 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning Based Multi-Scale Exposure Fusion
Sep 26, 2024



Unsupervised learning based multi-scale exposure fusion (ULMEF) is efficient for fusing differently exposed low dynamic range (LDR) images into a higher quality LDR image for a high dynamic range (HDR) scene. Unlike supervised learning, loss functions play a crucial role in the ULMEF. In this paper, novel loss functions are proposed for the ULMEF and they are defined by using all the images to be fused and other differently exposed images from the same HDR scene. The proposed loss functions can guide the proposed ULMEF to learn more reliable information from the HDR scene than existing loss functions which are defined by only using the set of images to be fused. As such, the quality of the fused image is significantly improved. The proposed ULMEF also adopts a multi-scale strategy that includes a multi-scale attention module to effectively preserve the scene depth and local contrast in the fused image. Meanwhile, the proposed ULMEF can be adopted to achieve exposure interpolation and exposure extrapolation. Extensive experiments show that the proposed ULMEF algorithm outperforms state-of-the-art exposure fusion algorithms.
Neural Augmentation Based Panoramic High Dynamic Range Stitching
Sep 07, 2024



Due to saturated regions of inputting low dynamic range (LDR) images and large intensity changes among the LDR images caused by different exposures, it is challenging to produce an information enriched panoramic LDR image without visual artifacts for a high dynamic range (HDR) scene through stitching multiple geometrically synchronized LDR images with different exposures and pairwise overlapping fields of views (OFOVs). Fortunately, the stitching of such images is innately a perfect scenario for the fusion of a physics-driven approach and a data-driven approach due to their OFOVs. Based on this new insight, a novel neural augmentation based panoramic HDR stitching algorithm is proposed in this paper. The physics-driven approach is built up using the OFOVs. Different exposed images of each view are initially generated by using the physics-driven approach, are then refined by a data-driven approach, and are finally used to produce panoramic LDR images with different exposures. All the panoramic LDR images with different exposures are combined together via a multi-scale exposure fusion algorithm to produce the final panoramic LDR image. Experimental results demonstrate the proposed algorithm outperforms existing panoramic stitching algorithms.
Adjacency-hopping de Bruijn Sequences for Non-repetitive Coding
Sep 06, 2023

