 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart Aware Contrastive Learning for Self-Supervised Action Recognition
May 11, 2023In recent years, remarkable results have been achieved in self-supervised action recognition using skeleton sequences with contrastive learning. It has been observed that the semantic distinction of human action features is often represented by local body parts, such as legs or hands, which are advantageous for skeleton-based action recognition. This paper proposes an attention-based contrastive learning framework for skeleton representation learning, called SkeAttnCLR, which integrates local similarity and global features for skeleton-based action representations. To achieve this, a multi-head attention mask module is employed to learn the soft attention mask features from the skeletons, suppressing non-salient local features while accentuating local salient features, thereby bringing similar local features closer in the feature space. Additionally, ample contrastive pairs are generated by expanding contrastive pairs based on salient and non-salient features with global features, which guide the network to learn the semantic representations of the entire skeleton. Therefore, with the attention mask mechanism, SkeAttnCLR learns local features under different data augmentation views. The experiment results demonstrate that the inclusion of local feature similarity significantly enhances skeleton-based action representation. Our proposed SkeAttnCLR outperforms state-of-the-art methods on NTURGB+D, NTU120-RGB+D, and PKU-MMD datasets.
SkeletonMAE: Spatial-Temporal Masked Autoencoders for Self-supervised Skeleton Action Recognition
Sep 01, 2022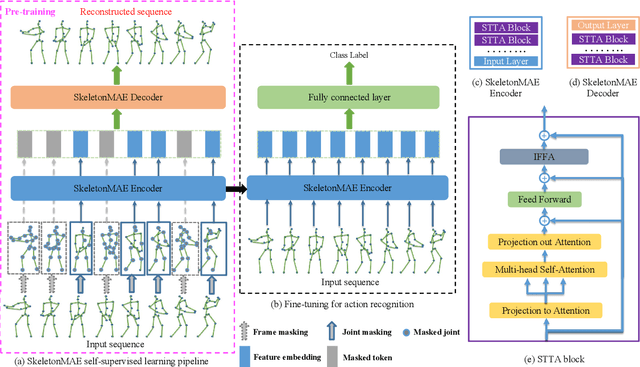
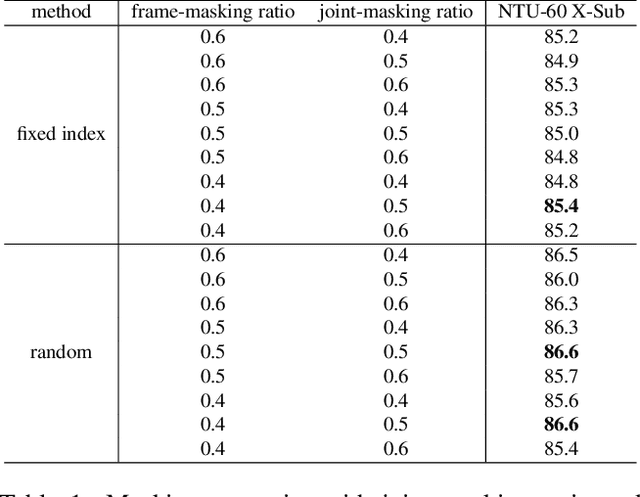
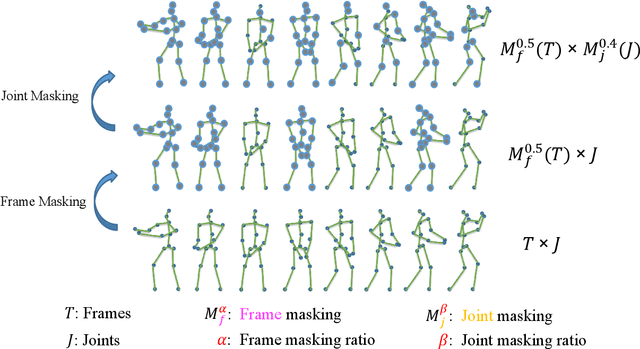
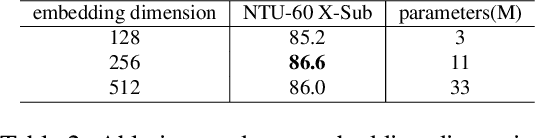
Fully supervised skeleton-based action recognition has achieved great progress with the blooming of deep learning techniques. However, these methods require sufficient labeled data which is not easy to obtain. In contrast, self-supervised skeleton-based action recognition has attracted more attention. With utilizing the unlabeled data, more generalizable features can be learned to alleviate the overfitting problem and reduce the demand of massive labeled training data. Inspired by the MAE, we propose a spatial-temporal masked autoencoder framework for self-supervised 3D skeleton-based action recognition (SkeletonMAE). Following MAE's masking and reconstruction pipeline, we utilize a skeleton based encoder-decoder transformer architecture to reconstruct the masked skeleton sequences. A novel masking strategy, named Spatial-Temporal Masking, is introduced in terms of both joint-level and frame-level for the skeleton sequence. This pre-training strategy makes the encoder output generalizable skeleton features with spatial and temporal dependencies. Given the unmasked skeleton sequence, the encoder is fine-tuned for the action recognition task. Extensive experiments show that our SkeletonMAE achieves remarkable performance and outperforms the state-of-the-art methods on both NTU RGB+D and NTU RGB+D 120 datasets.