 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Objective Curricula for Deep Reinforcement Learning
Oct 06, 2021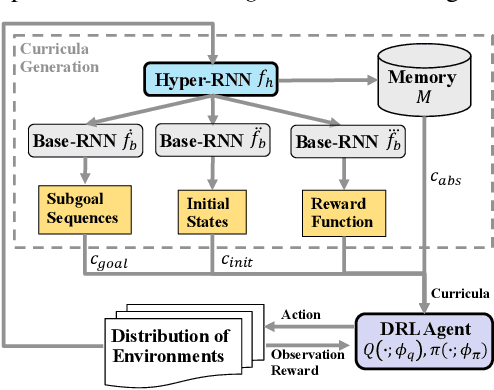

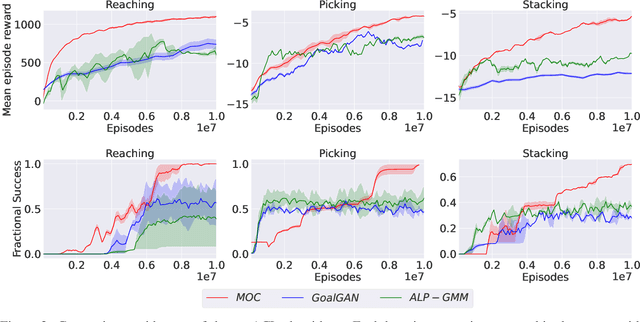
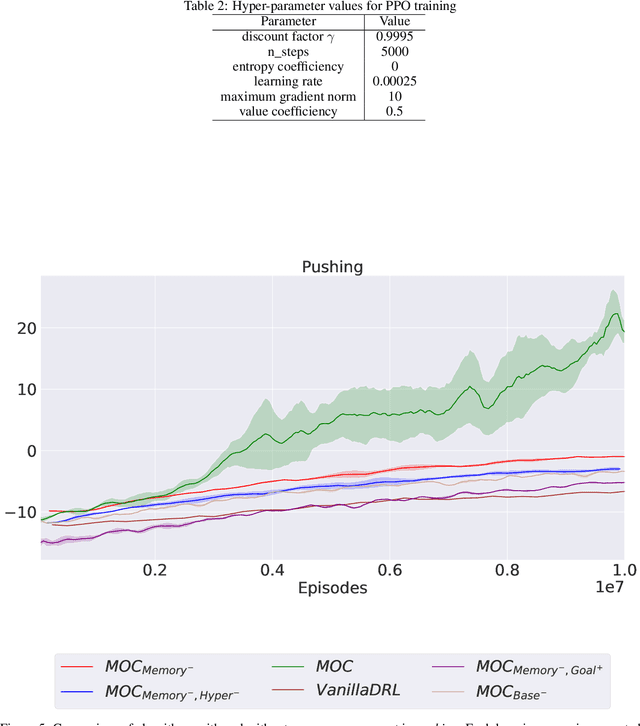
Various automatic curriculum learning (ACL) methods have been proposed to improve the sample efficiency and final performance of deep reinforcement learning (DRL). They are designed to control how a DRL agent collects data, which is inspired by how humans gradually adapt their learning processes to their capabilities. For example, ACL can be used for subgoal generation, reward shaping, environment generation, or initial state generation. However, prior work only considers curriculum learning following one of the aforementioned predefined paradigms. It is unclear which of these paradigms are complementary, and how the combination of them can be learned from interactions with the environment. Therefore, in this paper, we propose a unified automatic curriculum learning framework to create multi-objective but coherent curricula that are generated by a set of parametric curriculum modules. Each curriculum module is instantiated as a neural network and is responsible for generating a particular curriculum. In order to coordinate those potentially conflicting modules in unified parameter space, we propose a multi-task hyper-net learning framework that uses a single hyper-net to parameterize all those curriculum modules. In addition to existing hand-designed curricula paradigms, we further design a flexible memory mechanism to learn an abstract curriculum, which may otherwise be difficult to design manually. We evaluate our method on a series of robotic manipulation tasks and demonstrate its superiority over other state-of-the-art ACL methods in terms of sample efficiency and final performance.
