 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOMURA: Taming the Sand-Glass for Time-Constrained LLM Translation via Reinforcement Learning
Jan 15, 2026Large Language Models (LLMs) have achieved remarkable strides in multilingual translation but are hindered by a systemic cross-lingual verbosity bias, rendering them unsuitable for strict time-constrained tasks like subtitling and dubbing. Current prompt-engineering approaches struggle to resolve this conflict between semantic fidelity and rigid temporal feasibility. To bridge this gap, we first introduce Sand-Glass, a benchmark specifically designed to evaluate translation under syllable-level duration constraints. Furthermore, we propose HOMURA, a reinforcement learning framework that explicitly optimizes the trade-off between semantic preservation and temporal compliance. By employing a KL-regularized objective with a novel dynamic syllable-ratio reward, HOMURA effectively "tames" the output length. Experimental results demonstrate that our method significantly outperforms strong LLM baselines, achieving precise length control that respects linguistic density hierarchies without compromising semantic adequacy.
RIVAL: Reinforcement Learning with Iterative and Adversarial Optimization for Machine Translation
Jun 05, 2025Large language models (LLMs) possess strong multilingual capabilities, and combining Reinforcement Learning from Human Feedback (RLHF) with translation tasks has shown great potential. However, we observe that this paradigm performs unexpectedly poorly when applied to colloquial subtitle translation tasks. In this work, we investigate this issue and find that the offline reward model (RM) gradually diverges from the online LLM due to distributional shift, ultimately leading to undesirable training outcomes. To address this, we propose RIVAL, an adversarial training framework that formulates the process as a min-max game between the RM and the LLM. RIVAL iteratively updates the both models, with the RM trained to distinguish strong from weak translations (qualitative preference reward), and the LLM trained to enhance its translation for closing this gap. To stabilize training and improve generalizability, we also incorporate quantitative preference reward (e.g., BLEU) into the RM, enabling reference-free quality modeling aligned with human evaluation. Through extensive experiments, we demonstrate that the proposed adversarial training framework significantly improves upon translation baselines.
MMD-Newton Method for Multi-objective Optimization
May 20, 2025Maximum mean discrepancy (MMD) has been widely employed to measure the distance between probability distributions. In this paper, we propose using MMD to solve continuous multi-objective optimization problems (MOPs). For solving MOPs, a common approach is to minimize the distance (e.g., Hausdorff) between a finite approximate set of the Pareto front and a reference set. Viewing these two sets as empirical measures, we propose using MMD to measure the distance between them. To minimize the MMD value, we provide the analytical expression of its gradient and Hessian matrix w.r.t. the search variables, and use them to devise a novel set-oriented, MMD-based Newton (MMDN) method. Also, we analyze the theoretical properties of MMD's gradient and Hessian, including the first-order stationary condition and the eigenspectrum of the Hessian, which are important for verifying the correctness of MMDN. To solve complicated problems, we propose hybridizing MMDN with multiobjective evolutionary algorithms (MOEAs), where we first execute an EA for several iterations to get close to the global Pareto front and then warm-start MMDN with the result of the MOEA to efficiently refine the approximation. We empirically test the hybrid algorithm on 11 widely used benchmark problems, and the results show the hybrid (MMDN + MOEA) can achieve a much better optimization accuracy than EA alone with the same computation budget.
Robust UAV Path Planning with Obstacle Avoidance for Emergency Rescue
Jan 16, 2025The unmanned aerial vehicles (UAVs) are efficient tools for diverse tasks such as electronic reconnaissance, agricultural operations and disaster relief. In the complex three-dimensional (3D) environments, the path planning with obstacle avoidance for UAVs is a significant issue for security assurance. In this paper, we construct a comprehensive 3D scenario with obstacles and no-fly zones for dynamic UAV trajectory. Moreover, a novel artificial potential field algorithm coupled with simulated annealing (APF-SA) is proposed to tackle the robust path planning problem. APF-SA modifies the attractive and repulsive potential functions and leverages simulated annealing to escape local minimum and converge to globally optimal solutions. Simulation results demonstrate that the effectiveness of APF-SA, enabling efficient autonomous path planning for UAVs with obstacle avoidance.
Navigating the OverKill in Large Language Models
Jan 31, 2024



Large language models are meticulously aligned to be both helpful and harmless. However, recent research points to a potential overkill which means models may refuse to answer benign queries. In this paper, we investigate the factors for overkill by exploring how models handle and determine the safety of queries. Our findings reveal the presence of shortcuts within models, leading to an over-attention of harmful words like 'kill' and prompts emphasizing safety will exacerbate overkill. Based on these insights, we introduce Self-Contrastive Decoding (Self-CD), a training-free and model-agnostic strategy, to alleviate this phenomenon. We first extract such over-attention by amplifying the difference in the model's output distributions when responding to system prompts that either include or omit an emphasis on safety. Then we determine the final next-token predictions by downplaying the over-attention from the model via contrastive decoding. Empirical results indicate that our method has achieved an average reduction of the refusal rate by 20\% while having almost no impact on safety.
