 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Goal-conditioned Supervised Learning and Its Connection to Offline RL
Feb 14, 2022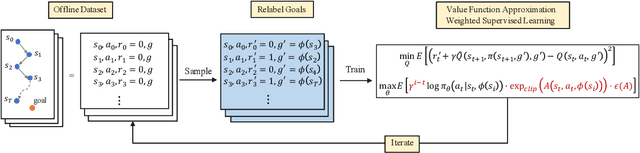
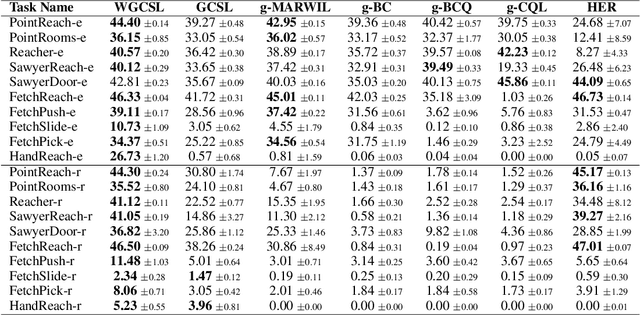
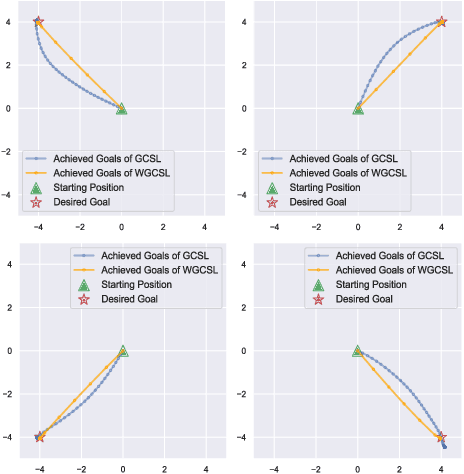
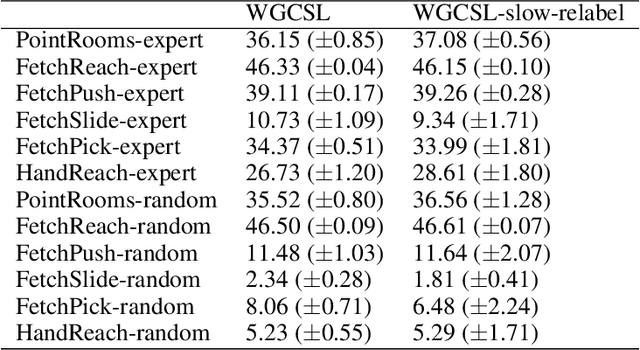
Solving goal-conditioned tasks with sparse rewards using self-supervised learning is promising because of its simplicity and stability over current reinforcement learning (RL) algorithms. A recent work, called Goal-Conditioned Supervised Learning (GCSL), provides a new learning framework by iteratively relabeling and imitating self-generated experiences. In this paper, we revisit the theoretical property of GCSL -- optimizing a lower bound of the goal reaching objective, and extend GCSL as a novel offline goal-conditioned RL algorithm. The proposed method is named Weighted GCSL (WGCSL), in which we introduce an advanced compound weight consisting of three parts (1) discounted weight for goal relabeling, (2) goal-conditioned exponential advantage weight, and (3) best-advantage weight. Theoretically, WGCSL is proved to optimize an equivalent lower bound of the goal-conditioned RL objective and generates monotonically improved policies via an iterated scheme. The monotonic property holds for any behavior policies, and therefore WGCSL can be applied to both online and offline settings. To evaluate algorithms in the offline goal-conditioned RL setting, we provide a benchmark including a range of point and simulated robot domains. Experiments in the introduced benchmark demonstrate that WGCSL can consistently outperform GCSL and existing state-of-the-art offline methods in the fully offline goal-conditioned setting.
