 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Navigator: Search for a Good Adaptation Policy for Few-shot Learning
Sep 13, 2021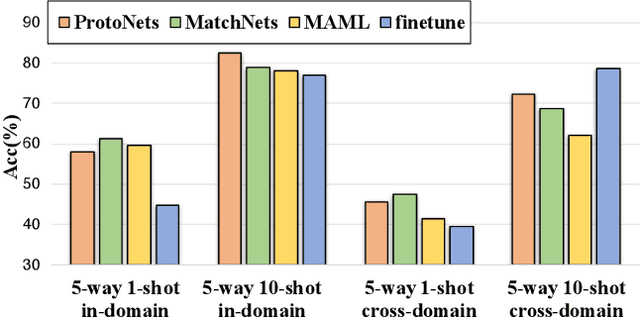
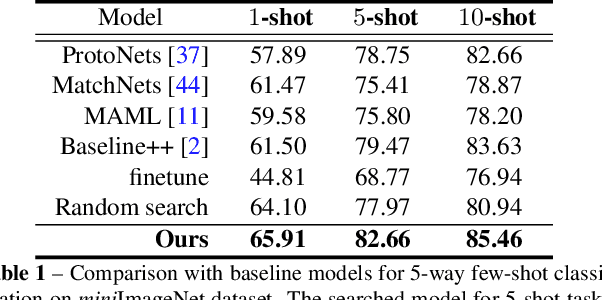
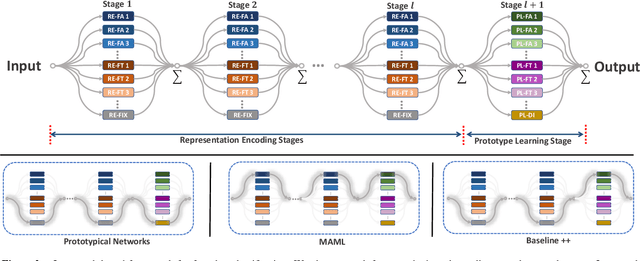
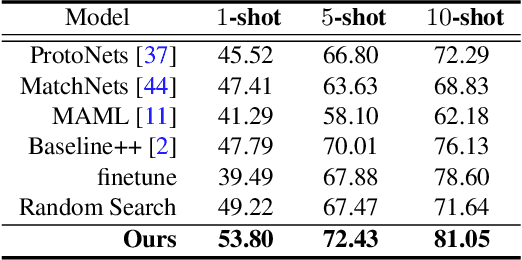
Few-shot learning aims to adapt knowledge learned from previous tasks to novel tasks with only a limited amount of labeled data. Research literature on few-shot learning exhibits great diversity, while different algorithms often excel at different few-shot learning scenarios. It is therefore tricky to decide which learning strategies to use under different task conditions. Inspired by the recent success in Automated Machine Learning literature (AutoML), in this paper, we present Meta Navigator, a framework that attempts to solve the aforementioned limitation in few-shot learning by seeking a higher-level strategy and proffer to automate the selection from various few-shot learning designs. The goal of our work is to search for good parameter adaptation policies that are applied to different stages in the network for few-shot classification. We present a search space that covers many popular few-shot learning algorithms in the literature and develop a differentiable searching and decoding algorithm based on meta-learning that supports gradient-based optimization. We demonstrate the effectiveness of our searching-based method on multiple benchmark datasets. Extensive experiments show that our approach significantly outperforms baselines and demonstrates performance advantages over many state-of-the-art methods. Code and models will be made publicly available.
