 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Feasibility of ChatGPT for Event Extraction
Mar 09, 2023



Event extraction is a fundamental task in natural language processing that involves identifying and extracting information about events mentioned in text. However, it is a challenging task due to the lack of annotated data, which is expensive and time-consuming to obtain. The emergence of large language models (LLMs) such as ChatGPT provides an opportunity to solve language tasks with simple prompts without the need for task-specific datasets and fine-tuning. While ChatGPT has demonstrated impressive results in tasks like machine translation, text summarization, and question answering, it presents challenges when used for complex tasks like event extraction. Unlike other tasks, event extraction requires the model to be provided with a complex set of instructions defining all event types and their schemas. To explore the feasibility of ChatGPT for event extraction and the challenges it poses, we conducted a series of experiments. Our results show that ChatGPT has, on average, only 51.04% of the performance of a task-specific model such as EEQA in long-tail and complex scenarios. Our usability testing experiments indicate that ChatGPT is not robust enough, and continuous refinement of the prompt does not lead to stable performance improvements, which can result in a poor user experience. Besides, ChatGPT is highly sensitive to different prompt styles.
Mask-then-Fill: A Flexible and Effective Data Augmentation Framework for Event Extraction
Jan 06, 2023



We present Mask-then-Fill, a flexible and effective data augmentation framework for event extraction. Our approach allows for more flexible manipulation of text and thus can generate more diverse data while keeping the original event structure unchanged as much as possible. Specifically, it first randomly masks out an adjunct sentence fragment and then infills a variable-length text span with a fine-tuned infilling model. The main advantage lies in that it can replace a fragment of arbitrary length in the text with another fragment of variable length, compared to the existing methods which can only replace a single word or a fixed-length fragment. On trigger and argument extraction tasks, the proposed framework is more effective than baseline methods and it demonstrates particularly strong results in the low-resource setting. Our further analysis shows that it achieves a good balance between diversity and distributional similarity.
A Generative Approach for Script Event Prediction via Contrastive Fine-tuning
Dec 09, 2022



Script event prediction aims to predict the subsequent event given the context. This requires the capability to infer the correlations between events. Recent works have attempted to improve event correlation reasoning by using pretrained language models and incorporating external knowledge~(e.g., discourse relations). Though promising results have been achieved, some challenges still remain. First, the pretrained language models adopted by current works ignore event-level knowledge, resulting in an inability to capture the correlations between events well. Second, modeling correlations between events with discourse relations is limited because it can only capture explicit correlations between events with discourse markers, and cannot capture many implicit correlations. To this end, we propose a novel generative approach for this task, in which a pretrained language model is fine-tuned with an event-centric pretraining objective and predicts the next event within a generative paradigm. Specifically, we first introduce a novel event-level blank infilling strategy as the learning objective to inject event-level knowledge into the pretrained language model, and then design a likelihood-based contrastive loss for fine-tuning the generative model. Instead of using an additional prediction layer, we perform prediction by using sequence likelihoods generated by the generative model. Our approach models correlations between events in a soft way without any external knowledge. The likelihood-based prediction eliminates the need to use additional networks to make predictions and is somewhat interpretable since it scores each word in the event. Experimental results on the multi-choice narrative cloze~(MCNC) task demonstrate that our approach achieves better results than other state-of-the-art baselines. Our code will be available at https://github.com/zhufq00/mcnc.
FolkScope: Intention Knowledge Graph Construction for Discovering E-commerce Commonsense
Nov 15, 2022



As stated by Oren Etzioni, ``commonsense is the dark matter of artificial intelligence''. In e-commerce, understanding users' needs or intentions requires substantial commonsense knowledge, e.g., ``A user bought an iPhone and a compatible case because the user wanted the phone to be protected''. In this paper, we present FolkScope, an intention knowledge graph construction framework, to reveal the structure of humans' minds about purchasing items on e-commerce platforms such as Amazon. As commonsense knowledge is usually ineffable and not expressed explicitly, it is challenging to perform any kind of information extraction. Thus, we propose a new approach that leverages the generation power of large-scale language models and human-in-the-loop annotations to semi-automatically construct the knowledge graph. We annotate a large amount of assertions for both plausibility and typicality of an intention that can explain a purchasing or co-purchasing behavior, where the intention can be an open reason or a predicate falling into one of 18 categories aligning with ConceptNet, e.g., IsA, MadeOf, UsedFor, etc. Then we populate the annotated information to all automatically generated ones, and further structurize the assertions using pattern mining and conceptualization to form more condensed and abstractive knowledge. We evaluate our knowledge graph using both intrinsic quality measures and a downstream application, i.e., recommendation. The comprehensive study shows that our knowledge graph can well model e-commerce commonsense knowledge and can have many potential applications.
Title2Event: Benchmarking Open Event Extraction with a Large-scale Chinese Title Dataset
Nov 02, 2022



