 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023



Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/
Adaptive Window Pruning for Efficient Local Motion Deblurring
Jun 25, 2023



Local motion blur commonly occurs in real-world photography due to the mixing between moving objects and stationary backgrounds during exposure. Existing image deblurring methods predominantly focus on global deblurring, inadvertently affecting the sharpness of backgrounds in locally blurred images and wasting unnecessary computation on sharp pixels, especially for high-resolution images. This paper aims to adaptively and efficiently restore high-resolution locally blurred images. We propose a local motion deblurring vision Transformer (LMD-ViT) built on adaptive window pruning Transformer blocks (AdaWPT). To focus deblurring on local regions and reduce computation, AdaWPT prunes unnecessary windows, only allowing the active windows to be involved in the deblurring processes. The pruning operation relies on the blurriness confidence predicted by a confidence predictor that is trained end-to-end using a reconstruction loss with Gumbel-Softmax re-parameterization and a pruning loss guided by annotated blur masks. Our method removes local motion blur effectively without distorting sharp regions, demonstrated by its exceptional perceptual and quantitative improvements (+0.24dB) compared to state-of-the-art methods. In addition, our approach substantially reduces FLOPs by 66% and achieves more than a twofold increase in inference speed compared to Transformer-based deblurring methods. We will make our code and annotated blur masks publicly available.
Explore In-Context Learning for 3D Point Cloud Understanding
Jun 14, 2023



With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation
Jun 13, 2023



Large text-to-image diffusion models have exhibited impressive proficiency in generating high-quality images. However, when applying these models to video domain, ensuring temporal consistency across video frames remains a formidable challenge. This paper proposes a novel zero-shot text-guided video-to-video translation framework to adapt image models to videos. The framework includes two parts: key frame translation and full video translation. The first part uses an adapted diffusion model to generate key frames, with hierarchical cross-frame constraints applied to enforce coherence in shapes, textures and colors. The second part propagates the key frames to other frames with temporal-aware patch matching and frame blending. Our framework achieves global style and local texture temporal consistency at a low cost (without re-training or optimization). The adaptation is compatible with existing image diffusion techniques, allowing our framework to take advantage of them, such as customizing a specific subject with LoRA, and introducing extra spatial guidance with ControlNet. Extensive experimental results demonstrate the effectiveness of our proposed framework over existing methods in rendering high-quality and temporally-coherent videos.
Flare7K++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond
Jun 08, 2023



Artificial lights commonly leave strong lens flare artifacts on the images captured at night, degrading both the visual quality and performance of vision algorithms. Existing flare removal approaches mainly focus on removing daytime flares and fail in nighttime cases. Nighttime flare removal is challenging due to the unique luminance and spectrum of artificial lights, as well as the diverse patterns and image degradation of the flares. The scarcity of the nighttime flare removal dataset constraints the research on this crucial task. In this paper, we introduce Flare7K++, the first comprehensive nighttime flare removal dataset, consisting of 962 real-captured flare images (Flare-R) and 7,000 synthetic flares (Flare7K). Compared to Flare7K, Flare7K++ is particularly effective in eliminating complicated degradation around the light source, which is intractable by using synthetic flares alone. Besides, the previous flare removal pipeline relies on the manual threshold and blur kernel settings to extract light sources, which may fail when the light sources are tiny or not overexposed. To address this issue, we additionally provide the annotations of light sources in Flare7K++ and propose a new end-to-end pipeline to preserve the light source while removing lens flares. Our dataset and pipeline offer a valuable foundation and benchmark for future investigations into nighttime flare removal studies. Extensive experiments demonstrate that Flare7K++ supplements the diversity of existing flare datasets and pushes the frontier of nighttime flare removal towards real-world scenarios.
GP-UNIT: Generative Prior for Versatile Unsupervised Image-to-Image Translation
Jun 07, 2023Recent advances in deep learning have witnessed many successful unsupervised image-to-image translation models that learn correspondences between two visual domains without paired data. However, it is still a great challenge to build robust mappings between various domains especially for those with drastic visual discrepancies. In this paper, we introduce a novel versatile framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), that improves the quality, applicability and controllability of the existing translation models. The key idea of GP-UNIT is to distill the generative prior from pre-trained class-conditional GANs to build coarse-level cross-domain correspondences, and to apply the learned prior to adversarial translations to excavate fine-level correspondences. With the learned multi-level content correspondences, GP-UNIT is able to perform valid translations between both close domains and distant domains. For close domains, GP-UNIT can be conditioned on a parameter to determine the intensity of the content correspondences during translation, allowing users to balance between content and style consistency. For distant domains, semi-supervised learning is explored to guide GP-UNIT to discover accurate semantic correspondences that are hard to learn solely from the appearance. We validate the superiority of GP-UNIT over state-of-the-art translation models in robust, high-quality and diversified translations between various domains through extensive experiments.
Contextual Object Detection with Multimodal Large Language Models
May 29, 2023
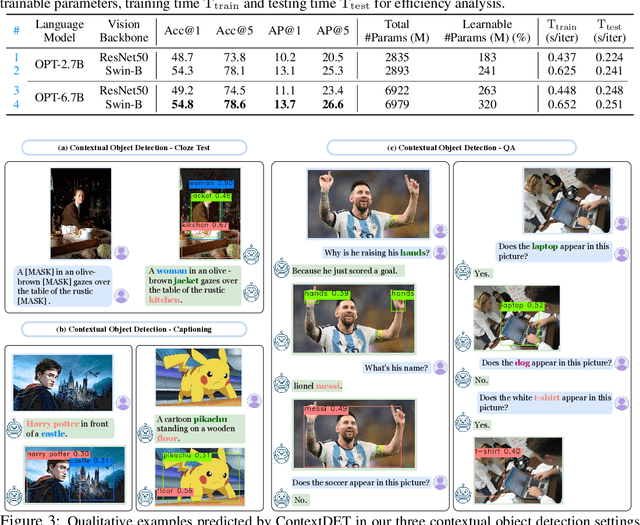