Memory Based Video Scene Parsing
Sep 01, 2021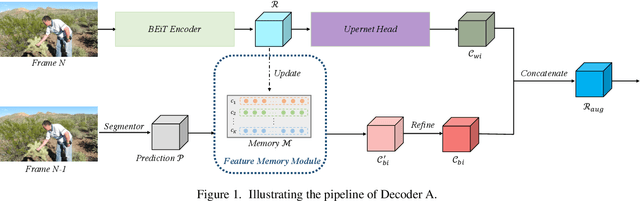
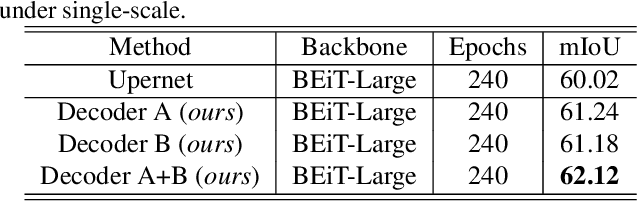
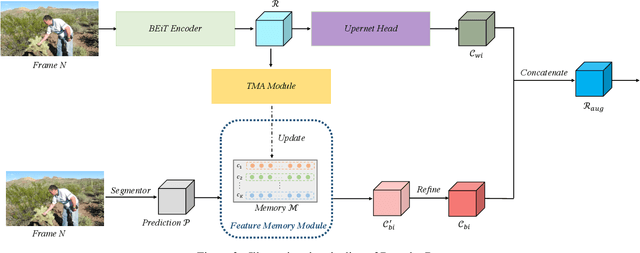
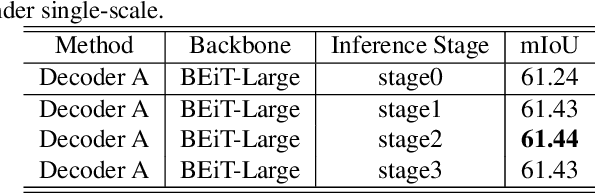
Video scene parsing is a long-standing challenging task in computer vision, aiming to assign pre-defined semantic labels to pixels of all frames in a given video. Compared with image semantic segmentation, this task pays more attention on studying how to adopt the temporal information to obtain higher predictive accuracy. In this report, we introduce our solution for the 1st Video Scene Parsing in the Wild Challenge, which achieves a mIoU of 57.44 and obtained the 2nd place (our team name is CharlesBLWX).
Mining Contextual Information Beyond Image for Semantic Segmentation
Aug 26, 2021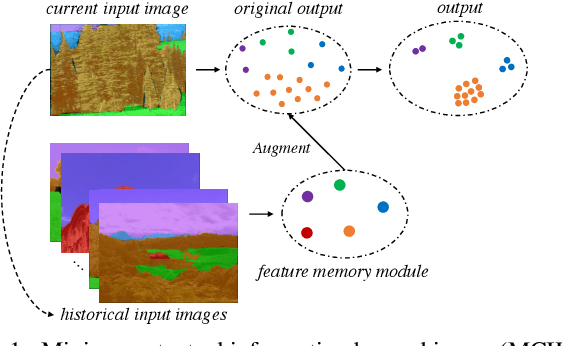

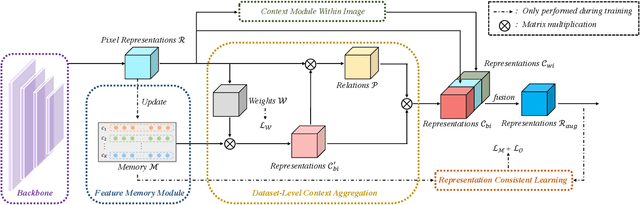

This paper studies the context aggregation problem in semantic image segmentation. The existing researches focus on improving the pixel representations by aggregating the contextual information within individual images. Though impressive, these methods neglect the significance of the representations of the pixels of the corresponding class beyond the input image. To address this, this paper proposes to mine the contextual information beyond individual images to further augment the pixel representations. We first set up a feature memory module, which is updated dynamically during training, to store the dataset-level representations of various categories. Then, we learn class probability distribution of each pixel representation under the supervision of the ground-truth segmentation. At last, the representation of each pixel is augmented by aggregating the dataset-level representations based on the corresponding class probability distribution. Furthermore, by utilizing the stored dataset-level representations, we also propose a representation consistent learning strategy to make the classification head better address intra-class compactness and inter-class dispersion. The proposed method could be effortlessly incorporated into existing segmentation frameworks (e.g., FCN, PSPNet, OCRNet and DeepLabV3) and brings consistent performance improvements. Mining contextual information beyond image allows us to report state-of-the-art performance on various benchmarks: ADE20K, LIP, Cityscapes and COCO-Stuff.