MOORe: Model-based Offline-to-Online Reinforcement Learning
Jan 25, 2022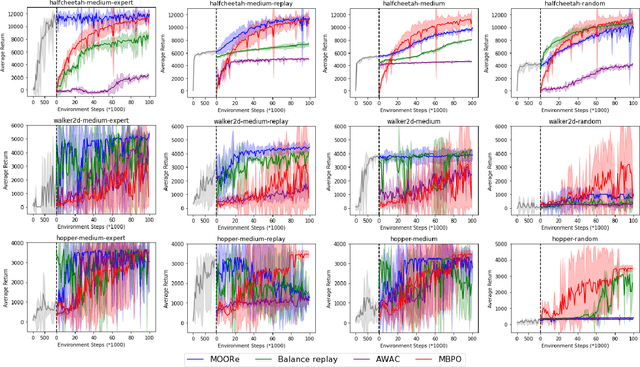
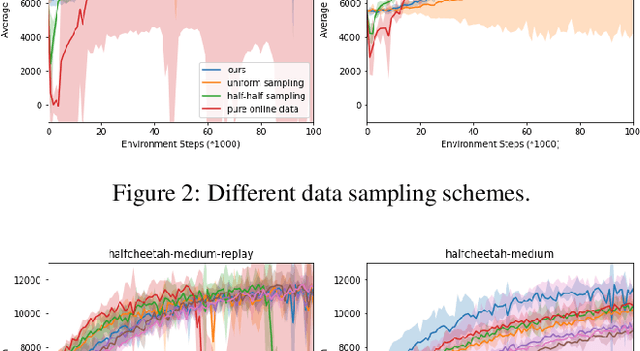
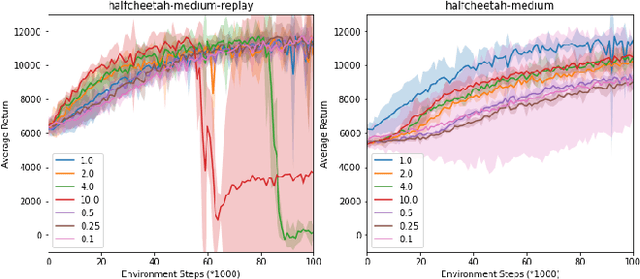
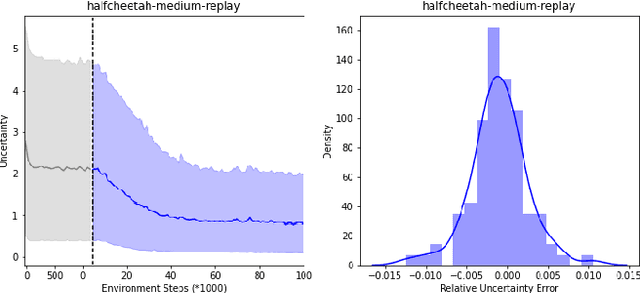
With the success of offline reinforcement learning (RL), offline trained RL policies have the potential to be further improved when deployed online. A smooth transfer of the policy matters in safe real-world deployment. Besides, fast adaptation of the policy plays a vital role in practical online performance improvement. To tackle these challenges, we propose a simple yet efficient algorithm, Model-based Offline-to-Online Reinforcement learning (MOORe), which employs a prioritized sampling scheme that can dynamically adjust the offline and online data for smooth and efficient online adaptation of the policy. We provide a theoretical foundation for our algorithms design. Experiment results on the D4RL benchmark show that our algorithm smoothly transfers from offline to online stages while enabling sample-efficient online adaption, and also significantly outperforms existing methods.