Recent Multimodal Large Language Models (MLLMs) are remarkable in vision-language tasks, such as image captioning and question answering, but lack the essential perception ability, i.e., object detection. In this work, we address this limitation by introducing a novel research problem of contextual object detection -- understanding visible objects within different human-AI interactive contexts. Three representative scenarios are investigated, including the language cloze test, visual captioning, and question answering. Moreover, we present ContextDET, a unified multimodal model that is capable of end-to-end differentiable modeling of visual-language contexts, so as to locate, identify, and associate visual objects with language inputs for human-AI interaction. Our ContextDET involves three key submodels: (i) a visual encoder for extracting visual representations, (ii) a pre-trained LLM for multimodal context decoding, and (iii) a visual decoder for predicting bounding boxes given contextual object words. The new generate-then-detect framework enables us to detect object words within human vocabulary. Extensive experiments show the advantages of ContextDET on our proposed CODE benchmark, open-vocabulary detection, and referring image segmentation. Github: https://github.com/yuhangzang/ContextDET.
Semi-Supervised and Long-Tailed Object Detection with CascadeMatch
May 24, 2023This paper focuses on long-tailed object detection in the semi-supervised learning setting, which poses realistic challenges, but has rarely been studied in the literature. We propose a novel pseudo-labeling-based detector called CascadeMatch. Our detector features a cascade network architecture, which has multi-stage detection heads with progressive confidence thresholds. To avoid manually tuning the thresholds, we design a new adaptive pseudo-label mining mechanism to automatically identify suitable values from data. To mitigate confirmation bias, where a model is negatively reinforced by incorrect pseudo-labels produced by itself, each detection head is trained by the ensemble pseudo-labels of all detection heads. Experiments on two long-tailed datasets, i.e., LVIS and COCO-LT, demonstrate that CascadeMatch surpasses existing state-of-the-art semi-supervised approaches -- across a wide range of detection architectures -- in handling long-tailed object detection. For instance, CascadeMatch outperforms Unbiased Teacher by 1.9 AP Fix on LVIS when using a ResNet50-based Cascade R-CNN structure, and by 1.7 AP Fix when using Sparse R-CNN with a Transformer encoder. We also show that CascadeMatch can even handle the challenging sparsely annotated object detection problem.
MIPI 2023 Challenge on Nighttime Flare Removal: Methods and Results
May 23, 2023



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge including four tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2023. In total, 120 participants were successfully registered, and 11 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/ .
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023



Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.