Cross-category Video Highlight Detection via Set-based Learning
Aug 26, 2021
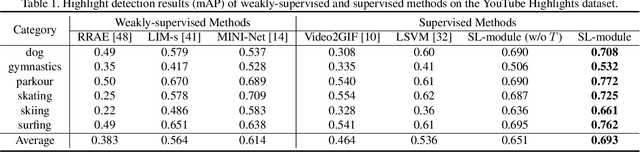
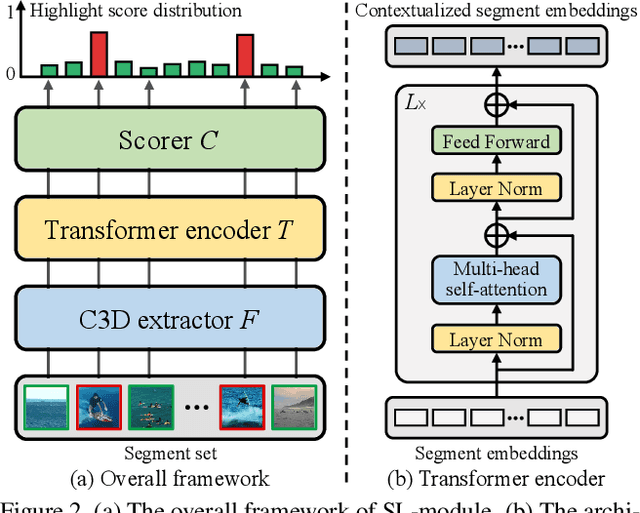
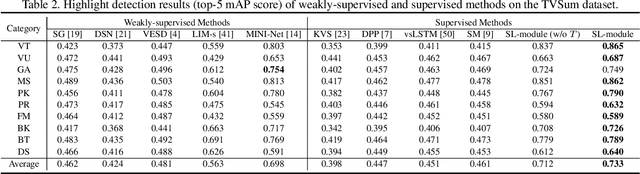
Autonomous highlight detection is crucial for enhancing the efficiency of video browsing on social media platforms. To attain this goal in a data-driven way, one may often face the situation where highlight annotations are not available on the target video category used in practice, while the supervision on another video category (named as source video category) is achievable. In such a situation, one can derive an effective highlight detector on target video category by transferring the highlight knowledge acquired from source video category to the target one. We call this problem cross-category video highlight detection, which has been rarely studied in previous works. For tackling such practical problem, we propose a Dual-Learner-based Video Highlight Detection (DL-VHD) framework. Under this framework, we first design a Set-based Learning module (SL-module) to improve the conventional pair-based learning by assessing the highlight extent of a video segment under a broader context. Based on such learning manner, we introduce two different learners to acquire the basic distinction of target category videos and the characteristics of highlight moments on source video category, respectively. These two types of highlight knowledge are further consolidated via knowledge distillation. Extensive experiments on three benchmark datasets demonstrate the superiority of the proposed SL-module, and the DL-VHD method outperforms five typical Unsupervised Domain Adaptation (UDA) algorithms on various cross-category highlight detection tasks. Our code is available at https://github.com/ChrisAllenMing/Cross_Category_Video_Highlight .
