 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic Framework for Autonomous Materials Computation
Dec 22, 2025



Large Language Models (LLMs) have emerged as powerful tools for accelerating scientific discovery, yet their static knowledge and hallucination issues hinder autonomous research applications. Recent advances integrate LLMs into agentic frameworks, enabling retrieval, reasoning, and tool use for complex scientific workflows. Here, we present a domain-specialized agent designed for reliable automation of first-principles materials computations. By embedding domain expertise, the agent ensures physically coherent multi-step workflows and consistently selects convergent, well-posed parameters, thereby enabling reliable end-to-end computational execution. A new benchmark of diverse computational tasks demonstrates that our system significantly outperforms standalone LLMs in both accuracy and robustness. This work establishes a verifiable foundation for autonomous computational experimentation and represents a key step toward fully automated scientific discovery.
CALM: Consensus-Aware Localized Merging for Multi-Task Learning
Jun 16, 2025Model merging aims to integrate the strengths of multiple fine-tuned models into a unified model while preserving task-specific capabilities. Existing methods, represented by task arithmetic, are typically classified into global- and local-aware methods. However, global-aware methods inevitably cause parameter interference, while local-aware methods struggle to maintain the effectiveness of task-specific details in the merged model. To address these limitations, we propose a Consensus-Aware Localized Merging (CALM) method which incorporates localized information aligned with global task consensus, ensuring its effectiveness post-merging. CALM consists of three key components: (1) class-balanced entropy minimization sampling, providing a more flexible and reliable way to leverage unsupervised data; (2) an efficient-aware framework, selecting a small set of tasks for sequential merging with high scalability; (3) a consensus-aware mask optimization, aligning localized binary masks with global task consensus and merging them conflict-free. Experiments demonstrate the superiority and robustness of our CALM, significantly outperforming existing methods and achieving performance close to traditional MTL.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025



Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025



Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Socratic Questioning: Learn to Self-guide Multimodal Reasoning in the Wild
Jan 07, 2025



Complex visual reasoning remains a key challenge today. Typically, the challenge is tackled using methodologies such as Chain of Thought (COT) and visual instruction tuning. However, how to organically combine these two methodologies for greater success remains unexplored. Also, issues like hallucinations and high training cost still need to be addressed. In this work, we devise an innovative multi-round training and reasoning framework suitable for lightweight Multimodal Large Language Models (MLLMs). Our self-questioning approach heuristically guides MLLMs to focus on visual clues relevant to the target problem, reducing hallucinations and enhancing the model's ability to describe fine-grained image details. This ultimately enables the model to perform well in complex visual reasoning and question-answering tasks. We have named this framework Socratic Questioning(SQ). To facilitate future research, we create a multimodal mini-dataset named CapQA, which includes 1k images of fine-grained activities, for visual instruction tuning and evaluation, our proposed SQ method leads to a 31.2% improvement in the hallucination score. Our extensive experiments on various benchmarks demonstrate SQ's remarkable capabilities in heuristic self-questioning, zero-shot visual reasoning and hallucination mitigation. Our model and code will be publicly available.
Physics Reasoner: Knowledge-Augmented Reasoning for Solving Physics Problems with Large Language Models
Dec 18, 2024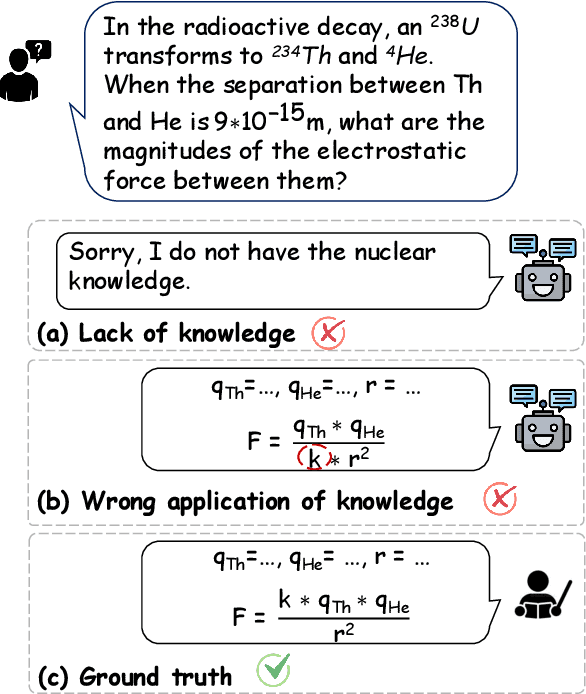
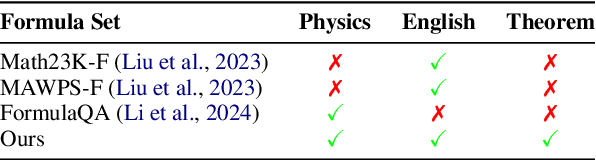
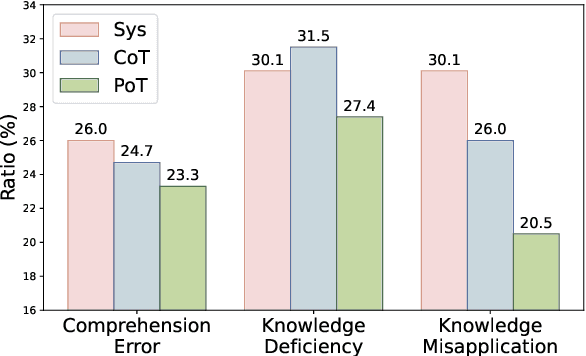
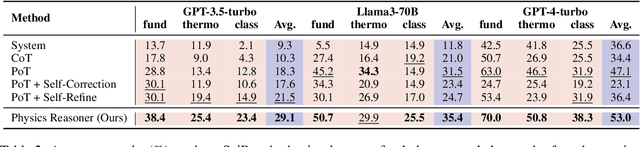
Physics problems constitute a significant aspect of reasoning, necessitating complicated reasoning ability and abundant physics knowledge. However, existing large language models (LLMs) frequently fail due to a lack of knowledge or incorrect knowledge application. To mitigate these issues, we propose Physics Reasoner, a knowledge-augmented framework to solve physics problems with LLMs. Specifically, the proposed framework constructs a comprehensive formula set to provide explicit physics knowledge and utilizes checklists containing detailed instructions to guide effective knowledge application. Namely, given a physics problem, Physics Reasoner solves it through three stages: problem analysis, formula retrieval, and guided reasoning. During the process, checklists are employed to enhance LLMs' self-improvement in the analysis and reasoning stages. Empirically, Physics Reasoner mitigates the issues of insufficient knowledge and incorrect application, achieving state-of-the-art performance on SciBench with an average accuracy improvement of 5.8%.
Abstraction-of-Thought Makes Language Models Better Reasoners
Jun 18, 2024