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021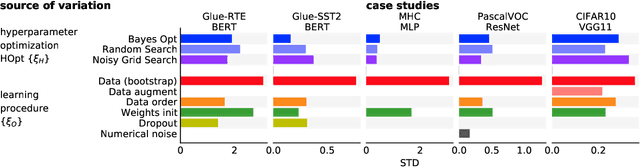
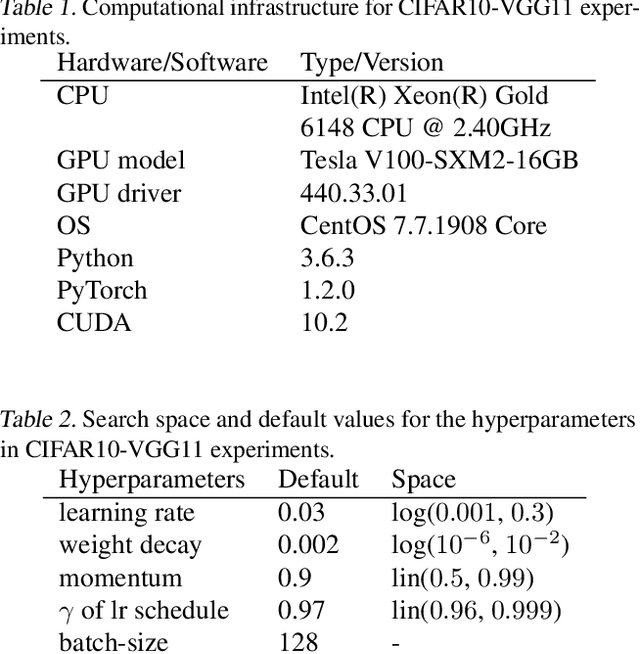
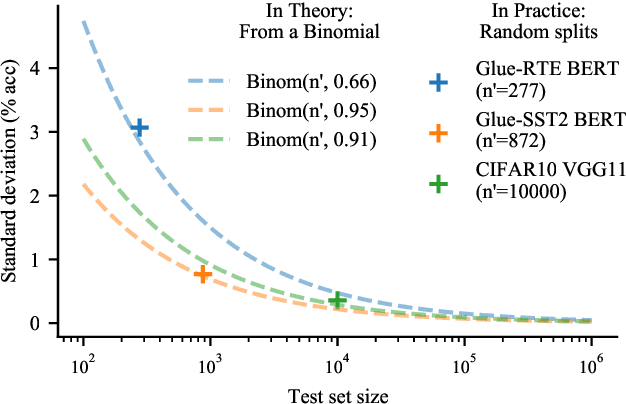
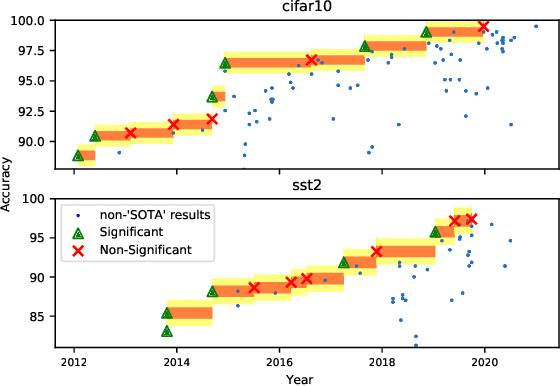
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.
Predicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020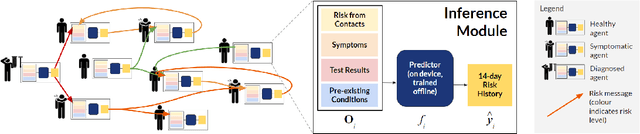
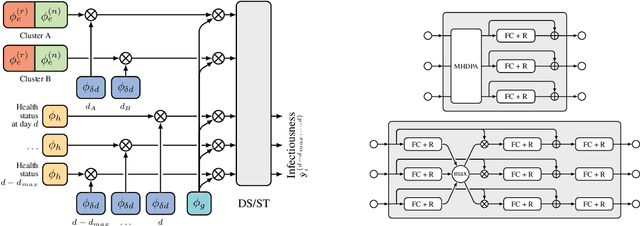
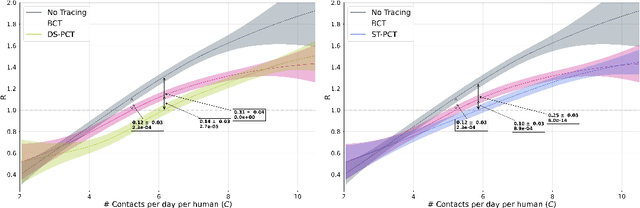
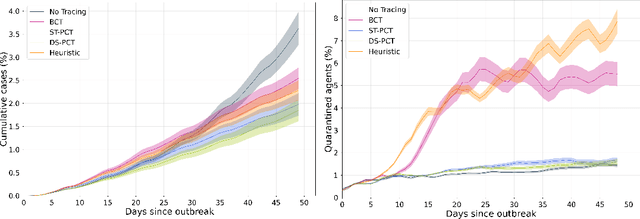
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
DuoRAT: Towards Simpler Text-to-SQL Models
Oct 21, 2020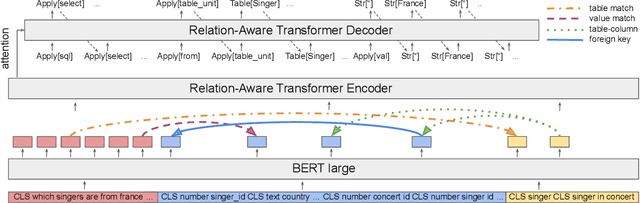
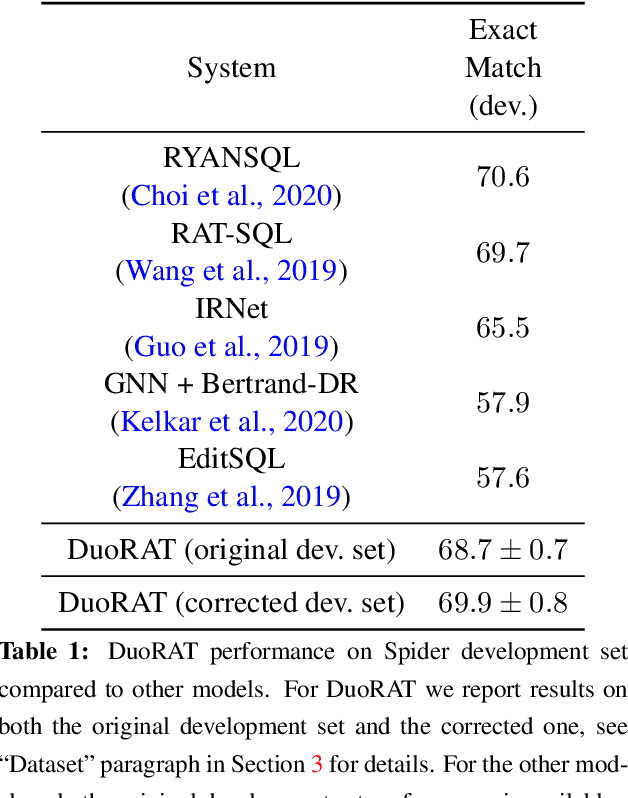
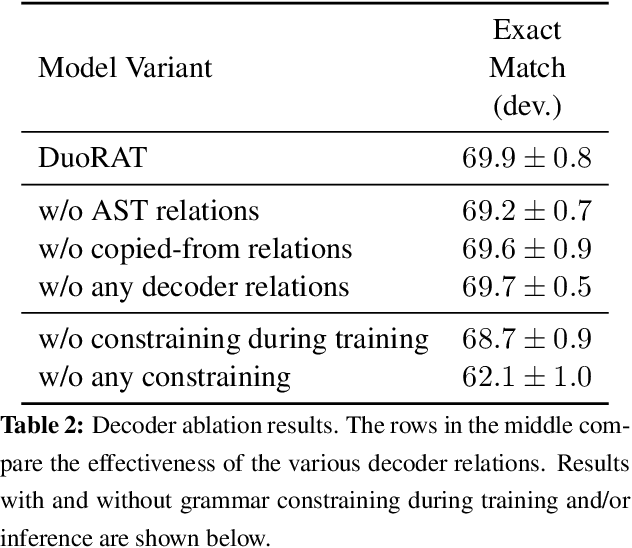
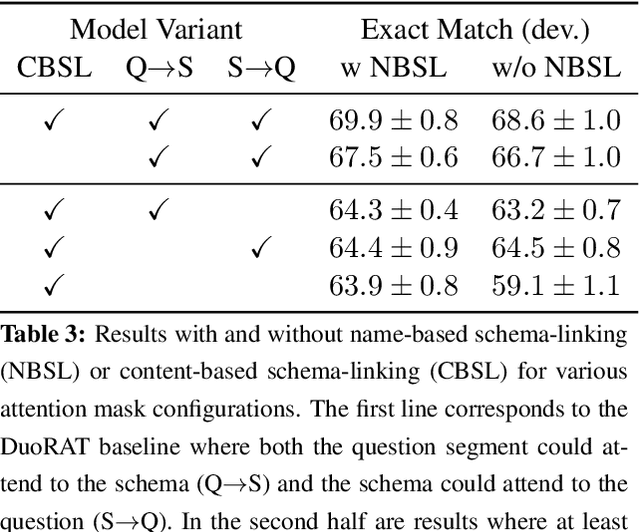
Recent research has shown that neural text-to-SQL models can effectively translate natural language questions into corresponding SQL queries on unseen databases. Working mostly on the Spider dataset, researchers have been proposing increasingly sophisticated modelling approaches to the problem. Contrary to this trend, in this paper we identify the aspects in which text-to-SQL models can be simplified. We begin by building DuoRAT, a re-implementation of the state-of-the-art RAT-SQL model that unlike RAT-SQL is using only relation-aware or vanilla transformers as the building blocks. We perform several ablation experiments using DuoRAT as the baseline model. Our experiments confirm the usefulness of some of the techniques and point out the redundancy of others, including structural SQL features and features that link the question with the schema.
Medical Imaging with Deep Learning: MIDL 2020 -- Short Paper Track
Jun 29, 2020This compendium gathers all the accepted extended abstracts from the Third International Conference on Medical Imaging with Deep Learning (MIDL 2020), held in Montreal, Canada, 6-9 July 2020. Note that only accepted extended abstracts are listed here, the Proceedings of the MIDL 2020 Full Paper Track are published in the Proceedings of Machine Learning Research (PMLR).
