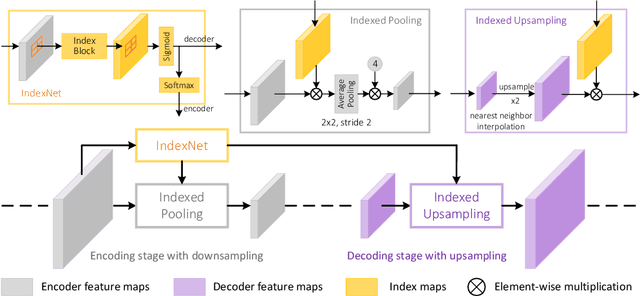
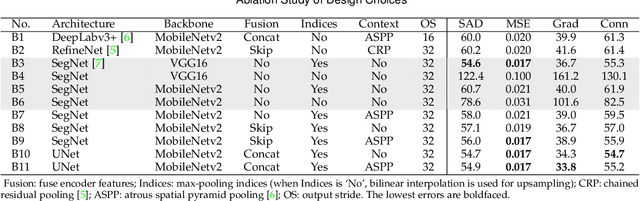
We show that existing upsampling operators can be unified using the notion of the index function. This notion is inspired by an observation in the decoding process of deep image matting where indices-guided unpooling can often recover boundary details considerably better than other upsampling operators such as bilinear interpolation. By viewing the indices as a function of the feature map, we introduce the concept of "learning to index", and present a novel index-guided encoder-decoder framework where indices are self-learned adaptively from data and are used to guide the downsampling and upsampling stages, without extra training supervision. At the core of this framework is a new learnable module, termed Index Network (IndexNet), which dynamically generates indices conditioned on the feature map itself. IndexNet can be used as a plug-in applying to almost all off-the-shelf convolutional networks that have coupled downsampling and upsampling stages, giving the networks the ability to dynamically capture variations of local patterns. In particular, we instantiate and investigate five families of IndexNet and demonstrate their effectiveness on four dense prediction tasks, including image denoising, image matting, semantic segmentation, and monocular depth estimation. Code and models have been made available at: https://tinyurl.com/IndexNetV1
MobileFAN: Transferring Deep Hidden Representation for Face Alignment
Aug 11, 2019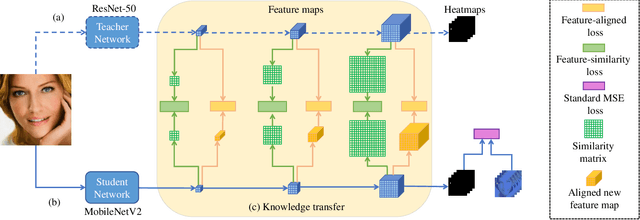

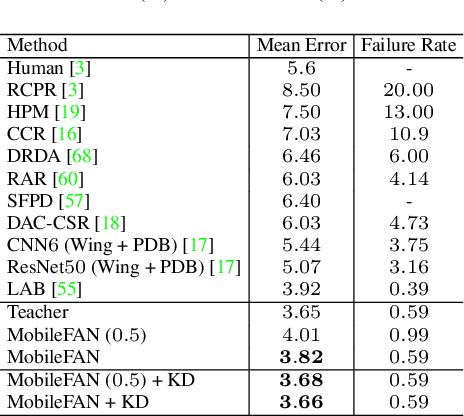
Facial landmark detection is a crucial prerequisite for many face analysis applications. Deep learning-based methods currently dominate the approach of addressing the facial landmark detection. However, such works generally introduce a large number of parameters, resulting in high memory cost. In this paper, we aim for lightweight as well as effective solutions to facial landmark detection. To this end, we propose an effective lightweight model, namely Mobile Face Alignment Network (MobileFAN), using a simple backbone MobileNetV2 as the encoder and three deconvolutional layers as the decoder. The proposed MobileFAN, with only 8% of the model size and lower computational cost, achieves superior or equivalent performance compared to state-of-the-art models. Moreover, by transferring the geometric structural information of a face graph from a large complex model to our proposed MobileFAN through feature-aligned distillation and feature-similarity distillation, the performance of MobileFAN is further improved in effectiveness and efficiency for face alignment. Extensive experiment results on three challenging facial landmark estimation benchmarks including COFW, 300W and WFLW show the superiority of our proposed MobileFAN against state-of-the-art methods.
