 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPER: Constrained and Procedural Reasoning for Robotic Scientific Experiments
Feb 10, 2026Robotic assistance in scientific laboratories requires procedurally correct long-horizon manipulation, reliable execution under limited supervision, and robustness in low-demonstration regimes. Such conditions greatly challenge end-to-end vision-language-action (VLA) models, whose assumptions of recoverable errors and data-driven policy learning often break down in protocol-sensitive experiments. We propose CAPER, a framework for Constrained And ProcEdural Reasoning for robotic scientific experiments, which explicitly restricts where learning and reasoning occur in the planning and control pipeline. Rather than strengthening end-to-end policies, CAPER enforces a responsibility-separated structure: task-level reasoning generates procedurally valid action sequences under explicit constraints, mid-level multimodal grounding realizes subtasks without delegating spatial decision-making to large language models, and low-level control adapts to physical uncertainty via reinforcement learning with minimal demonstrations. By encoding procedural commitments through interpretable intermediate representations, CAPER prevents execution-time violations of experimental logic, improving controllability, robustness, and data efficiency. Experiments on a scientific workflow benchmark and a public long-horizon manipulation dataset demonstrate consistent improvements in success rate and procedural correctness, particularly in low-data and long-horizon settings.
Differentiate-and-Inject: Enhancing VLAs via Functional Differentiation Induced by In-Parameter Structural Reasoning
Feb 07, 2026As robots are expected to perform increasingly diverse tasks, they must understand not only low-level actions but also the higher-level structure that determines how a task should unfold. Existing vision-language-action (VLA) models struggle with this form of task-level reasoning. They either depend on prompt-based in-context decomposition, which is unstable and sensitive to linguistic variations, or end-to-end long-horizon training, which requires large-scale demonstrations and entangles task-level reasoning with low-level control. We present in-parameter structured task reasoning (iSTAR), a framework for enhancing VLA models via functional differentiation induced by in-parameter structural reasoning. Instead of treating VLAs as monolithic policies, iSTAR embeds task-level semantic structure directly into model parameters, enabling differentiated task-level inference without external planners or handcrafted prompt inputs. This injected structure takes the form of implicit dynamic scene-graph knowledge that captures object relations, subtask semantics, and task-level dependencies in parameter space. Across diverse manipulation benchmarks, iSTAR achieves more reliable task decompositions and higher success rates than both in-context and end-to-end VLA baselines, demonstrating the effectiveness of parameter-space structural reasoning for functional differentiation and improved generalization across task variations.
Unveiling the Impact of Multimodal Features on Chinese Spelling Correction: From Analysis to Design
Apr 10, 2025



The Chinese Spelling Correction (CSC) task focuses on detecting and correcting spelling errors in sentences. Current research primarily explores two approaches: traditional multimodal pre-trained models and large language models (LLMs). However, LLMs face limitations in CSC, particularly over-correction, making them suboptimal for this task. While existing studies have investigated the use of phonetic and graphemic information in multimodal CSC models, effectively leveraging these features to enhance correction performance remains a challenge. To address this, we propose the Multimodal Analysis for Character Usage (\textbf{MACU}) experiment, identifying potential improvements for multimodal correctison. Based on empirical findings, we introduce \textbf{NamBert}, a novel multimodal model for Chinese spelling correction. Experiments on benchmark datasets demonstrate NamBert's superiority over SOTA methods. We also conduct a comprehensive comparison between NamBert and LLMs, systematically evaluating their strengths and limitations in CSC. Our code and model are available at https://github.com/iioSnail/NamBert.
Discovering Predictable Latent Factors for Time Series Forecasting
Mar 18, 2023Modern time series forecasting methods, such as Transformer and its variants, have shown strong ability in sequential data modeling. To achieve high performance, they usually rely on redundant or unexplainable structures to model complex relations between variables and tune the parameters with large-scale data. Many real-world data mining tasks, however, lack sufficient variables for relation reasoning, and therefore these methods may not properly handle such forecasting problems. With insufficient data, time series appear to be affected by many exogenous variables, and thus, the modeling becomes unstable and unpredictable. To tackle this critical issue, in this paper, we develop a novel algorithmic framework for inferring the intrinsic latent factors implied by the observable time series. The inferred factors are used to form multiple independent and predictable signal components that enable not only sparse relation reasoning for long-term efficiency but also reconstructing the future temporal data for accurate prediction. To achieve this, we introduce three characteristics, i.e., predictability, sufficiency, and identifiability, and model these characteristics via the powerful deep latent dynamics models to infer the predictable signal components. Empirical results on multiple real datasets show the efficiency of our method for different kinds of time series forecasting. The statistical analysis validates the predictability of the learned latent factors.
