 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajTok: Learning Trajectory Tokens enables better Video Understanding
Feb 26, 2026Tokenization in video models, typically through patchification, generates an excessive and redundant number of tokens. This severely limits video efficiency and scalability. While recent trajectory-based tokenizers offer a promising solution by decoupling video duration from token count, they rely on complex external segmentation and tracking pipelines that are slow and task-agnostic. We propose TrajTok, an end-to-end video tokenizer module that is fully integrated and co-trained with video models for a downstream objective, dynamically adapting its token granularity to semantic complexity, independent of video duration. TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, TrajTok is lightweight and efficient, yet empirically improves video understanding performance. With TrajTok, we implement a video CLIP model trained from scratch (TrajViT2). It achieves the best accuracy at scale across both classification and retrieval benchmarks, while maintaining efficiency comparable to the best token-merging methods. TrajTok also proves to be a versatile component beyond its role as a tokenizer. We show that it can be seamlessly integrated as either a probing head for pretrained visual features (TrajAdapter) or an alignment connector in vision-language models (TrajVLM) with especially strong performance in long-video reasoning.
Synthetic Visual Genome
Jun 09, 2025Reasoning over visual relationships-spatial, functional, interactional, social, etc.-is considered to be a fundamental component of human cognition. Yet, despite the major advances in visual comprehension in multimodal language models (MLMs), precise reasoning over relationships and their generations remains a challenge. We introduce ROBIN: an MLM instruction-tuned with densely annotated relationships capable of constructing high-quality dense scene graphs at scale. To train ROBIN, we curate SVG, a synthetic scene graph dataset by completing the missing relations of selected objects in existing scene graphs using a teacher MLM and a carefully designed filtering process to ensure high-quality. To generate more accurate and rich scene graphs at scale for any image, we introduce SG-EDIT: a self-distillation framework where GPT-4o further refines ROBIN's predicted scene graphs by removing unlikely relations and/or suggesting relevant ones. In total, our dataset contains 146K images and 5.6M relationships for 2.6M objects. Results show that our ROBIN-3B model, despite being trained on less than 3 million instances, outperforms similar-size models trained on over 300 million instances on relationship understanding benchmarks, and even surpasses larger models up to 13B parameters. Notably, it achieves state-of-the-art performance in referring expression comprehension with a score of 88.9, surpassing the previous best of 87.4. Our results suggest that training on the refined scene graph data is crucial to maintaining high performance across diverse visual reasoning task.
One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory
May 29, 2025Effective video tokenization is critical for scaling transformer models for long videos. Current approaches tokenize videos using space-time patches, leading to excessive tokens and computational inefficiencies. The best token reduction strategies degrade performance and barely reduce the number of tokens when the camera moves. We introduce grounded video tokenization, a paradigm that organizes tokens based on panoptic sub-object trajectories rather than fixed patches. Our method aligns with fundamental perceptual principles, ensuring that tokenization reflects scene complexity rather than video duration. We propose TrajViT, a video encoder that extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence. Trained with contrastive learning, TrajViT significantly outperforms space-time ViT (ViT3D) across multiple video understanding benchmarks, e.g., TrajViT outperforms ViT3D by a large margin of 6% top-5 recall in average at video-text retrieval task with 10x token deduction. We also show TrajViT as a stronger model than ViT3D for being the video encoder for modern VideoLLM, obtaining an average of 5.2% performance improvement across 6 VideoQA benchmarks while having 4x faster training time and 18x less inference FLOPs. TrajViT is the first efficient encoder to consistently outperform ViT3D across diverse video analysis tasks, making it a robust and scalable solution.
Acoustic Volume Rendering for Neural Impulse Response Fields
Nov 09, 2024



Realistic audio synthesis that captures accurate acoustic phenomena is essential for creating immersive experiences in virtual and augmented reality. Synthesizing the sound received at any position relies on the estimation of impulse response (IR), which characterizes how sound propagates in one scene along different paths before arriving at the listener's position. In this paper, we present Acoustic Volume Rendering (AVR), a novel approach that adapts volume rendering techniques to model acoustic impulse responses. While volume rendering has been successful in modeling radiance fields for images and neural scene representations, IRs present unique challenges as time-series signals. To address these challenges, we introduce frequency-domain volume rendering and use spherical integration to fit the IR measurements. Our method constructs an impulse response field that inherently encodes wave propagation principles and achieves state-of-the-art performance in synthesizing impulse responses for novel poses. Experiments show that AVR surpasses current leading methods by a substantial margin. Additionally, we develop an acoustic simulation platform, AcoustiX, which provides more accurate and realistic IR simulations than existing simulators. Code for AVR and AcoustiX are available at https://zitonglan.github.io/avr.
MoveLight: Enhancing Traffic Signal Control through Movement-Centric Deep Reinforcement Learning
Jul 24, 2024