Self-Organized Polynomial-Time Coordination Graphs
Dec 07, 2021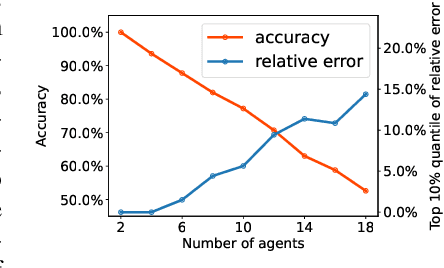
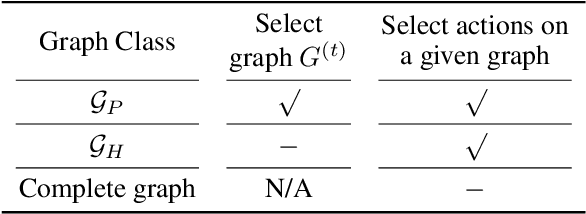
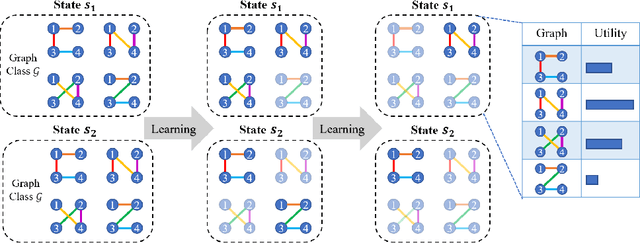

Coordination graph is a promising approach to model agent collaboration in multi-agent reinforcement learning. It factorizes a large multi-agent system into a suite of overlapping groups that represent the underlying coordination dependencies. One critical challenge in this paradigm is the complexity of computing maximum-value actions for a graph-based value factorization. It refers to the decentralized constraint optimization problem (DCOP), which and whose constant-ratio approximation are NP-hard problems. To bypass this fundamental hardness, this paper proposes a novel method, named Self-Organized Polynomial-time Coordination Graphs (SOP-CG), which uses structured graph classes to guarantee the optimality of the induced DCOPs with sufficient function expressiveness. We extend the graph topology to be state-dependent, formulate the graph selection as an imaginary agent, and finally derive an end-to-end learning paradigm from the unified Bellman optimality equation. In experiments, we show that our approach learns interpretable graph topologies, induces effective coordination, and improves performance across a variety of cooperative multi-agent tasks.
Episodic Multi-agent Reinforcement Learning with Curiosity-Driven Exploration
Nov 22, 2021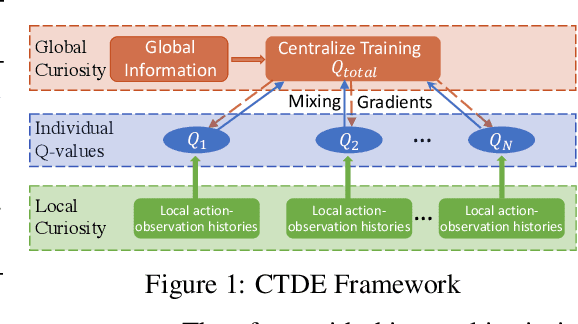
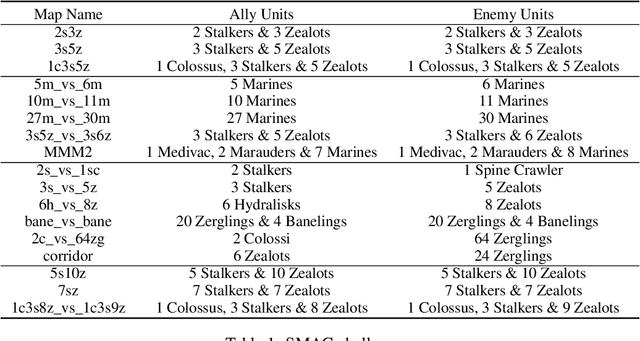
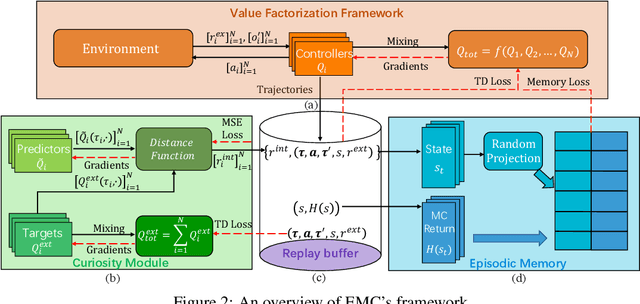

Efficient exploration in deep cooperative multi-agent reinforcement learning (MARL) still remains challenging in complex coordination problems. In this paper, we introduce a novel Episodic Multi-agent reinforcement learning with Curiosity-driven exploration, called EMC. We leverage an insight of popular factorized MARL algorithms that the "induced" individual Q-values, i.e., the individual utility functions used for local execution, are the embeddings of local action-observation histories, and can capture the interaction between agents due to reward backpropagation during centralized training. Therefore, we use prediction errors of individual Q-values as intrinsic rewards for coordinated exploration and utilize episodic memory to exploit explored informative experience to boost policy training. As the dynamics of an agent's individual Q-value function captures the novelty of states and the influence from other agents, our intrinsic reward can induce coordinated exploration to new or promising states. We illustrate the advantages of our method by didactic examples, and demonstrate its significant outperformance over state-of-the-art MARL baselines on challenging tasks in the StarCraft II micromanagement benchmark.