A special type of cyclic sequences named adjacency-hopping de Bruijn sequences is introduced in this paper. It is theoretically proved the existence of such sequences, and the number of such sequences is derived. These sequences guarantee that all neighboring codes are different while retaining the uniqueness of subsequences, which is a significant characteristic of original de Bruijn sequences in coding and matching. At last, the adjacency-hopping de Bruijn sequences are applied to structured light coding, and a color fringe pattern coded by such a sequence is presented. In summary, the proposed sequences demonstrate significant advantages in structured light coding by virtue of the uniqueness of subsequences and the adjacency-hopping characteristic, and show potential for extension to other fields with similar requirements of non-repetitive coding and efficient matching.
Part Aware Contrastive Learning for Self-Supervised Action Recognition
May 11, 2023In recent years, remarkable results have been achieved in self-supervised action recognition using skeleton sequences with contrastive learning. It has been observed that the semantic distinction of human action features is often represented by local body parts, such as legs or hands, which are advantageous for skeleton-based action recognition. This paper proposes an attention-based contrastive learning framework for skeleton representation learning, called SkeAttnCLR, which integrates local similarity and global features for skeleton-based action representations. To achieve this, a multi-head attention mask module is employed to learn the soft attention mask features from the skeletons, suppressing non-salient local features while accentuating local salient features, thereby bringing similar local features closer in the feature space. Additionally, ample contrastive pairs are generated by expanding contrastive pairs based on salient and non-salient features with global features, which guide the network to learn the semantic representations of the entire skeleton. Therefore, with the attention mask mechanism, SkeAttnCLR learns local features under different data augmentation views. The experiment results demonstrate that the inclusion of local feature similarity significantly enhances skeleton-based action representation. Our proposed SkeAttnCLR outperforms state-of-the-art methods on NTURGB+D, NTU120-RGB+D, and PKU-MMD datasets.
Single Image Deraining via Feature-based Deep Convolutional Neural Network
May 03, 2023It is challenging to remove rain-steaks from a single rainy image because the rain steaks are spatially varying in the rainy image. Although the CNN based methods have reported promising performance recently, there are still some defects, such as data dependency and insufficient interpretation. A single image deraining algorithm based on the combination of data-driven and model-based approaches is proposed. Firstly, an improved weighted guided image filter (iWGIF) is used to extract high-frequency information and learn the rain steaks to avoid interference from other information through the input image. Then, transfering the input image and rain steaks from the image domain to the feature domain adaptively to learn useful features for high-quality image deraining. Finally, networks with attention mechanisms is used to restore high-quality images from the latent features. Experiments show that the proposed algorithm significantly outperforms state-of-the-art methods in terms of both qualitative and quantitative measures.
Single Image Deraining via Rain-Steaks Aware Deep Convolutional Neural Network
Sep 20, 2022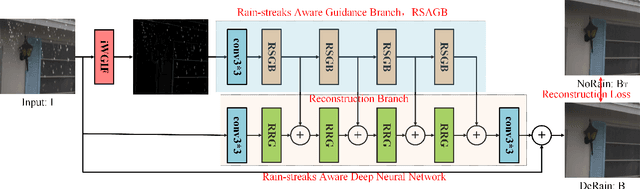
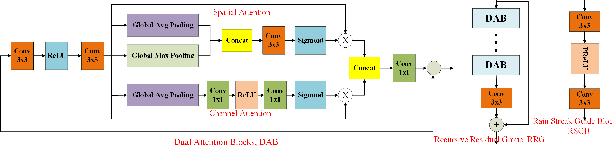
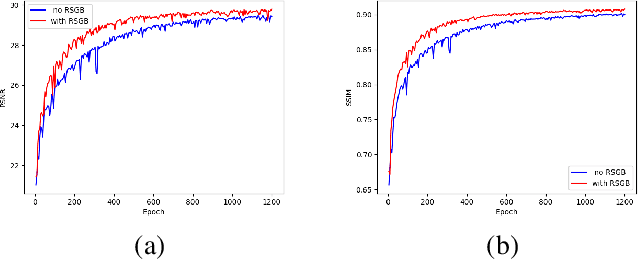

It is challenging to remove rain-steaks from a single rainy image because the rain steaks are spatially varying in the rainy image. This problem is studied in this paper by combining conventional image processing techniques and deep learning based techniques. An improved weighted guided image filter (iWGIF) is proposed to extract high frequency information from a rainy image. The high frequency information mainly includes rain steaks and noise, and it can guide the rain steaks aware deep convolutional neural network (RSADCNN) to pay more attention to rain steaks. The efficiency and explain-ability of RSADNN are improved. Experiments show that the proposed algorithm significantly outperforms state-of-the-art methods on both synthetic and real-world images in terms of both qualitative and quantitative measures. It is useful for autonomous navigation in raining conditions.
Dual-Scale Single Image Dehazing Via Neural Augmentation
Sep 13, 2022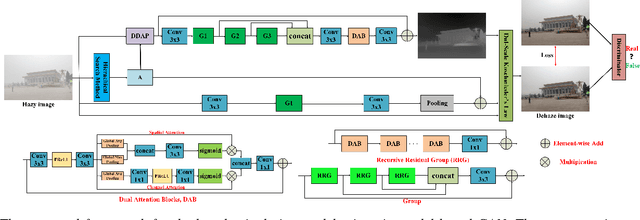