Effective Training of Convolutional Neural Networks with Low-bitwidth Weights and Activations
Aug 10, 2019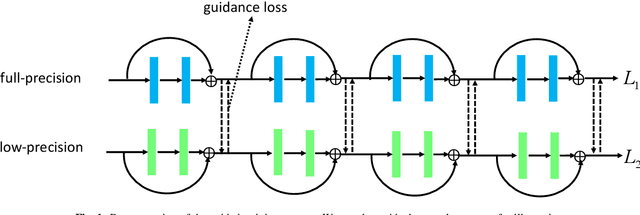
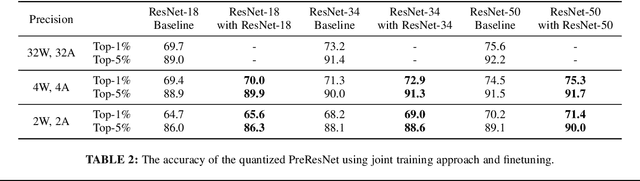
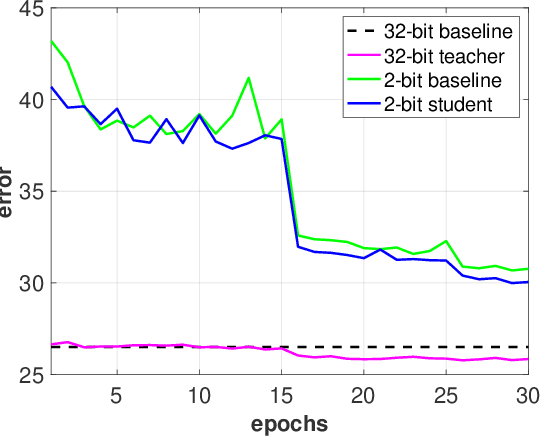
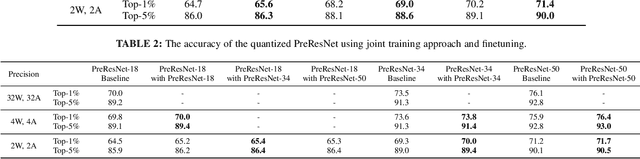
This paper tackles the problem of training a deep convolutional neural network of both low-bitwidth weights and activations. Optimizing a low-precision network is very challenging due to the non-differentiability of the quantizer, which may result in substantial accuracy loss. To address this, we propose three practical approaches, including (i) progressive quantization; (ii) stochastic precision; and (iii) joint knowledge distillation to improve the network training. First, for progressive quantization, we propose two schemes to progressively find good local minima. Specifically, we propose to first optimize a net with quantized weights and subsequently quantize activations. This is in contrast to the traditional methods which optimize them simultaneously. Furthermore, we propose a second progressive quantization scheme which gradually decreases the bit-width from high-precision to low-precision during training. Second, to alleviate the excessive training burden due to the multi-round training stages, we further propose a one-stage stochastic precision strategy to randomly sample and quantize sub-networks while keeping other parts in full-precision. Finally, we adopt a novel learning scheme to jointly train a full-precision model alongside the low-precision one. By doing so, the full-precision model provides hints to guide the low-precision model training and significantly improves the performance of the low-precision network. Extensive experiments on various datasets (e.g., CIFAR-100, ImageNet) show the effectiveness of the proposed methods.