MT-ORL: Multi-Task Occlusion Relationship Learning
Aug 18, 2021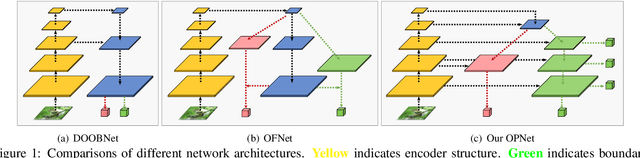
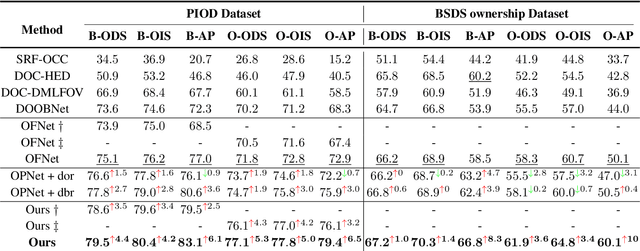
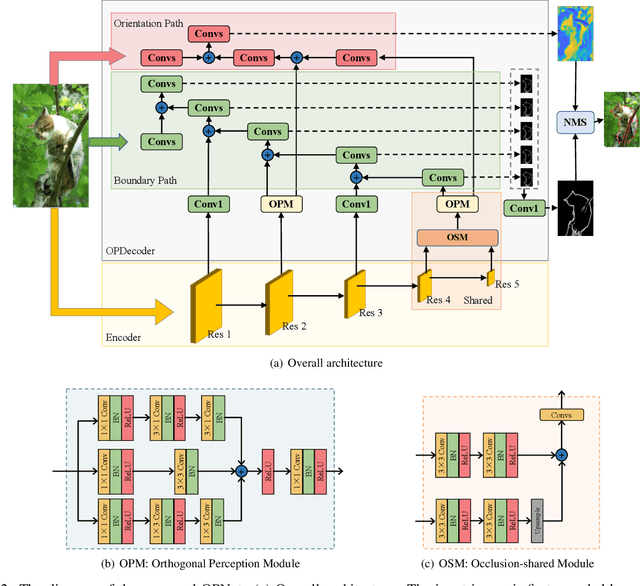
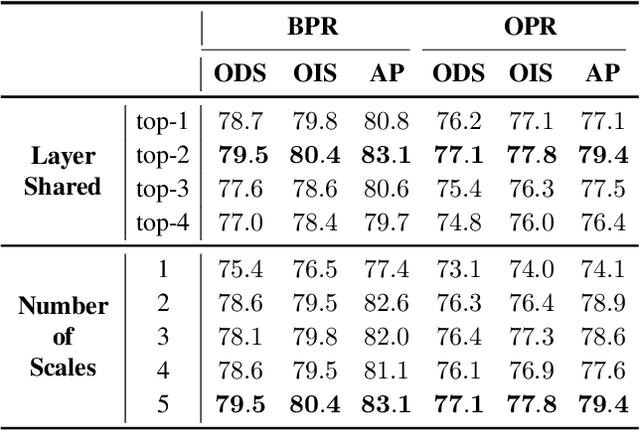
Retrieving occlusion relation among objects in a single image is challenging due to sparsity of boundaries in image. We observe two key issues in existing works: firstly, lack of an architecture which can exploit the limited amount of coupling in the decoder stage between the two subtasks, namely occlusion boundary extraction and occlusion orientation prediction, and secondly, improper representation of occlusion orientation. In this paper, we propose a novel architecture called Occlusion-shared and Path-separated Network (OPNet), which solves the first issue by exploiting rich occlusion cues in shared high-level features and structured spatial information in task-specific low-level features. We then design a simple but effective orthogonal occlusion representation (OOR) to tackle the second issue. Our method surpasses the state-of-the-art methods by 6.1%/8.3% Boundary-AP and 6.5%/10% Orientation-AP on standard PIOD/BSDS ownership datasets. Code is available at https://github.com/fengpanhe/MT-ORL.