Role-Wise Data Augmentation for Knowledge Distillation
Apr 19, 2020
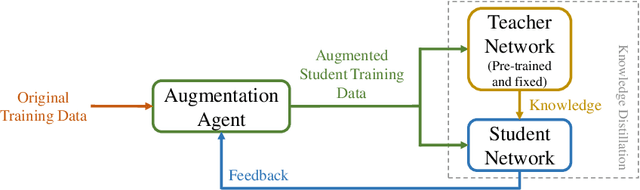
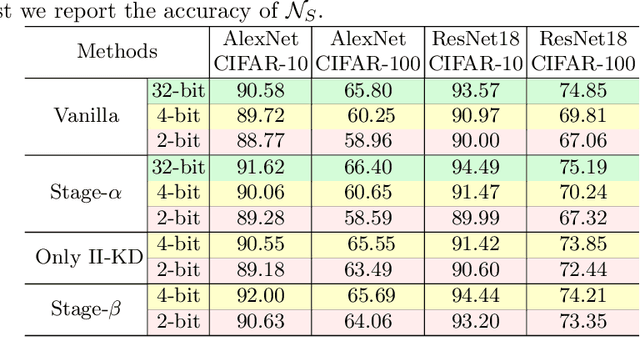

Knowledge Distillation (KD) is a common method for transferring the ``knowledge'' learned by one machine learning model (the \textit{teacher}) into another model (the \textit{student}), where typically, the teacher has a greater capacity (e.g., more parameters or higher bit-widths). To our knowledge, existing methods overlook the fact that although the student absorbs extra knowledge from the teacher, both models share the same input data -- and this data is the only medium by which the teacher's knowledge can be demonstrated. Due to the difference in model capacities, the student may not benefit fully from the same data points on which the teacher is trained. On the other hand, a human teacher may demonstrate a piece of knowledge with individualized examples adapted to a particular student, for instance, in terms of her cultural background and interests. Inspired by this behavior, we design data augmentation agents with distinct roles to facilitate knowledge distillation. Our data augmentation agents generate distinct training data for the teacher and student, respectively. We find empirically that specially tailored data points enable the teacher's knowledge to be demonstrated more effectively to the student. We compare our approach with existing KD methods on training popular neural architectures and demonstrate that role-wise data augmentation improves the effectiveness of KD over strong prior approaches. The code for reproducing our results can be found at https://github.com/bigaidream-projects/role-kd