Secrets of RLHF in Large Language Models Part II: Reward Modeling
Jan 12, 2024



Reinforcement Learning from Human Feedback (RLHF) has become a crucial technology for aligning language models with human values and intentions, enabling models to produce more helpful and harmless responses. Reward models are trained as proxies for human preferences to drive reinforcement learning optimization. While reward models are often considered central to achieving high performance, they face the following challenges in practical applications: (1) Incorrect and ambiguous preference pairs in the dataset may hinder the reward model from accurately capturing human intent. (2) Reward models trained on data from a specific distribution often struggle to generalize to examples outside that distribution and are not suitable for iterative RLHF training. In this report, we attempt to address these two issues. (1) From a data perspective, we propose a method to measure the strength of preferences within the data, based on a voting mechanism of multiple reward models. Experimental results confirm that data with varying preference strengths have different impacts on reward model performance. We introduce a series of novel methods to mitigate the influence of incorrect and ambiguous preferences in the dataset and fully leverage high-quality preference data. (2) From an algorithmic standpoint, we introduce contrastive learning to enhance the ability of reward models to distinguish between chosen and rejected responses, thereby improving model generalization. Furthermore, we employ meta-learning to enable the reward model to maintain the ability to differentiate subtle differences in out-of-distribution samples, and this approach can be utilized for iterative RLHF optimization.
High Noise Immune Time-domain Inversion via Cascade Network for Complex Scatterers
Mar 03, 2022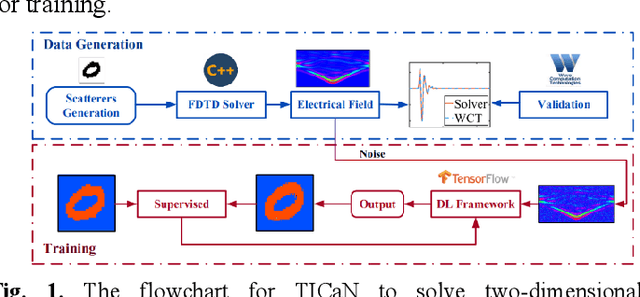
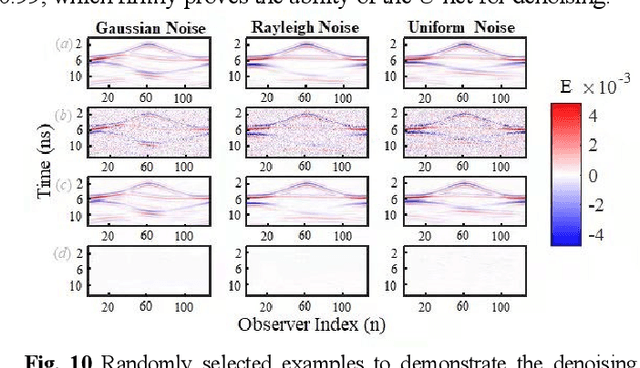
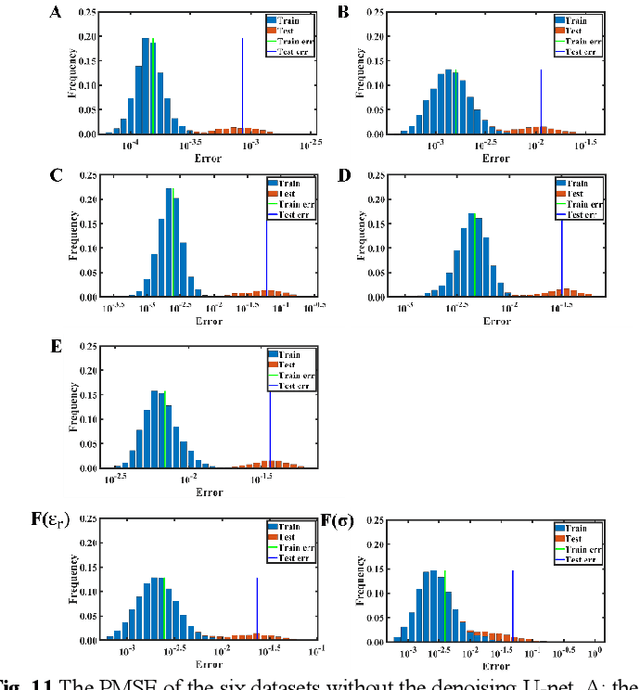
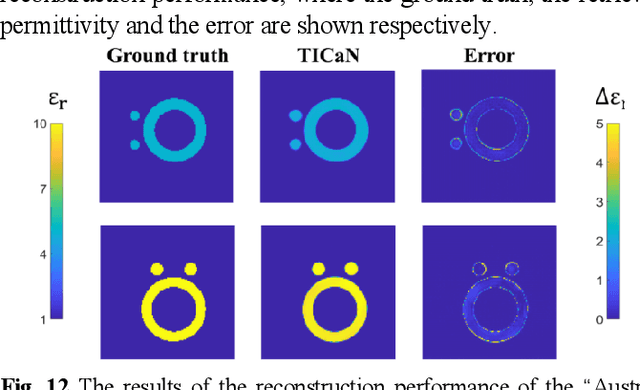
In this paper, a high noise immune time-domain inversion cascade network (TICaN) is proposed to reconstruct scatterers from the measured electromagnetic fields. The TICaN is comprised of a denoising block aiming at improving the signal-to-noise ratio, and an inversion block to reconstruct the electromagnetic properties from the raw time-domain measurements. The scatterers investigated in this study include complicated geometry shapes and high contrast, which cover the stratum layer, lossy medium and hyperfine structure, etc. After being well trained, the performance of the TICaN is evaluated from the perspective of accuracy, noise-immunity, computational acceleration, and generalizability. It can be proven that the proposed framework can realize high-precision inversion under high-intensity noise environments. Compared with traditional reconstruction methods, TICaN avoids the tedious iterative calculation by utilizing the parallel computing ability of GPU and thus significantly reduce the computing time. Besides, the proposed TICaN has certain generalization ability in reconstructing the unknown scatterers such as the famous Austria rings. Herein, it is confident that the proposed TICaN will serve as a new path for real-time quantitative microwave imaging for various practical scenarios.