Event extraction (EE) is crucial to downstream tasks such as new aggregation and event knowledge graph construction. Most existing EE datasets manually define fixed event types and design specific schema for each of them, failing to cover diverse events emerging from the online text. Moreover, news titles, an important source of event mentions, have not gained enough attention in current EE research. In this paper, We present Title2Event, a large-scale sentence-level dataset benchmarking Open Event Extraction without restricting event types. Title2Event contains more than 42,000 news titles in 34 topics collected from Chinese web pages. To the best of our knowledge, it is currently the largest manually-annotated Chinese dataset for open event extraction. We further conduct experiments on Title2Event with different models and show that the characteristics of titles make it challenging for event extraction, addressing the significance of advanced study on this problem. The dataset and baseline codes are available at https://open-event-hub.github.io/title2event.
An Empirical Revisiting of Linguistic Knowledge Fusion in Language Understanding Tasks
Oct 24, 2022



Though linguistic knowledge emerges during large-scale language model pretraining, recent work attempt to explicitly incorporate human-defined linguistic priors into task-specific fine-tuning. Infusing language models with syntactic or semantic knowledge from parsers has shown improvements on many language understanding tasks. To further investigate the effectiveness of structural linguistic priors, we conduct empirical study of replacing parsed graphs or trees with trivial ones (rarely carrying linguistic knowledge e.g., balanced tree) for tasks in the GLUE benchmark. Encoding with trivial graphs