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


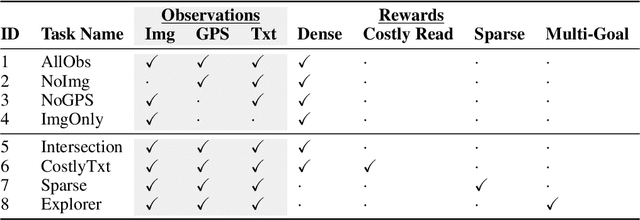
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.
Learning Neural Causal Models from Unknown Interventions
Oct 02, 2019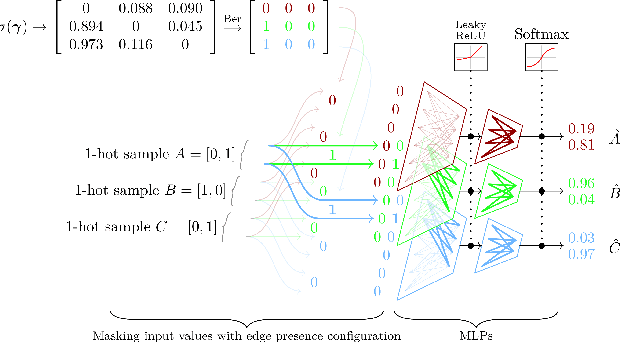



Meta-learning over a set of distributions can be interpreted as learning different types of parameters corresponding to short-term vs long-term aspects of the mechanisms underlying the generation of data. These are respectively captured by quickly-changing parameters and slowly-changing meta-parameters. We present a new framework for meta-learning causal models where the relationship between each variable and its parents is modeled by a neural network, modulated by structural meta-parameters which capture the overall topology of a directed graphical model. Our approach avoids a discrete search over models in favour of a continuous optimization procedure. We study a setting where interventional distributions are induced as a result of a random intervention on a single unknown variable of an unknown ground truth causal model, and the observations arising after such an intervention constitute one meta-example. To disentangle the slow-changing aspects of each conditional from the fast-changing adaptations to each intervention, we parametrize the neural network into fast parameters and slow meta-parameters. We introduce a meta-learning objective that favours solutions robust to frequent but sparse interventional distribution change, and which generalize well to previously unseen interventions. Optimizing this objective is shown experimentally to recover the structure of the causal graph.