This paper introduces MoveLight, a novel traffic signal control system that enhances urban traffic management through movement-centric deep reinforcement learning. By leveraging detailed real-time data and advanced machine learning techniques, MoveLight overcomes the limitations of traditional traffic signal control methods. It employs a lane-level control approach using the FRAP algorithm to achieve dynamic and adaptive traffic signal control, optimizing traffic flow, reducing congestion, and improving overall efficiency. Our research demonstrates the scalability and effectiveness of MoveLight across single intersections, arterial roads, and network levels. Experimental results using real-world datasets from Cologne and Hangzhou show significant improvements in metrics such as queue length, delay, and throughput compared to existing methods. This study highlights the transformative potential of deep reinforcement learning in intelligent traffic signal control, setting a new standard for sustainable and efficient urban transportation systems.
Iterated Learning Improves Compositionality in Large Vision-Language Models
Apr 02, 2024



A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most-if not all-our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of " a girl in white facing a man in black" and "a girl in black facing a man in white". Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission-the need to teach a new generation-as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become "easier to learn", a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata
Jan 11, 2023



We learn a visual representation that captures information about the camera that recorded a given photo. To do this, we train a multimodal embedding between image patches and the EXIF metadata that cameras automatically insert into image files. Our model represents this metadata by simply converting it to text and then processing it with a transformer. The features that we learn significantly outperform other self-supervised and supervised features on downstream image forensics and calibration tasks. In particular, we successfully localize spliced image regions "zero shot" by clustering the visual embeddings for all of the patches within an image.
A-ESRGAN: Training Real-World Blind Super-Resolution with Attention U-Net Discriminators
Dec 19, 2021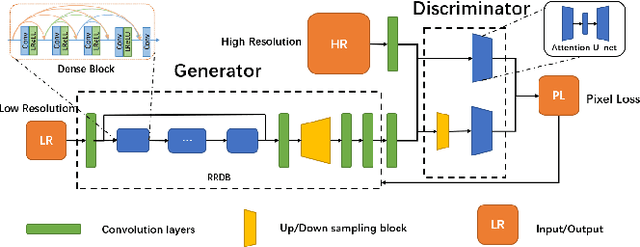

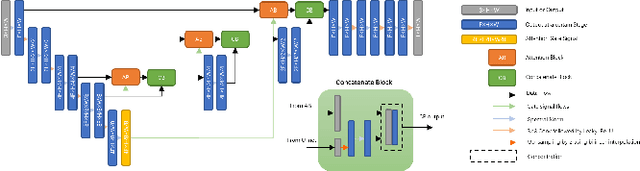
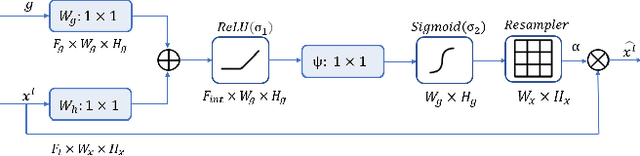
Blind image super-resolution(SR) is a long-standing task in CV that aims to restore low-resolution images suffering from unknown and complex distortions. Recent work has largely focused on adopting more complicated degradation models to emulate real-world degradations. The resulting models have made breakthroughs in perceptual loss and yield perceptually convincing results. However, the limitation brought by current generative adversarial network structures is still significant: treating pixels equally leads to the ignorance of the image's structural features, and results in performance drawbacks such as twisted lines and background over-sharpening or blurring. In this paper, we present A-ESRGAN, a GAN model for blind SR tasks featuring an attention U-Net based, multi-scale discriminator that can be seamlessly integrated with other generators. To our knowledge, this is the first work to introduce attention U-Net structure as the discriminator of GAN to solve blind SR problems. And the paper also gives an interpretation for the mechanism behind multi-scale attention U-Net that brings performance breakthrough to the model. Through comparison experiments with prior works, our model presents state-of-the-art level performance on the non-reference natural image quality evaluator metric. And our ablation studies have shown that with our discriminator, the RRDB based generator can leverage the structural features of an image in multiple scales, and consequently yields more perceptually realistic high-resolution images compared to prior works.