achieves competitive or even better performance in fully-supervised and few-shot settings. It reveals that the gains might not be significantly attributed to explicit linguistic priors but rather to more feature interactions brought by fusion layers. Hence we call for attention to using trivial graphs as necessary baselines to design advanced knowledge fusion methods in the future.
Improving Event Representation via Simultaneous Weakly Supervised Contrastive Learning and Clustering
Mar 15, 2022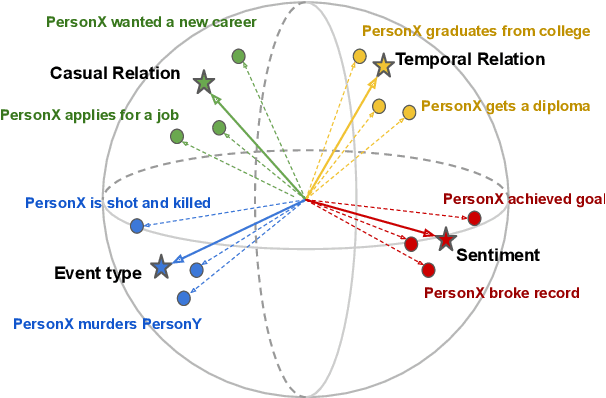
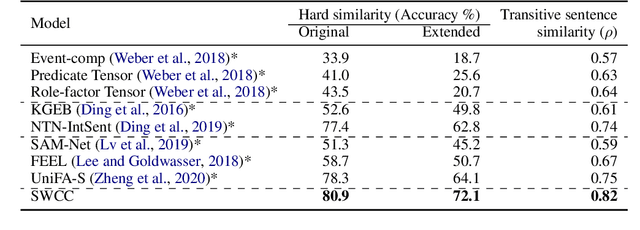
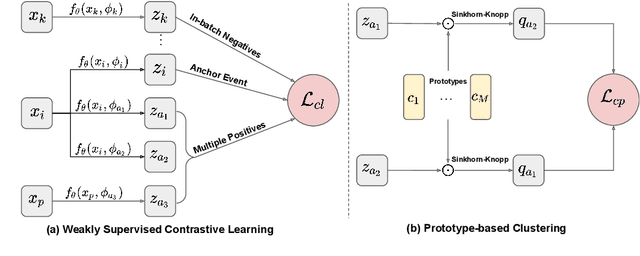
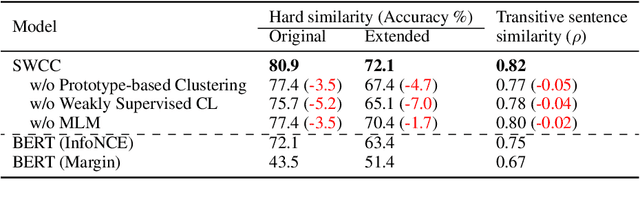
Representations of events described in text are important for various tasks. In this work, we present SWCC: a Simultaneous Weakly supervised Contrastive learning and Clustering framework for event representation learning. SWCC learns event representations by making better use of co-occurrence information of events. Specifically, we introduce a weakly supervised contrastive learning method that allows us to consider multiple positives and multiple negatives, and a prototype-based clustering method that avoids semantically related events being pulled apart. For model training, SWCC learns representations by simultaneously performing weakly supervised contrastive learning and prototype-based clustering. Experimental results show that SWCC outperforms other baselines on Hard Similarity and Transitive Sentence Similarity tasks. In addition, a thorough analysis of the prototype-based clustering method demonstrates that the learned prototype vectors are able to implicitly capture various relations between events.
CoCoLM: COmplex COmmonsense Enhanced Language Model
Dec 31, 2020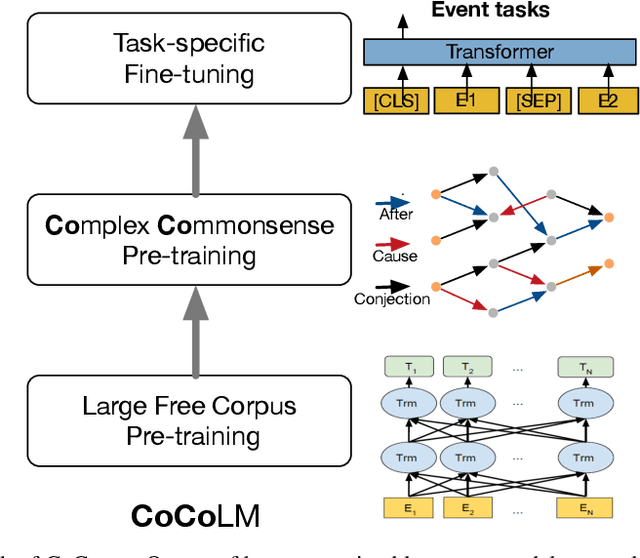

