 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts-Agent: Data Recipes for Agentic Models
Jun 23, 2026Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
SERA: Soft-Verified Efficient Repository Agents
Jan 28, 2026Open-weight coding agents should hold a fundamental advantage over closed-source systems: they can be specialized to private codebases, encoding repository-specific information directly in their weights. Yet the cost and complexity of training has kept this advantage theoretical. We show it is now practical. We present Soft-Verified Efficient Repository Agents (SERA), an efficient method for training coding agents that enables the rapid and cheap creation of agents specialized to private codebases. Using only supervised finetuning (SFT), SERA achieves state-of-the-art results among fully open-source (open data, method, code) models while matching the performance of frontier open-weight models like Devstral-Small-2. Creating SERA models is 26x cheaper than reinforcement learning and 57x cheaper than previous synthetic data methods to reach equivalent performance. Our method, Soft Verified Generation (SVG), generates thousands of trajectories from a single code repository. Combined with cost-efficiency, this enables specialization to private codebases. Beyond repository specialization, we apply SVG to a larger corpus of codebases, generating over 200,000 synthetic trajectories. We use this dataset to provide detailed analysis of scaling laws, ablations, and confounding factors for training coding agents. Overall, we believe our work will greatly accelerate research on open coding agents and showcase the advantage of open-source models that can specialize to private codebases. We release SERA as the first model in Ai2's Open Coding Agents series, along with all our code, data, and Claude Code integration to support the research community.
Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
Dec 04, 2024Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.
Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass
May 29, 2024



Many applications today provide users with multiple auto-complete drafts as they type, including GitHub's code completion, Gmail's smart compose, and Apple's messaging auto-suggestions. Under the hood, language models support this by running an autoregressive inference pass to provide a draft. Consequently, providing $k$ drafts to the user requires running an expensive language model $k$ times. To alleviate the computation cost of running $k$ inference passes, we propose Superposed Decoding, a new decoding algorithm that generates $k$ drafts at the computation cost of one autoregressive inference pass. We achieve this by feeding a superposition of the most recent token embeddings from the $k$ drafts as input to the next decoding step of the language model. At every inference step we combine the $k$ drafts with the top-$k$ tokens to get $k^2$ new drafts and cache the $k$ most likely options, using an n-gram interpolation with minimal compute overhead to filter out incoherent generations. Our experiments show that $k$ drafts from Superposed Decoding are at least as coherent and factual as Nucleus Sampling and Greedy Decoding respectively, while being at least $2.44\times$ faster for $k\ge3$. In a compute-normalized setting, user evaluations demonstrably favor text generated by Superposed Decoding over Nucleus Sampling. Code and more examples open-sourced at https://github.com/RAIVNLab/SuperposedDecoding.
Are "Hierarchical" Visual Representations Hierarchical?
Nov 23, 2023Learned visual representations often capture large amounts of semantic information for accurate downstream applications. Human understanding of the world is fundamentally grounded in hierarchy. To mimic this and further improve representation capabilities, the community has explored "hierarchical" visual representations that aim at modeling the underlying hierarchy of the visual world. In this work, we set out to investigate if hierarchical visual representations truly capture the human perceived hierarchy better than standard learned representations. To this end, we create HierNet, a suite of 12 datasets spanning 3 kinds of hierarchy from the BREEDs subset of ImageNet. After extensive evaluation of Hyperbolic and Matryoshka Representations across training setups, we conclude that they do not capture hierarchy any better than the standard representations but can assist in other aspects like search efficiency and interpretability. Our benchmark and the datasets are open-sourced at https://github.com/ethanlshen/HierNet.
Generative Visual Question Answering
Jul 18, 2023Multi-modal tasks involving vision and language in deep learning continue to rise in popularity and are leading to the development of newer models that can generalize beyond the extent of their training data. The current models lack temporal generalization which enables models to adapt to changes in future data. This paper discusses a viable approach to creating an advanced Visual Question Answering (VQA) model which can produce successful results on temporal generalization. We propose a new data set, GenVQA, utilizing images and captions from the VQAv2 and MS-COCO dataset to generate new images through stable diffusion. This augmented dataset is then used to test a combination of seven baseline and cutting edge VQA models. Performance evaluation focuses on questions mirroring the original VQAv2 dataset, with the answers having been adjusted to the new images. This paper's purpose is to investigate the robustness of several successful VQA models to assess their performance on future data distributions. Model architectures are analyzed to identify common stylistic choices that improve generalization under temporal distribution shifts. This research highlights the importance of creating a large-scale future shifted dataset. This data can enhance the robustness of VQA models, allowing their future peers to have improved ability to adapt to temporal distribution shifts.
Model-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021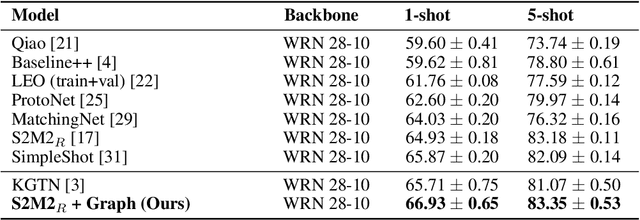
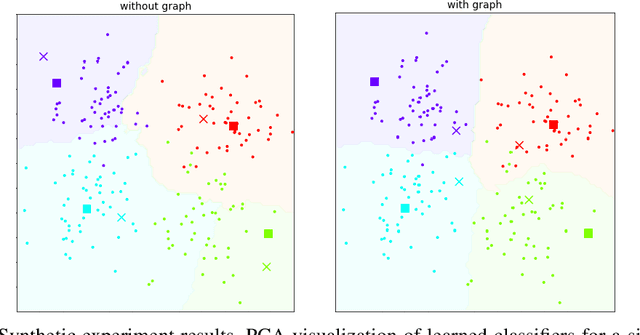
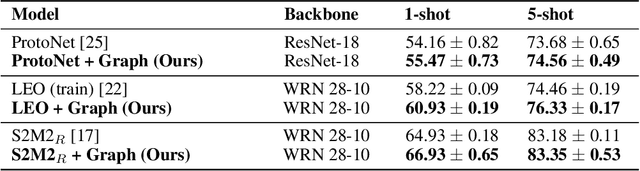
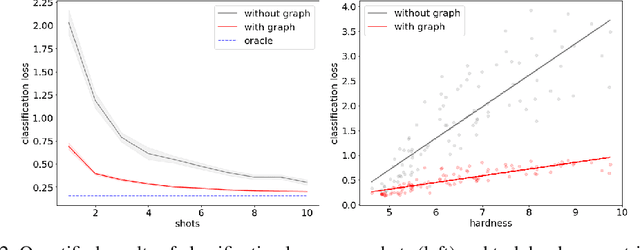
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.