 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEA-Diffusion: Parameter-Efficient Adapter with Knowledge Distillation in non-English Text-to-Image Generation
Nov 28, 2023Text-to-image diffusion models are well-known for their ability to generate realistic images based on textual prompts. However, the existing works have predominantly focused on English, lacking support for non-English text-to-image models. The most commonly used translation methods cannot solve the generation problem related to language culture, while training from scratch on a specific language dataset is prohibitively expensive. In this paper, we are inspired to propose a simple plug-and-play language transfer method based on knowledge distillation. All we need to do is train a lightweight MLP-like parameter-efficient adapter (PEA) with only 6M parameters under teacher knowledge distillation along with a small parallel data corpus. We are surprised to find that freezing the parameters of UNet can still achieve remarkable performance on the language-specific prompt evaluation set, demonstrating that PEA can stimulate the potential generation ability of the original UNet. Additionally, it closely approaches the performance of the English text-to-image model on a general prompt evaluation set. Furthermore, our adapter can be used as a plugin to achieve significant results in downstream tasks in cross-lingual text-to-image generation. Code will be available at: https://github.com/OPPO-Mente-Lab/PEA-Diffusion
Decouple Content and Motion for Conditional Image-to-Video Generation
Nov 24, 2023



The goal of conditional image-to-video (cI2V) generation is to create a believable new video by beginning with the condition, i.e., one image and text.The previous cI2V generation methods conventionally perform in RGB pixel space, with limitations in modeling motion consistency and visual continuity. Additionally, the efficiency of generating videos in pixel space is quite low.In this paper, we propose a novel approach to address these challenges by disentangling the target RGB pixels into two distinct components: spatial content and temporal motions. Specifically, we predict temporal motions which include motion vector and residual based on a 3D-UNet diffusion model. By explicitly modeling temporal motions and warping them to the starting image, we improve the temporal consistency of generated videos. This results in a reduction of spatial redundancy, emphasizing temporal details. Our proposed method achieves performance improvements by disentangling content and motion, all without introducing new structural complexities to the model. Extensive experiments on various datasets confirm our approach's superior performance over the majority of state-of-the-art methods in both effectiveness and efficiency.
FBChain: A Blockchain-based Federated Learning Model with Efficiency and Secure Communication
Nov 21, 2023



Privacy and security in the parameter transmission process of federated learning are currently among the most prominent concerns. However, there are two thorny problems caused by unprotected communication methods: "parameter-leakage" and "inefficient-communication". This article proposes Blockchain-based Federated Learning (FBChain) model for federated learning parameter communication to overcome the above two problems. First, we utilize the immutability of blockchain to store the global model and hash value of local model parameters in case of tampering during the communication process, protect data privacy by encrypting parameters, and verify data consistency by comparing the hash values of local parameters, thus addressing the "parameter-leakage" problem. Second, the Proof of Weighted Link Speed (PoWLS) consensus algorithm comprehensively selects nodes with the higher weighted link speed to aggregate global model and package blocks, thereby solving the "inefficient-communication" problem. Experimental results demonstrate the effectiveness of our proposed FBChain model and its ability to improve model communication efficiency in federated learning.
Supported Trust Region Optimization for Offline Reinforcement Learning
Nov 15, 2023



Offline reinforcement learning suffers from the out-of-distribution issue and extrapolation error. Most policy constraint methods regularize the density of the trained policy towards the behavior policy, which is too restrictive in most cases. We propose Supported Trust Region optimization (STR) which performs trust region policy optimization with the policy constrained within the support of the behavior policy, enjoying the less restrictive support constraint. We show that, when assuming no approximation and sampling error, STR guarantees strict policy improvement until convergence to the optimal support-constrained policy in the dataset. Further with both errors incorporated, STR still guarantees safe policy improvement for each step. Empirical results validate the theory of STR and demonstrate its state-of-the-art performance on MuJoCo locomotion domains and much more challenging AntMaze domains.
A Single 2D Pose with Context is Worth Hundreds for 3D Human Pose Estimation
Nov 09, 2023



The dominant paradigm in 3D human pose estimation that lifts a 2D pose sequence to 3D heavily relies on long-term temporal clues (i.e., using a daunting number of video frames) for improved accuracy, which incurs performance saturation, intractable computation and the non-causal problem. This can be attributed to their inherent inability to perceive spatial context as plain 2D joint coordinates carry no visual cues. To address this issue, we propose a straightforward yet powerful solution: leveraging the readily available intermediate visual representations produced by off-the-shelf (pre-trained) 2D pose detectors -- no finetuning on the 3D task is even needed. The key observation is that, while the pose detector learns to localize 2D joints, such representations (e.g., feature maps) implicitly encode the joint-centric spatial context thanks to the regional operations in backbone networks. We design a simple baseline named Context-Aware PoseFormer to showcase its effectiveness. Without access to any temporal information, the proposed method significantly outperforms its context-agnostic counterpart, PoseFormer, and other state-of-the-art methods using up to hundreds of video frames regarding both speed and precision. Project page: https://qitaozhao.github.io/ContextAware-PoseFormer
An Empirical Study of Frame Selection for Text-to-Video Retrieval
Nov 01, 2023