Large-scale pre-trained language models have demonstrated strong knowledge representation ability. However, recent studies suggest that even though these giant models contains rich simple commonsense knowledge (e.g., bird can fly and fish can swim.), they often struggle with the complex commonsense knowledge that involves multiple eventualities (verb-centric phrases, e.g., identifying the relationship between ``Jim yells at Bob'' and ``Bob is upset'').To address this problem, in this paper, we propose to help pre-trained language models better incorporate complex commonsense knowledge. Different from existing fine-tuning approaches, we do not focus on a specific task and propose a general language model named CoCoLM. Through the careful training over a large-scale eventuality knowledge graphs ASER, we successfully teach pre-trained language models (i.e., BERT and RoBERTa) rich complex commonsense knowledge among eventualities. Experiments on multiple downstream commonsense tasks that requires the correct understanding of eventualities demonstrate the effectiveness of CoCoLM.
When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models
Oct 10, 2020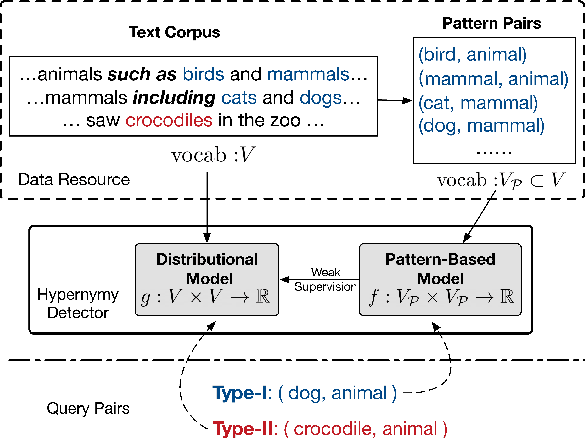
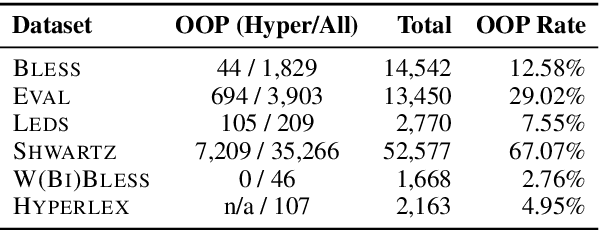
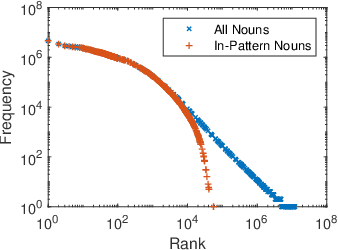
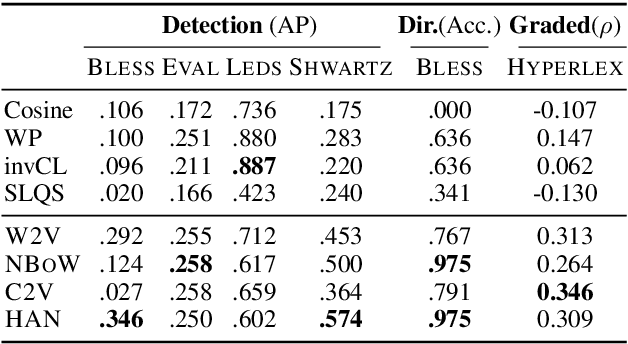
We address hypernymy detection, i.e., whether an is-a relationship exists between words (x, y), with the help of large textual corpora. Most conventional approaches to this task have been categorized to be either pattern-based or distributional. Recent studies suggest that pattern-based ones are superior, if large-scale Hearst pairs are extracted and fed, with the sparsity of unseen (x, y) pairs relieved. However, they become invalid in some specific sparsity cases, where x or y is not involved in any pattern. For the first time, this paper quantifies the non-negligible existence of those specific cases. We also demonstrate that distributional methods are ideal to make up for pattern-based ones in such cases. We devise a complementary framework, under which a pattern-based and a distributional model collaborate seamlessly in cases which they each prefer. On several benchmark datasets, our framework achieves competitive improvements and the case study shows its better interpretability.
Enriching Large-Scale Eventuality Knowledge Graph with Entailment Relations
Jun 21, 2020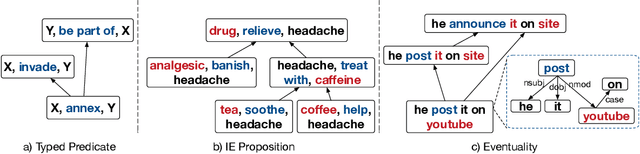
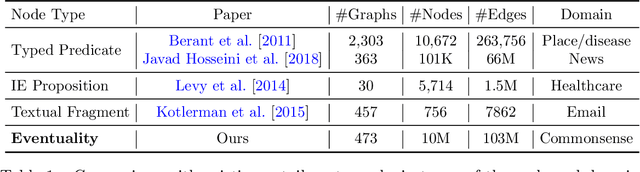
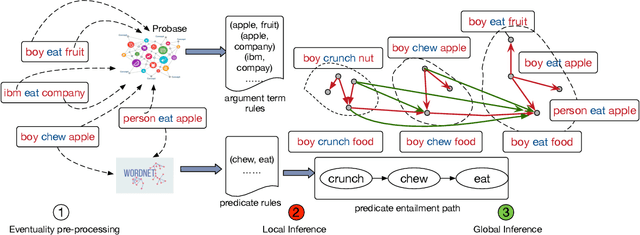

Computational and cognitive studies suggest that the abstraction of eventualities (activities, states, and events) is crucial for humans to understand daily eventualities. In this paper, we propose a scalable approach to model the entailment relations between eventualities ("eat an apple'' entails ''eat fruit''). As a result, we construct a large-scale eventuality entailment graph (EEG), which has 10 million eventuality nodes and 103 million entailment edges. Detailed experiments and analysis demonstrate the effectiveness of the proposed approach and quality of the resulting knowledge graph. Our datasets and code are available at https://github.com/HKUST-KnowComp/ASER-EEG.