Abstract reasoning, the ability to reason from the abstract essence of a problem, serves as a key to generalization in human reasoning. However, eliciting language models to perform reasoning with abstraction remains unexplored. This paper seeks to bridge this gap by introducing a novel structured reasoning format called Abstraction-of-Thought (AoT). The uniqueness of AoT lies in its explicit requirement for varying levels of abstraction within the reasoning process. This approach could elicit language models to first contemplate on the abstract level before incorporating concrete details, which is overlooked by the prevailing step-by-step Chain-of-Thought (CoT) method. To align models with the AoT format, we present AoT Collection, a generic finetuning dataset consisting of 348k high-quality samples with AoT reasoning processes, collected via an automated and scalable pipeline. We finetune a wide range of language models with AoT Collection and conduct extensive evaluations on 23 unseen tasks from the challenging benchmark Big-Bench Hard. Experimental results indicate that models aligned to AoT reasoning format substantially outperform those aligned to CoT in many reasoning tasks.
Balancing Similarity and Complementarity for Federated Learning
May 16, 2024



In mobile and IoT systems, Federated Learning (FL) is increasingly important for effectively using data while maintaining user privacy. One key challenge in FL is managing statistical heterogeneity, such as non-i.i.d. data, arising from numerous clients and diverse data sources. This requires strategic cooperation, often with clients having similar characteristics. However, we are interested in a fundamental question: does achieving optimal cooperation necessarily entail cooperating with the most similar clients? Typically, significant model performance improvements are often realized not by partnering with the most similar models, but through leveraging complementary data. Our theoretical and empirical analyses suggest that optimal cooperation is achieved by enhancing complementarity in feature distribution while restricting the disparity in the correlation between features and targets. Accordingly, we introduce a novel framework, \texttt{FedSaC}, which balances similarity and complementarity in FL cooperation. Our framework aims to approximate an optimal cooperation network for each client by optimizing a weighted sum of model similarity and feature complementarity. The strength of \texttt{FedSaC} lies in its adaptability to various levels of data heterogeneity and multimodal scenarios. Our comprehensive unimodal and multimodal experiments demonstrate that \texttt{FedSaC} markedly surpasses other state-of-the-art FL methods.
CLOMO: Counterfactual Logical Modification with Large Language Models
Nov 30, 2023



In this study, we delve into the realm of counterfactual reasoning capabilities of large language models (LLMs). Our primary objective is to cultivate the counterfactual thought processes within LLMs and rigorously assess these processes for their validity. Specifically, we introduce a novel task, Counterfactual Logical Modification (CLOMO), and a high-quality human-annotated benchmark. In this task, LLMs must adeptly alter a given argumentative text to uphold a predetermined logical relationship. To effectively evaluate a generation model's counterfactual capabilities, we propose an innovative evaluation metric, the LogicAware Counterfactual Score to directly evaluate the natural language output of LLMs instead of modeling the task as a multiple-choice problem. Analysis shows that the proposed automatic metric aligns well with human preference. Our experimental results show that while LLMs demonstrate a notable capacity for logical counterfactual thinking, there remains a discernible gap between their current abilities and human performance.
A Closer Look at the Self-Verification Abilities of Large Language Models in Logical Reasoning
Nov 14, 2023Logical reasoning has been an ongoing pursuit in the field of AI. Despite significant advancements made by large language models (LLMs), they still struggle with complex logical reasoning problems. To enhance reasoning performance, one promising direction is scalable oversight, which requires LLMs to identify their own errors and then improve by themselves. Various self-verification methods have been proposed in pursuit of this goal. Nevertheless, whether existing models understand their own errors well is still under investigation. In this paper, we take a closer look at the self-verification abilities of LLMs in the context of logical reasoning, focusing on their ability to identify logical fallacies accurately. We introduce a dataset, FALLACIES, containing 232 types of reasoning fallacies categorized in a hierarchical taxonomy. By conducting exhaustive experiments on FALLACIES, we obtain comprehensive and detailed analyses of a series of models on their verification abilities. Our main findings suggest that existing LLMs could struggle to identify fallacious reasoning steps accurately and may fall short of guaranteeing the validity of self-verification methods. Drawing from these observations, we offer suggestions for future research and practical applications of self-verification methods.