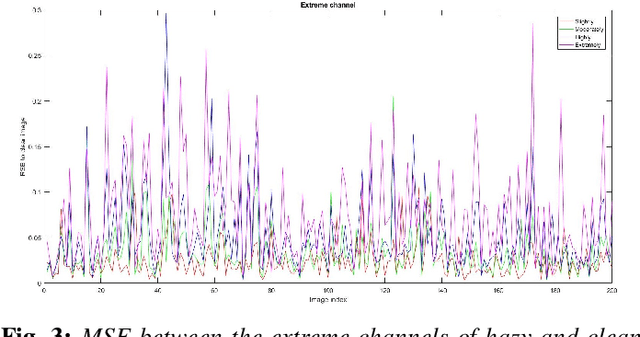

Model-based single image dehazing algorithms restore haze-free images with sharp edges and rich details for real-world hazy images at the expense of low PSNR and SSIM values for synthetic hazy images. Data-driven ones restore haze-free images with high PSNR and SSIM values for synthetic hazy images but with low contrast, and even some remaining haze for real world hazy images. In this paper, a novel single image dehazing algorithm is introduced by combining model-based and data-driven approaches. Both transmission map and atmospheric light are first estimated by the model-based methods, and then refined by dual-scale generative adversarial networks (GANs) based approaches. The resultant algorithm forms a neural augmentation which converges very fast while the corresponding data-driven approach might not converge. Haze-free images are restored by using the estimated transmission map and atmospheric light as well as the Koschmiederlaw. Experimental results indicate that the proposed algorithm can remove haze well from real-world and synthetic hazy images.
SkeletonMAE: Spatial-Temporal Masked Autoencoders for Self-supervised Skeleton Action Recognition
Sep 01, 2022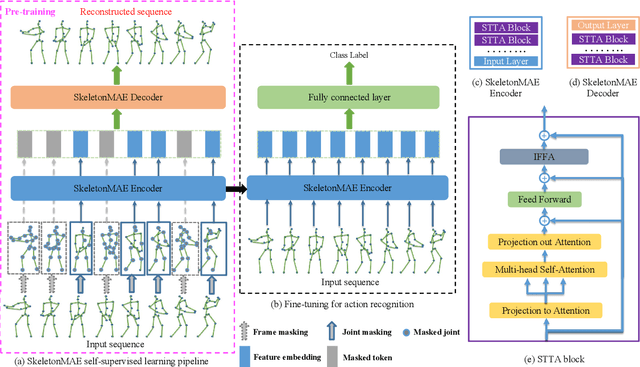
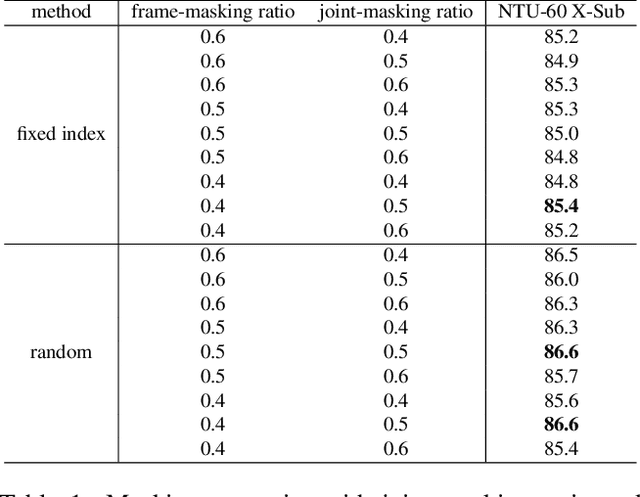
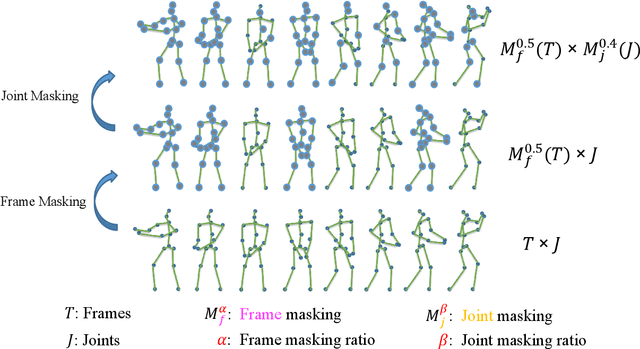
Fully supervised skeleton-based action recognition has achieved great progress with the blooming of deep learning techniques. However, these methods require sufficient labeled data which is not easy to obtain. In contrast, self-supervised skeleton-based action recognition has attracted more attention. With utilizing the unlabeled data, more generalizable features can be learned to alleviate the overfitting problem and reduce the demand of massive labeled training data. Inspired by the MAE, we propose a spatial-temporal masked autoencoder framework for self-supervised 3D skeleton-based action recognition (SkeletonMAE). Following MAE's masking and reconstruction pipeline, we utilize a skeleton based encoder-decoder transformer architecture to reconstruct the masked skeleton sequences. A novel masking strategy, named Spatial-Temporal Masking, is introduced in terms of both joint-level and frame-level for the skeleton sequence. This pre-training strategy makes the encoder output generalizable skeleton features with spatial and temporal dependencies. Given the unmasked skeleton sequence, the encoder is fine-tuned for the action recognition task. Extensive experiments show that our SkeletonMAE achieves remarkable performance and outperforms the state-of-the-art methods on both NTU RGB+D and NTU RGB+D 120 datasets.
Adaptive Weighted Guided Image Filtering for Depth Enhancement in Shape-From-Focus
Jan 18, 2022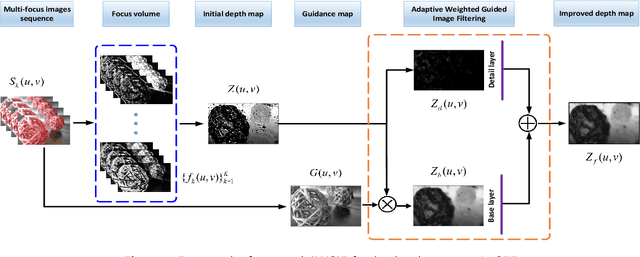