Offline Reinforcement Learning with Value-based Episodic Memory
Oct 19, 2021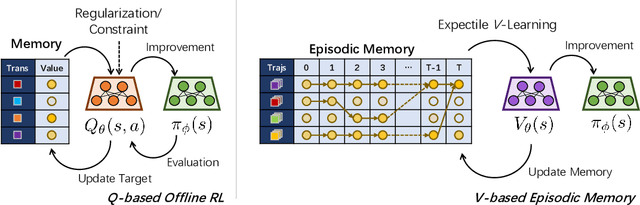
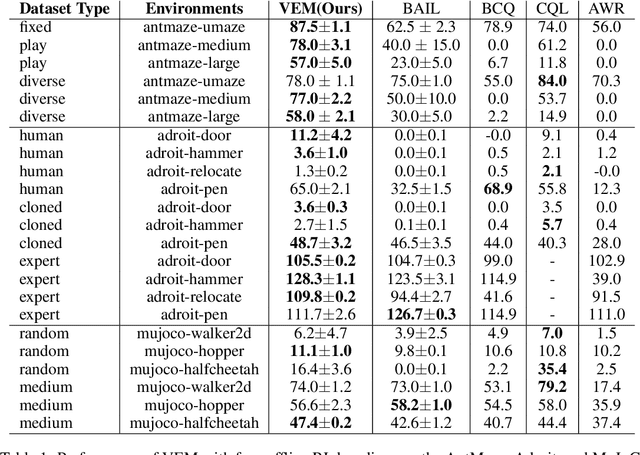
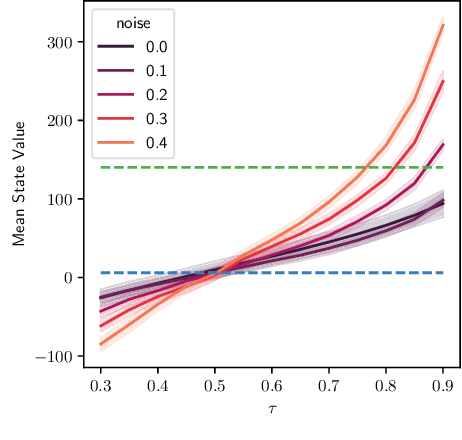
Offline reinforcement learning (RL) shows promise of applying RL to real-world problems by effectively utilizing previously collected data. Most existing offline RL algorithms use regularization or constraints to suppress extrapolation error for actions outside the dataset. In this paper, we adopt a different framework, which learns the V-function instead of the Q-function to naturally keep the learning procedure within the support of an offline dataset. To enable effective generalization while maintaining proper conservatism in offline learning, we propose Expectile V-Learning (EVL), which smoothly interpolates between the optimal value learning and behavior cloning. Further, we introduce implicit planning along offline trajectories to enhance learned V-values and accelerate convergence. Together, we present a new offline method called Value-based Episodic Memory (VEM). We provide theoretical analysis for the convergence properties of our proposed VEM method, and empirical results in the D4RL benchmark show that our method achieves superior performance in most tasks, particularly in sparse-reward tasks.
