 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Be A Doctor: Searching for Effective Medical Agent Architectures
Apr 15, 2025Large Language Model (LLM)-based agents have demonstrated strong capabilities across a wide range of tasks, and their application in the medical domain holds particular promise due to the demand for high generalizability and reliance on interdisciplinary knowledge. However, existing medical agent systems often rely on static, manually crafted workflows that lack the flexibility to accommodate diverse diagnostic requirements and adapt to emerging clinical scenarios. Motivated by the success of automated machine learning (AutoML), this paper introduces a novel framework for the automated design of medical agent architectures. Specifically, we define a hierarchical and expressive agent search space that enables dynamic workflow adaptation through structured modifications at the node, structural, and framework levels. Our framework conceptualizes medical agents as graph-based architectures composed of diverse, functional node types and supports iterative self-improvement guided by diagnostic feedback. Experimental results on skin disease diagnosis tasks demonstrate that the proposed method effectively evolves workflow structures and significantly enhances diagnostic accuracy over time. This work represents the first fully automated framework for medical agent architecture design and offers a scalable, adaptable foundation for deploying intelligent agents in real-world clinical environments.
OmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding
Apr 15, 2025



In this paper, we propose a novel framework for controllable video diffusion, OmniVDiff, aiming to synthesize and comprehend multiple video visual content in a single diffusion model. To achieve this, OmniVDiff treats all video visual modalities in the color space to learn a joint distribution, while employing an adaptive control strategy that dynamically adjusts the role of each visual modality during the diffusion process, either as a generation modality or a conditioning modality. This allows flexible manipulation of each modality's role, enabling support for a wide range of tasks. Consequently, our model supports three key functionalities: (1) Text-conditioned video generation: multi-modal visual video sequences (i.e., rgb, depth, canny, segmentaion) are generated based on the text conditions in one diffusion process; (2) Video understanding: OmniVDiff can estimate the depth, canny map, and semantic segmentation across the input rgb frames while ensuring coherence with the rgb input; and (3) X-conditioned video generation: OmniVDiff generates videos conditioned on fine-grained attributes (e.g., depth maps or segmentation maps). By integrating these diverse tasks into a unified video diffusion framework, OmniVDiff enhances the flexibility and scalability for controllable video diffusion, making it an effective tool for a variety of downstream applications, such as video-to-video translation. Extensive experiments demonstrate the effectiveness of our approach, highlighting its potential for various video-related applications.
HD-RAG: Retrieval-Augmented Generation for Hybrid Documents Containing Text and Hierarchical Tables
Apr 13, 2025With the rapid advancement of large language models (LLMs), Retrieval-Augmented Generation (RAG) effectively combines LLMs generative capabilities with external retrieval-based information. The Hybrid Document RAG task aims to integrate textual and hierarchical tabular data for more comprehensive retrieval and generation in complex scenarios. However, there is no existing dataset specifically designed for this task that includes both text and tabular data. Additionally, existing methods struggle to retrieve relevant tabular data and integrate it with text. Semantic similarity-based retrieval lacks accuracy, while table-specific methods fail to handle complex hierarchical structures effectively. Furthermore, the QA task requires complex reasoning and calculations, further complicating the challenge. In this paper, we propose a new large-scale dataset, DocRAGLib, specifically designed for the question answering (QA) task scenario under Hybrid Document RAG. To tackle these challenges, we introduce HD-RAG, a novel framework that incorporates a row-and-column level (RCL) table representation, employs a two-stage process combining ensemble and LLM-based retrieval, and integrates RECAP, which is designed for multi-step reasoning and complex calculations in Document-QA tasks. We conduct comprehensive experiments with DocRAGLib, showing that HD-RAG outperforms existing baselines in both retrieval accuracy and QA performance, demonstrating its effectiveness.
A simulation-heuristics dual-process model for intuitive physics
Apr 13, 2025The role of mental simulation in human physical reasoning is widely acknowledged, but whether it is employed across scenarios with varying simulation costs and where its boundary lies remains unclear. Using a pouring-marble task, our human study revealed two distinct error patterns when predicting pouring angles, differentiated by simulation time. While mental simulation accurately captured human judgments in simpler scenarios, a linear heuristic model better matched human predictions when simulation time exceeded a certain boundary. Motivated by these observations, we propose a dual-process framework, Simulation-Heuristics Model (SHM), where intuitive physics employs simulation for short-time simulation but switches to heuristics when simulation becomes costly. By integrating computational methods previously viewed as separate into a unified model, SHM quantitatively captures their switching mechanism. The SHM aligns more precisely with human behavior and demonstrates consistent predictive performance across diverse scenarios, advancing our understanding of the adaptive nature of intuitive physical reasoning.
CADCrafter: Generating Computer-Aided Design Models from Unconstrained Images
Apr 10, 2025



Creating CAD digital twins from the physical world is crucial for manufacturing, design, and simulation. However, current methods typically rely on costly 3D scanning with labor-intensive post-processing. To provide a user-friendly design process, we explore the problem of reverse engineering from unconstrained real-world CAD images that can be easily captured by users of all experiences. However, the scarcity of real-world CAD data poses challenges in directly training such models. To tackle these challenges, we propose CADCrafter, an image-to-parametric CAD model generation framework that trains solely on synthetic textureless CAD data while testing on real-world images. To bridge the significant representation disparity between images and parametric CAD models, we introduce a geometry encoder to accurately capture diverse geometric features. Moreover, the texture-invariant properties of the geometric features can also facilitate the generalization to real-world scenarios. Since compiling CAD parameter sequences into explicit CAD models is a non-differentiable process, the network training inherently lacks explicit geometric supervision. To impose geometric validity constraints, we employ direct preference optimization (DPO) to fine-tune our model with the automatic code checker feedback on CAD sequence quality. Furthermore, we collected a real-world dataset, comprised of multi-view images and corresponding CAD command sequence pairs, to evaluate our method. Experimental results demonstrate that our approach can robustly handle real unconstrained CAD images, and even generalize to unseen general objects.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025