Existing shape from focus (SFF) techniques cannot preserve depth edges and fine structural details from a sequence of multi-focus images. Moreover, noise in the sequence of multi-focus images affects the accuracy of the depth map. In this paper, a novel depth enhancement algorithm for the SFF based on an adaptive weighted guided image filtering (AWGIF) is proposed to address the above issues. The AWGIF is applied to decompose an initial depth map which is estimated by the traditional SFF into a base layer and a detail layer. In order to preserve the edges accurately in the refined depth map, the guidance image is constructed from the multi-focus image sequence, and the coefficient of the AWGIF is utilized to suppress the noise while enhancing the fine depth details. Experiments on real and synthetic objects demonstrate the superiority of the proposed algorithm in terms of anti-noise, and the ability to preserve depth edges and fine structural details compared to existing methods.
Model-Based Single Image Deep Dehazing
Nov 22, 2021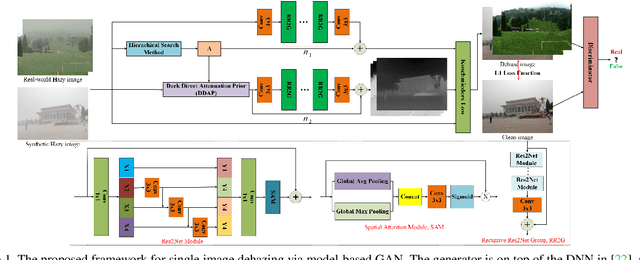

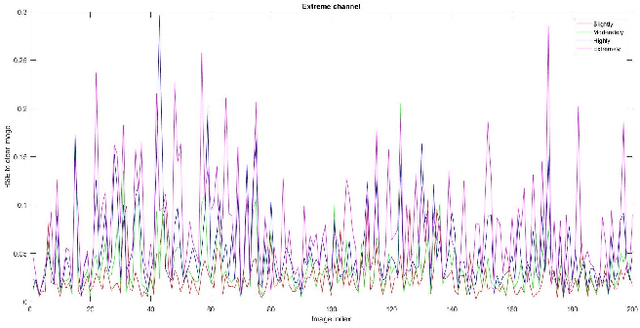

Model-based single image dehazing algorithms restore images with sharp edges and rich details at the expense of low PSNR values. Data-driven ones restore images with high PSNR values but with low contrast, and even some remaining haze. In this paper, a novel single image dehazing algorithm is introduced by fusing model-based and data-driven approaches. Both transmission map and atmospheric light are initialized by the model-based methods, and refined by deep learning approaches which form a neural augmentation. Haze-free images are restored by using the transmission map and atmospheric light. Experimental results indicate that the proposed algorithm can remove haze well from real-world and synthetic hazy images.