Exploiting temporal consistency for real-time video depth estimation
Aug 10, 2019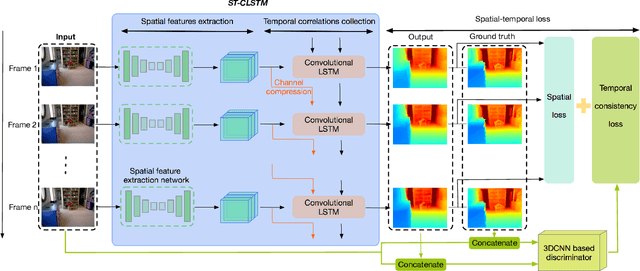
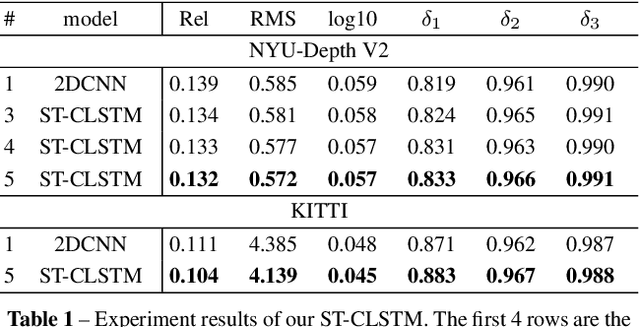
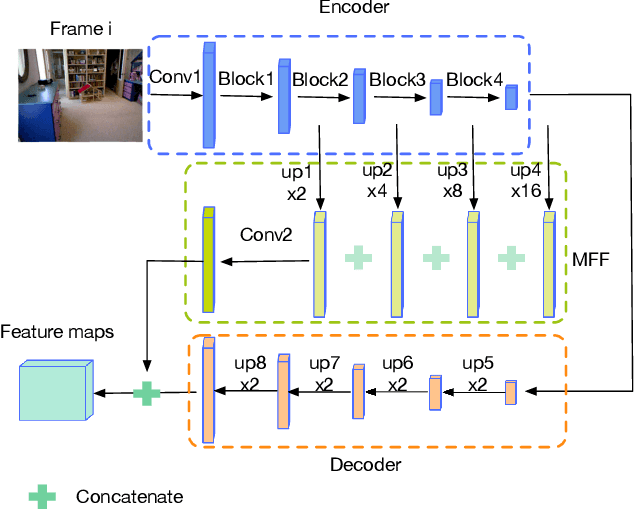
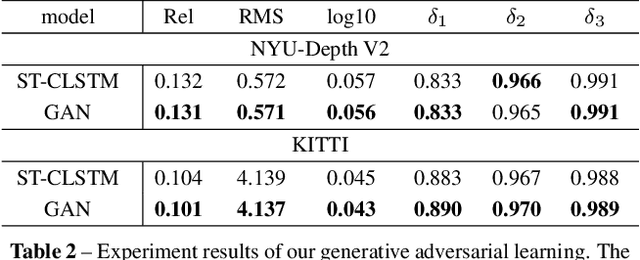
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM
Indices Matter: Learning to Index for Deep Image Matting
Aug 02, 2019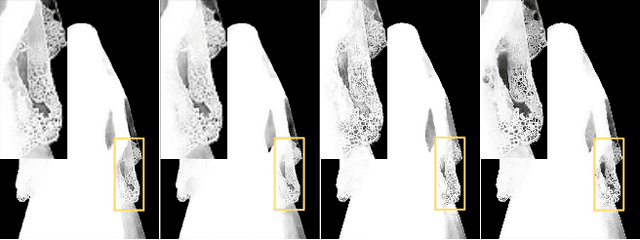
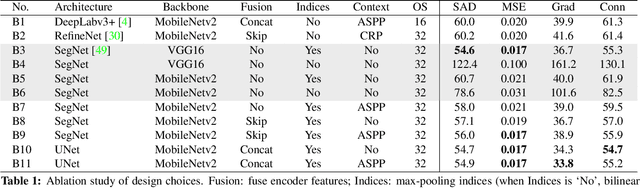
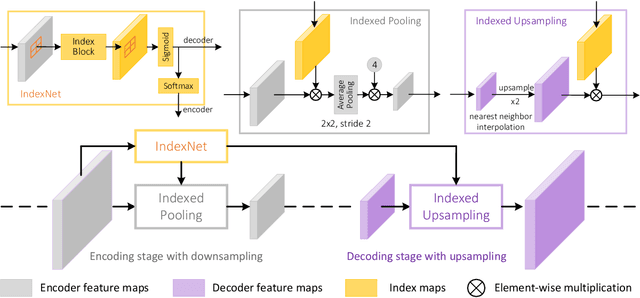
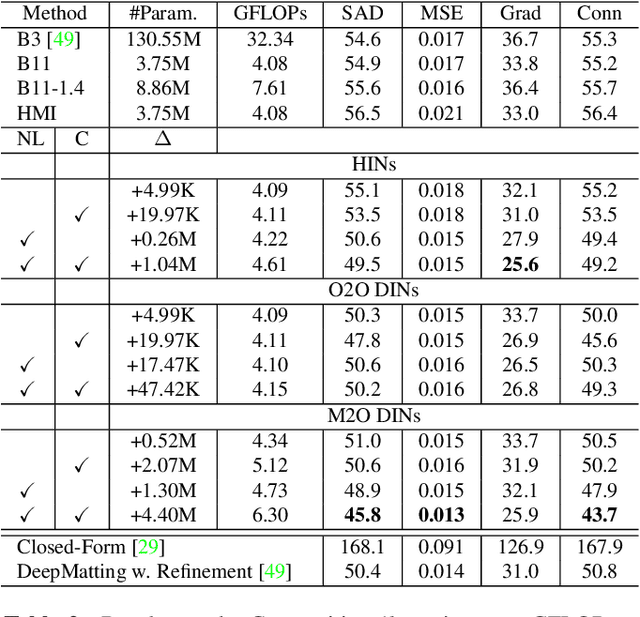
We show that existing upsampling operators can be unified with the notion of the index function. This notion is inspired by an observation in the decoding process of deep image matting where indices-guided unpooling can recover boundary details much better than other upsampling operators such as bilinear interpolation. By looking at the indices as a function of the feature map, we introduce the concept of learning to index, and present a novel index-guided encoder-decoder framework where indices are self-learned adaptively from data and are used to guide the pooling and upsampling operators, without the need of supervision. At the core of this framework is a flexible network module, termed IndexNet, which dynamically predicts indices given an input. Due to its flexibility, IndexNet can be used as a plug-in applying to any off-the-shelf convolutional networks that have coupled downsampling and upsampling stages. We demonstrate the effectiveness of IndexNet on the task of natural image