We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025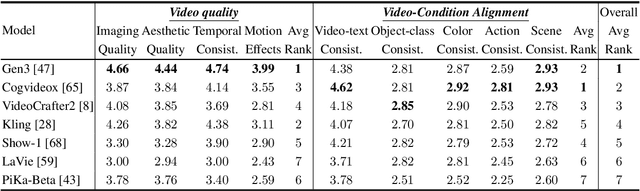
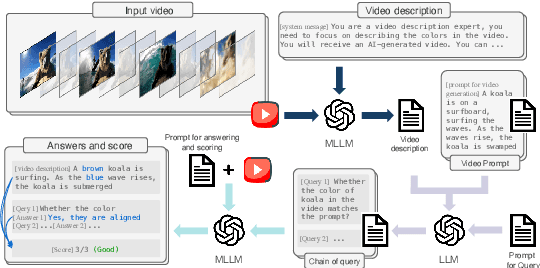
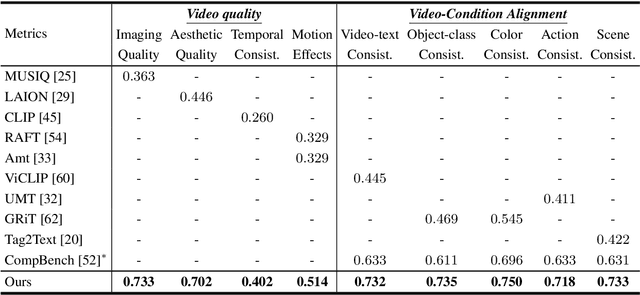
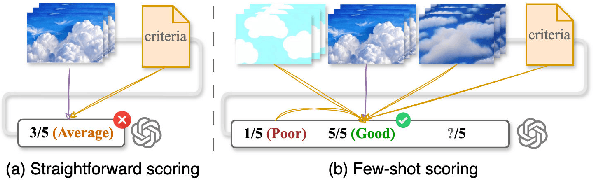
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
Patients Speak, AI Listens: LLM-based Analysis of Online Reviews Uncovers Key Drivers for Urgent Care Satisfaction
Mar 26, 2025Investigating the public experience of urgent care facilities is essential for promoting community healthcare development. Traditional survey methods often fall short due to limited scope, time, and spatial coverage. Crowdsourcing through online reviews or social media offers a valuable approach to gaining such insights. With recent advancements in large language models (LLMs), extracting nuanced perceptions from reviews has become feasible. This study collects Google Maps reviews across the DMV and Florida areas and conducts prompt engineering with the GPT model to analyze the aspect-based sentiment of urgent care. We first analyze the geospatial patterns of various aspects, including interpersonal factors, operational efficiency, technical quality, finances, and facilities. Next, we determine Census Block Group(CBG)-level characteristics underpinning differences in public perception, including population density, median income, GINI Index, rent-to-income ratio, household below poverty rate, no insurance rate, and unemployment rate. Our results show that interpersonal factors and operational efficiency emerge as the strongest determinants of patient satisfaction in urgent care, while technical quality, finances, and facilities show no significant independent effects when adjusted for in multivariate models. Among socioeconomic and demographic factors, only population density demonstrates a significant but modest association with patient ratings, while the remaining factors exhibit no significant correlations. Overall, this study highlights the potential of crowdsourcing to uncover the key factors that matter to residents and provide valuable insights for stakeholders to improve public satisfaction with urgent care.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025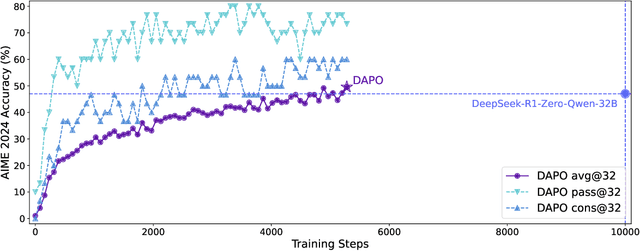

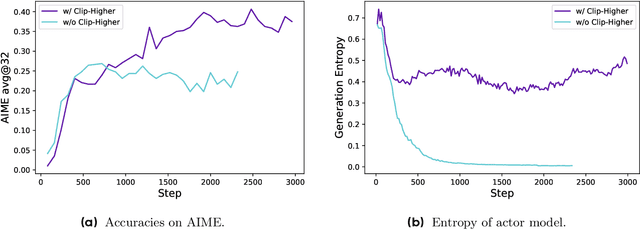

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Project-Probe-Aggregate: Efficient Fine-Tuning for Group Robustness
Mar 12, 2025While image-text foundation models have succeeded across diverse downstream tasks, they still face challenges in the presence of spurious correlations between the input and label. To address this issue, we propose a simple three-step approach,Project-Probe-Aggregate (PPA), that enables parameter-efficient fine-tuning for foundation models without relying on group annotations. Building upon the failure-based debiasing scheme, our method, PPA, improves its two key components: minority samples identification and the robust training algorithm. Specifically, we first train biased classifiers by projecting image features onto the nullspace of class proxies from text encoders. Next, we infer group labels using the biased classifier and probe group targets with prior correction. Finally, we aggregate group weights of each class to produce the debiased classifier. Our theoretical analysis shows that our PPA enhances minority group identification and is Bayes optimal for minimizing the balanced group error, mitigating spurious correlations. Extensive experimental results confirm the effectiveness of our PPA: it outperforms the state-of-the-art by an average worst-group accuracy while requiring less than 0.01% tunable parameters without training group labels.