Video Captioning Using Weak Annotation
Sep 02, 2020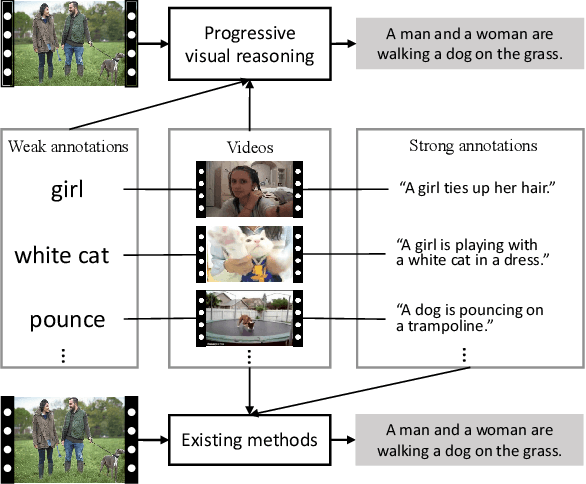
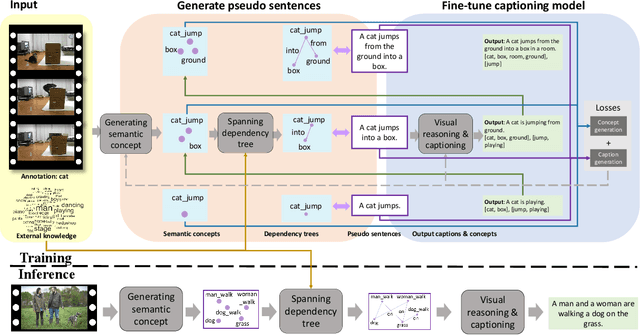
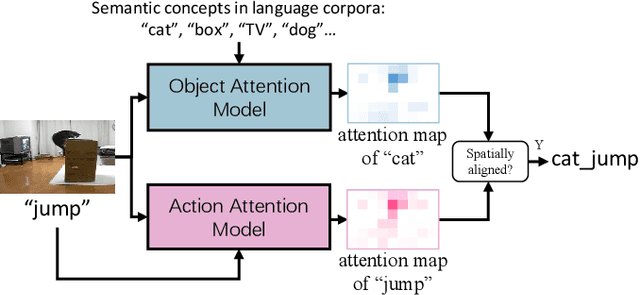
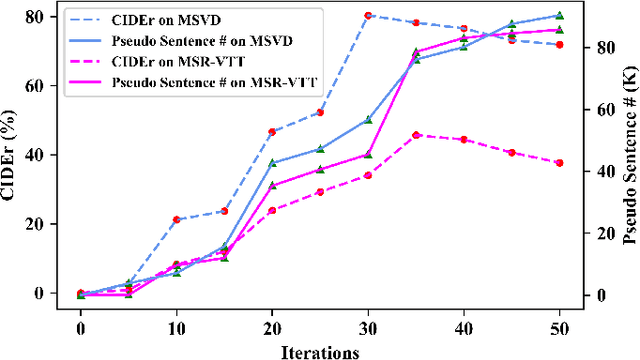
Video captioning has shown impressive progress in recent years. One key reason of the performance improvements made by existing methods lie in massive paired video-sentence data, but collecting such strong annotation, i.e., high-quality sentences, is time-consuming and laborious. It is the fact that there now exist an amazing number of videos with weak annotation that only contains semantic concepts such as actions and objects. In this paper, we investigate using weak annotation instead of strong annotation to train a video captioning model. To this end, we propose a progressive visual reasoning method that progressively generates fine sentences from weak annotations by inferring more semantic concepts and their dependency relationships for video captioning. To model concept relationships, we use dependency trees that are spanned by exploiting external knowledge from large sentence corpora. Through traversing the dependency trees, the sentences are generated to train the captioning model. Accordingly, we develop an iterative refinement algorithm that refines sentences via spanning dependency trees and fine-tunes the captioning model using the refined sentences in an alternative training manner. Experimental results demonstrate that our method using weak annotation is very competitive to the state-of-the-art methods using strong annotation.
Relational Reasoning using Prior Knowledge for Visual Captioning
Jun 04, 2019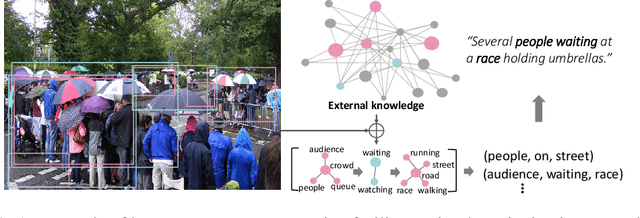
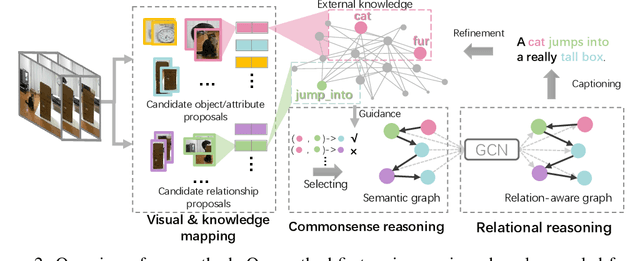

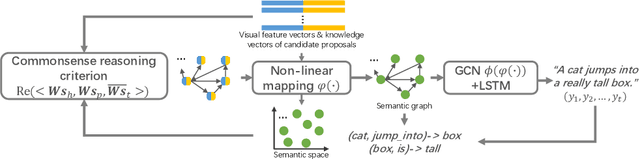
Exploiting relationships among objects has achieved remarkable progress in interpreting images or videos by natural language. Most existing methods resort to first detecting objects and their relationships, and then generating textual descriptions, which heavily depends on pre-trained detectors and leads to performance drop when facing problems of heavy occlusion, tiny-size objects and long-tail in object detection. In addition, the separate procedure of detecting and captioning results in semantic inconsistency between the pre-defined object/relation categories and the target lexical words. We exploit prior human commonsense knowledge for reasoning relationships between objects without any pre-trained detectors and reaching semantic coherency within one image or video in captioning. The prior knowledge (e.g., in the form of knowledge graph) provides commonsense semantic correlation and constraint between objects that are not explicit in the image and video, serving as useful guidance to build semantic graph for sentence generation. Particularly, we present a joint reasoning method that incorporates 1) commonsense reasoning for embedding image or video regions into semantic space to build semantic graph and 2) relational reasoning for encoding semantic graph to generate sentences. Extensive experiments on the MS-COCO image captioning benchmark and the MSVD video captioning benchmark validate the superiority of our method on leveraging prior commonsense knowledge to enhance relational reasoning for visual captioning.