matting where the quality of learned indices can be visually observed from predicted alpha mattes. Results on the Composition-1k matting dataset show that our model built on MobileNetv2 exhibits at least $16.1\%$ improvement over the seminal VGG-16 based deep matting baseline, with less training data and lower model capacity. Code and models has been made available at: https://tinyurl.com/IndexNetV1
Enforcing geometric constraints of virtual normal for depth prediction
Aug 01, 2019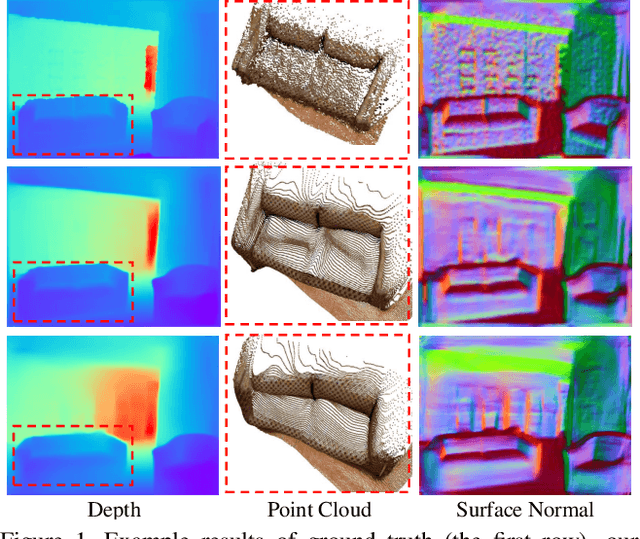
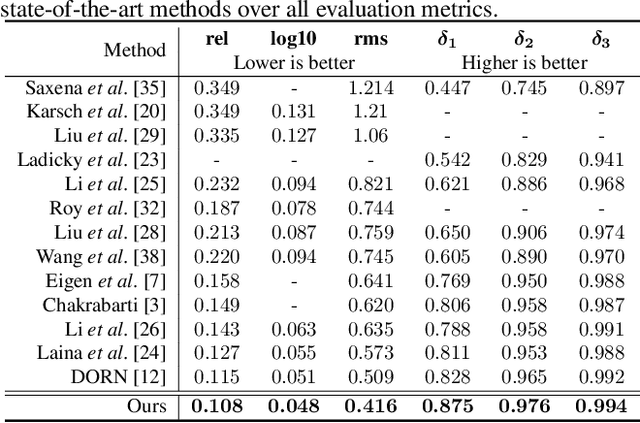
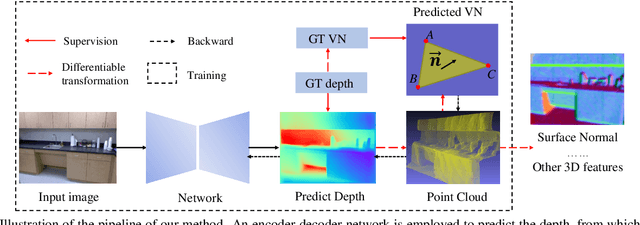
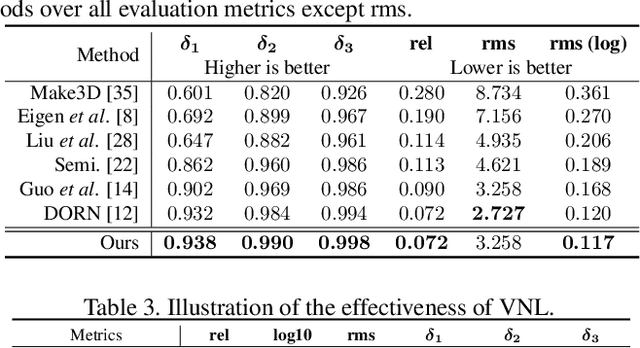
Monocular depth prediction plays a crucial role in understanding 3D scene geometry. Although recent methods have achieved impressive progress in evaluation metrics such as the pixel-wise relative error, most methods neglect the geometric constraints in the 3D space. In this work, we show the importance of the high-order 3D geometric constraints for depth prediction. By designing a loss term that enforces one simple type of geometric constraints, namely, virtual normal directions determined by randomly sampled three points in the reconstructed 3D space, we can considerably improve the depth prediction accuracy. Significantly, the byproduct of this predicted depth being sufficiently accurate is that we are now able to recover good 3D structures of the scene such as the point cloud and surface normal directly from the depth, eliminating the necessity of training new sub-models as was previously done. Experiments on two benchmarks: NYU Depth-V2 and KITTI demonstrate the effectiveness of our method and state-of-the-art performance.