Unifying Nonlocal Blocks for Neural Networks
Aug 17, 2021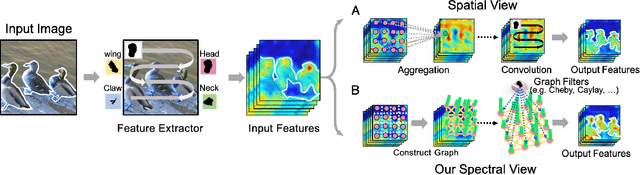

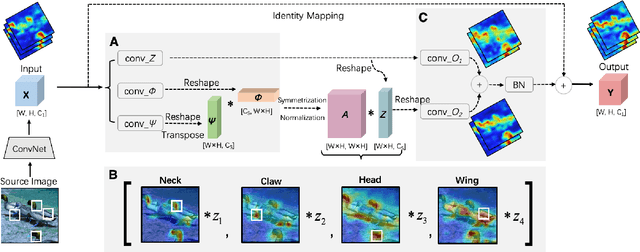
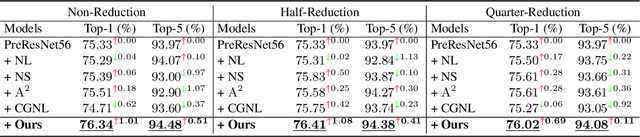
The nonlocal-based blocks are designed for capturing long-range spatial-temporal dependencies in computer vision tasks. Although having shown excellent performance, they still lack the mechanism to encode the rich, structured information among elements in an image or video. In this paper, to theoretically analyze the property of these nonlocal-based blocks, we provide a new perspective to interpret them, where we view them as a set of graph filters generated on a fully-connected graph. Specifically, when choosing the Chebyshev graph filter, a unified formulation can be derived for explaining and analyzing the existing nonlocal-based blocks (e.g., nonlocal block, nonlocal stage, double attention block). Furthermore, by concerning the property of spectral, we propose an efficient and robust spectral nonlocal block, which can be more robust and flexible to catch long-range dependencies when inserted into deep neural networks than the existing nonlocal blocks. Experimental results demonstrate the clear-cut improvements and practical applicabilities of our method on image classification, action recognition, semantic segmentation, and person re-identification tasks.
Recovering the Unbiased Scene Graphs from the Biased Ones
Jul 05, 2021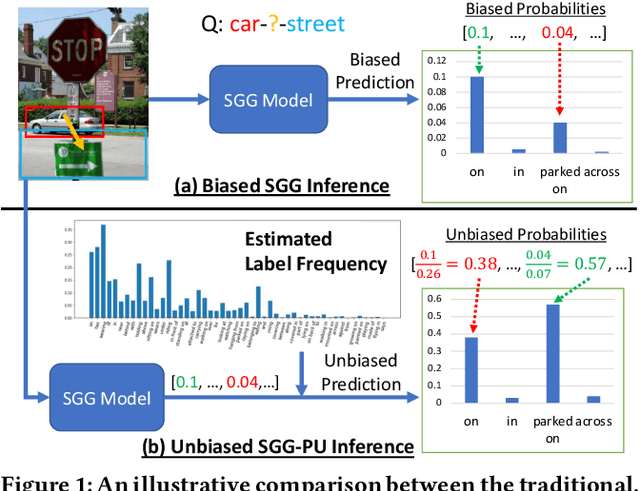
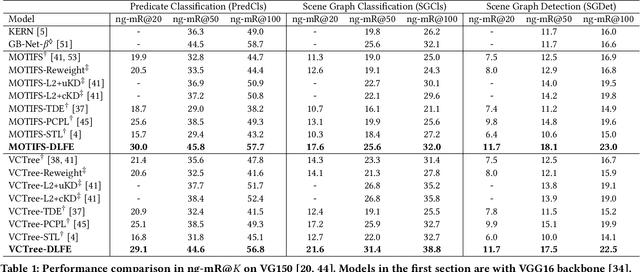
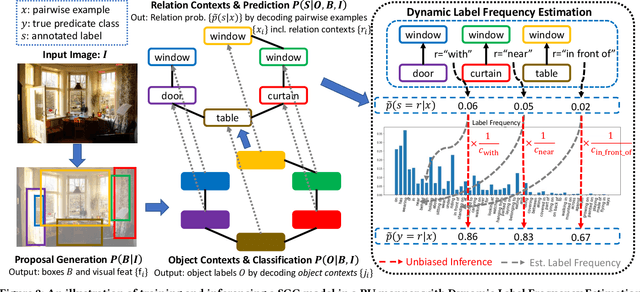
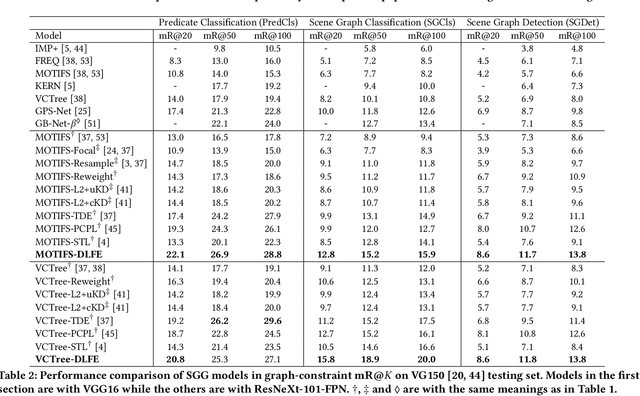