Text-to-video retrieval (TVR) aims to find the most relevant video in a large video gallery given a query text. The intricate and abundant context of the video challenges the performance and efficiency of TVR. To handle the serialized video contexts, existing methods typically select a subset of frames within a video to represent the video content for TVR. How to select the most representative frames is a crucial issue, whereby the selected frames are required to not only retain the semantic information of the video but also promote retrieval efficiency by excluding temporally redundant frames. In this paper, we make the first empirical study of frame selection for TVR. We systemically classify existing frame selection methods into text-free and text-guided ones, under which we detailedly analyze six different frame selections in terms of effectiveness and efficiency. Among them, two frame selections are first developed in this paper. According to the comprehensive analysis on multiple TVR benchmarks, we empirically conclude that the TVR with proper frame selections can significantly improve the retrieval efficiency without sacrificing the retrieval performance.
MCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023



With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.
Med-DANet V2: A Flexible Dynamic Architecture for Efficient Medical Volumetric Segmentation
Oct 28, 2023



Recent works have shown that the computational efficiency of 3D medical image (e.g. CT and MRI) segmentation can be impressively improved by dynamic inference based on slice-wise complexity. As a pioneering work, a dynamic architecture network for medical volumetric segmentation (i.e. Med-DANet) has achieved a favorable accuracy and efficiency trade-off by dynamically selecting a suitable 2D candidate model from the pre-defined model bank for different slices. However, the issues of incomplete data analysis, high training costs, and the two-stage pipeline in Med-DANet require further improvement. To this end, this paper further explores a unified formulation of the dynamic inference framework from the perspective of both the data itself and the model structure. For each slice of the input volume, our proposed method dynamically selects an important foreground region for segmentation based on the policy generated by our Decision Network and Crop Position Network. Besides, we propose to insert a stage-wise quantization selector to the employed segmentation model (e.g. U-Net) for dynamic architecture adapting. Extensive experiments on BraTS 2019 and 2020 show that our method achieves comparable or better performance than previous state-of-the-art methods with much less model complexity. Compared with previous methods Med-DANet and TransBTS with dynamic and static architecture respectively, our framework improves the model efficiency by up to nearly 4.1 and 17.3 times with comparable segmentation results on BraTS 2019.
Knowledge Editing for Large Language Models: A Survey
Oct 26, 2023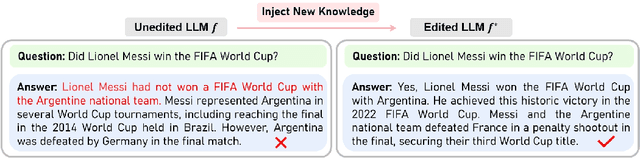
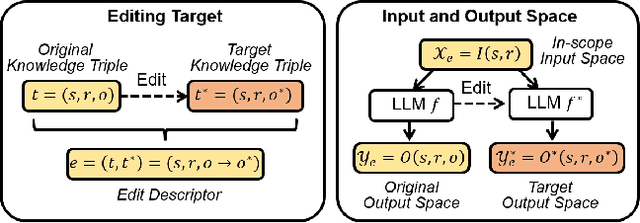

Large language models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME) has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.
Adaptive Tuning of Robotic Polishing Skills based on Force Feedback Model
Oct 23, 2023



Acquiring human skills offers an efficient approach to tackle complex task planning challenges. When performing a learned skill model for a continuous contact task, such as robot polishing in an uncertain environment, the robot needs to be able to adaptively modify the skill model to suit the environment and perform the desired task. The environmental perturbation of the polishing task is mainly reflected in the variation of contact force. Therefore, adjusting the task skill model by providing feedback on the contact force deviation is an effective way to meet the task requirements. In this study, a phase-modulated diagonal recurrent neural network (PMDRNN) is proposed for force feedback model learning in the robotic polishing task. The contact between the tool and the workpiece in the polishing task can be considered a dynamic system. In comparison to the existing feedforward neural network phase-modulated neural network (PMNN), PMDRNN combines the diagonal recurrent network structure with the phase-modulated neural network layer to improve the learning performance of the feedback model for dynamic systems. Specifically, data from real-world robot polishing experiments are used to learn the feedback model. PMDRNN demonstrates a significant reduction in the training error of the feedback model when compared to PMNN. Building upon this, the combination of PMDRNN and dynamic movement primitives (DMPs) can be used for real-time adjustment of skills for polishing tasks and effectively improve the robustness of the task skill model. Finally, real-world robotic polishing experiments are conducted to demonstrate the effectiveness of the approach.