Containerized Distributed Value-Based Multi-Agent Reinforcement Learning
Oct 15, 2021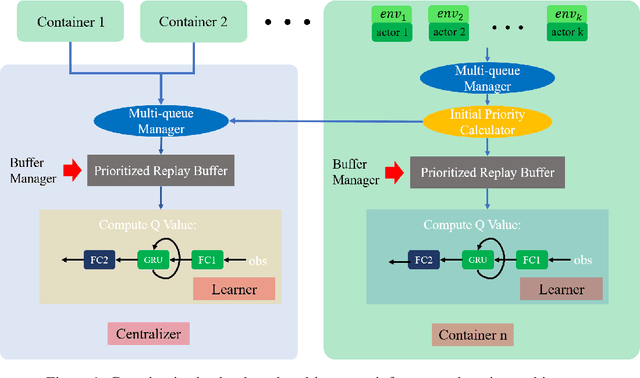
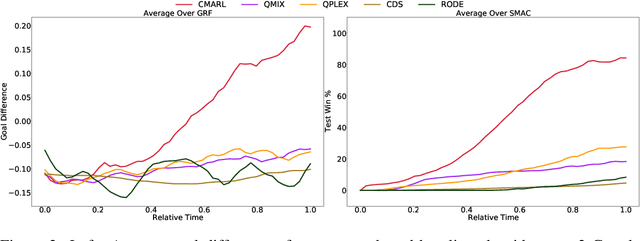
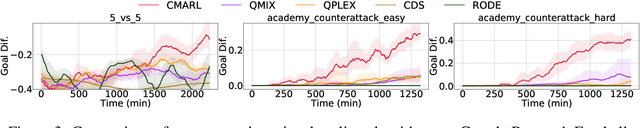
Multi-agent reinforcement learning tasks put a high demand on the volume of training samples. Different from its single-agent counterpart, distributed value-based multi-agent reinforcement learning faces the unique challenges of demanding data transfer, inter-process communication management, and high requirement of exploration. We propose a containerized learning framework to solve these problems. We pack several environment instances, a local learner and buffer, and a carefully designed multi-queue manager which avoids blocking into a container. Local policies of each container are encouraged to be as diverse as possible, and only trajectories with highest priority are sent to a global learner. In this way, we achieve a scalable, time-efficient, and diverse distributed MARL learning framework with high system throughput. To own knowledge, our method is the first to solve the challenging Google Research Football full game $5\_v\_5$. On the StarCraft II micromanagement benchmark, our method gets $4$-$18\times$ better results compared to state-of-the-art non-distributed MARL algorithms.
LINDA: Multi-Agent Local Information Decomposition for Awareness of Teammates
Oct 15, 2021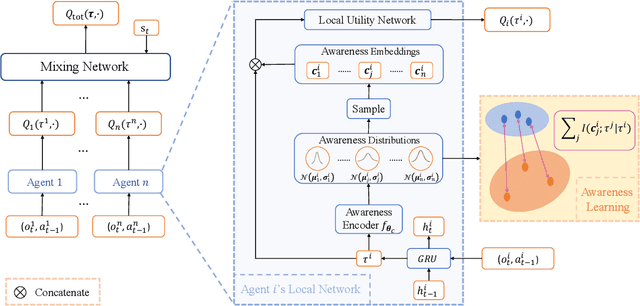

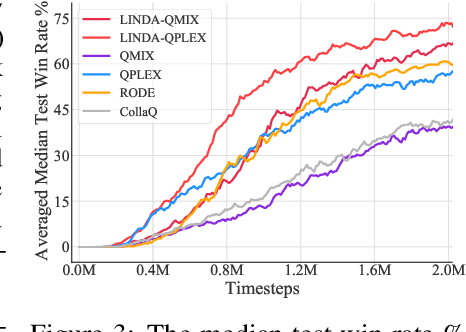
In cooperative multi-agent reinforcement learning (MARL), where agents only have access to partial observations, efficiently leveraging local information is critical. During long-time observations, agents can build \textit{awareness} for teammates to alleviate the problem of partial observability. However, previous MARL methods usually neglect this kind of utilization of local information. To address this problem, we propose a novel framework, multi-agent \textit{Local INformation Decomposition for Awareness of teammates} (LINDA), with which agents learn to decompose local information and build awareness for each teammate. We model the awareness as stochastic random variables and perform representation learning to ensure the informativeness of awareness representations by maximizing the mutual information between awareness and the actual trajectory of the corresponding agent. LINDA is agnostic to specific algorithms and can be flexibly integrated to different MARL methods. Sufficient experiments show that the proposed framework learns informative awareness from local partial observations for better collaboration and significantly improves the learning performance, especially on challenging tasks.