An Empirical Study of Batch Normalization and Group Normalization in Conditional Computation
Jul 31, 2019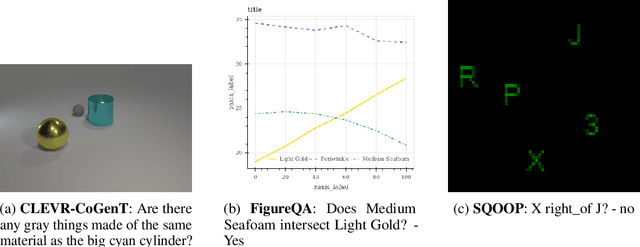


Batch normalization has been widely used to improve optimization in deep neural networks. While the uncertainty in batch statistics can act as a regularizer, using these dataset statistics specific to the training set impairs generalization in certain tasks. Recently, alternative methods for normalizing feature activations in neural networks have been proposed. Among them, group normalization has been shown to yield similar, in some domains even superior performance to batch normalization. All these methods utilize a learned affine transformation after the normalization operation to increase representational power. Methods used in conditional computation define the parameters of these transformations as learnable functions of conditioning information. In this work, we study whether and where the conditional formulation of group normalization can improve generalization compared to conditional batch normalization. We evaluate performances on the tasks of visual question answering, few-shot learning, and conditional image generation.
Revision in Continuous Space: Fine-Grained Control of Text Style Transfer
Jun 02, 2019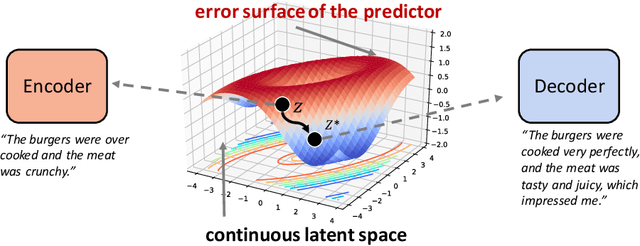
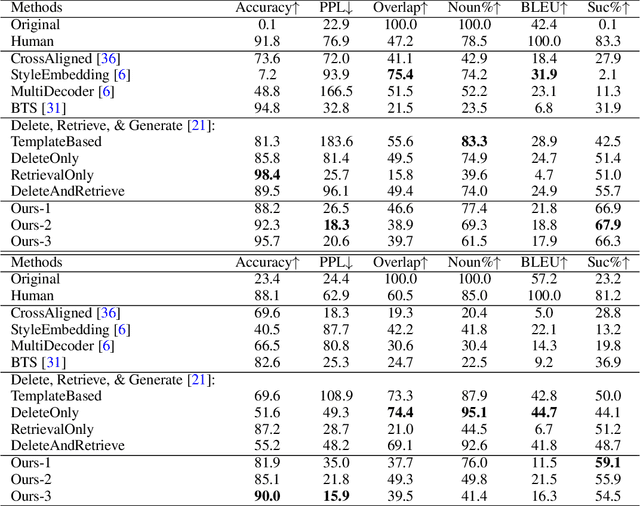
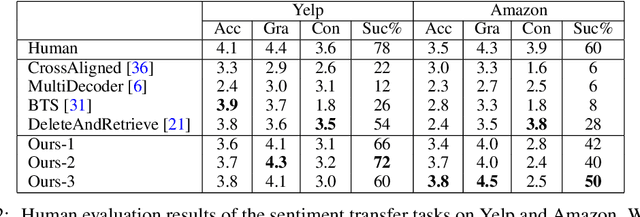
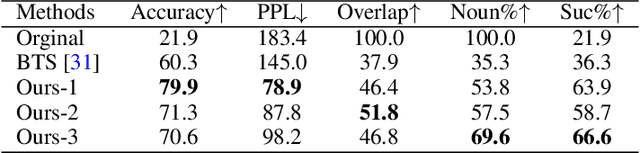
Typical methods for unsupervised text style transfer often rely on two key ingredients: 1) seeking for the disentanglement of the content and the attributes, and 2) troublesome adversarial learning. In this paper, we show that neither of these components is indispensable. We propose a new framework without them and instead consists of three key components: a variational auto-encoder (VAE), some attribute predictors (one for each attribute), and a content predictor. The VAE and the two types of predictors enable us to perform gradient-based optimization in the continuous space, which is mapped from sentences in a discrete space, to find the representation of a target sentence with the desired attributes and preserved content. Moreover, the proposed method can, for the first time, simultaneously manipulate multiple fine-grained attributes, such as sentence length and the presence of specific words, in synergy when performing text style transfer tasks. Extensive experimental studies on three popular text style transfer tasks show that the proposed method significantly outperforms five state-of-the-art methods.