Offline Reinforcement Learning with Reverse Model-based Imagination
Oct 01, 2021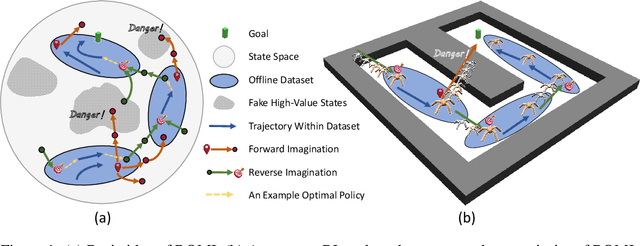
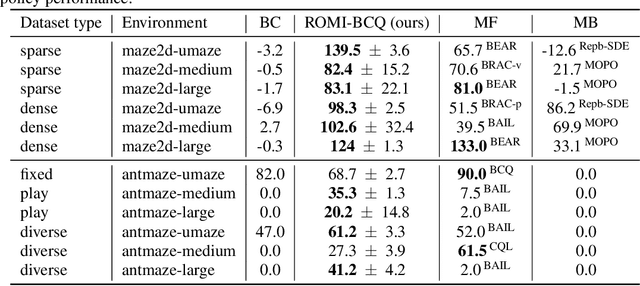

In offline reinforcement learning (offline RL), one of the main challenges is to deal with the distributional shift between the learning policy and the given dataset. To address this problem, recent offline RL methods attempt to introduce conservatism bias to encourage learning on high-confidence areas. Model-free approaches directly encode such bias into policy or value function learning using conservative regularizations or special network structures, but their constrained policy search limits the generalization beyond the offline dataset. Model-based approaches learn forward dynamics models with conservatism quantifications and then generate imaginary trajectories to extend the offline datasets. However, due to limited samples in offline dataset, conservatism quantifications often suffer from overgeneralization in out-of-support regions. The unreliable conservative measures will mislead forward model-based imaginations to undesired areas, leading to overaggressive behaviors. To encourage more conservatism, we propose a novel model-based offline RL framework, called Reverse Offline Model-based Imagination (ROMI). We learn a reverse dynamics model in conjunction with a novel reverse policy, which can generate rollouts leading to the target goal states within the offline dataset. These reverse imaginations provide informed data augmentation for the model-free policy learning and enable conservative generalization beyond the offline dataset. ROMI can effectively combine with off-the-shelf model-free algorithms to enable model-based generalization with proper conservatism. Empirical results show that our method can generate more conservative behaviors and achieve state-of-the-art performance on offline RL benchmark tasks.
On the Estimation Bias in Double Q-Learning
Sep 29, 2021
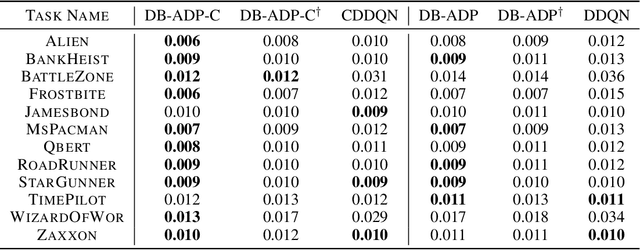
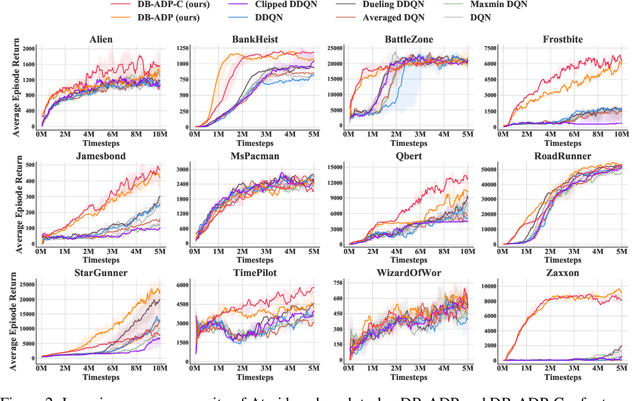
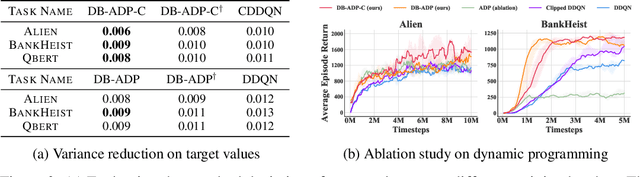
Double Q-learning is a classical method for reducing overestimation bias, which is caused by taking maximum estimated values in the Bellman operation. Its variants in the deep Q-learning paradigm have shown great promise in producing reliable value prediction and improving learning performance. However, as shown by prior work, double Q-learning is not fully unbiased and suffers from underestimation bias. In this paper, we show that such underestimation bias may lead to multiple non-optimal fixed points under an approximated Bellman operator. To address the concerns of converging to non-optimal stationary solutions, we propose a simple but effective approach as a partial fix for the underestimation bias in double Q-learning. This approach leverages an approximate dynamic programming to bound the target value. We extensively evaluate our proposed method in the Atari benchmark tasks and demonstrate its significant improvement over baseline algorithms.
Context-Aware Sparse Deep Coordination Graphs
Jun 05, 2021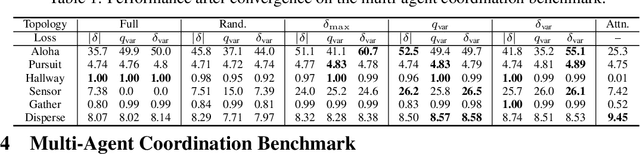
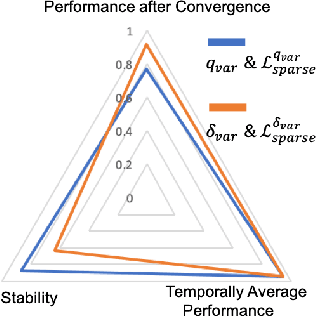
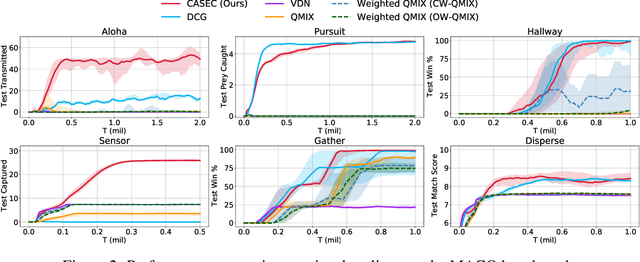
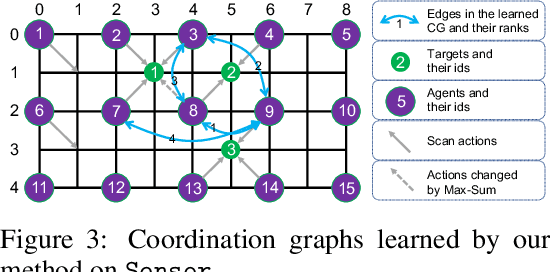
Learning sparse coordination graphs adaptive to the coordination dynamics among agents is a long-standing problem in cooperative multi-agent learning. This paper studies this problem by proposing several value-based and observation-based schemes for learning dynamic topologies and evaluating them on a new Multi-Agent COordination (MACO) benchmark. The benchmark collects classic coordination problems in the literature, increases their difficulty, and classifies them into different types. By analyzing the individual advantages of each learning scheme on each type of problem and their overall performance, we propose a novel method using the variance of utility difference functions to learn context-aware sparse coordination topologies. Moreover, our method learns action representations that effectively reduce the influence of utility functions' estimation errors on graph construction. Experiments show that our method significantly outperforms dense and static topologies across the MACO and StarCraft II micromanagement benchmark.