Given input images, scene graph generation (SGG) aims to produce comprehensive, graphical representations describing visual relationships among salient objects. Recently, more efforts have been paid to the long tail problem in SGG; however, the imbalance in the fraction of missing labels of different classes, or reporting bias, exacerbating the long tail is rarely considered and cannot be solved by the existing debiasing methods. In this paper we show that, due to the missing labels, SGG can be viewed as a "Learning from Positive and Unlabeled data" (PU learning) problem, where the reporting bias can be removed by recovering the unbiased probabilities from the biased ones by utilizing label frequencies, i.e., the per-class fraction of labeled, positive examples in all the positive examples. To obtain accurate label frequency estimates, we propose Dynamic Label Frequency Estimation (DLFE) to take advantage of training-time data augmentation and average over multiple training iterations to introduce more valid examples. Extensive experiments show that DLFE is more effective in estimating label frequencies than a naive variant of the traditional estimate, and DLFE significantly alleviates the long tail and achieves state-of-the-art debiasing performance on the VG dataset. We also show qualitatively that SGG models with DLFE produce prominently more balanced and unbiased scene graphs.
How Incomplete is Contrastive Learning? An Inter-intra Variant Dual Representation Method for Self-supervised Video Recognition
Jul 05, 2021
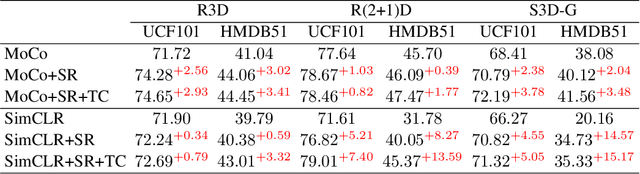
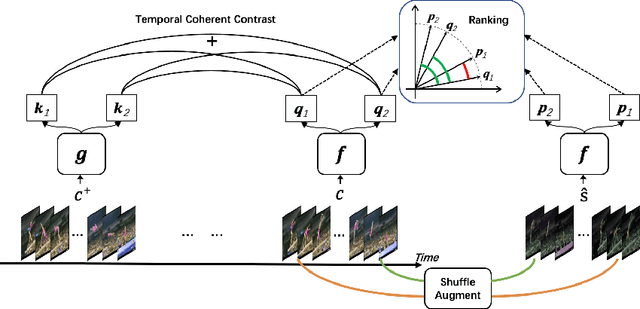
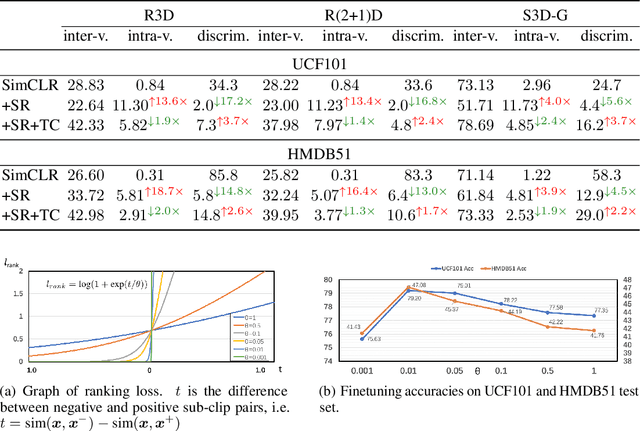
Contrastive learning applied to self-supervised representation learning has seen a resurgence in deep models. In this paper, we find that existing contrastive learning based solutions for self-supervised video recognition focus on inter-variance encoding but ignore the intra-variance existing in clips within the same video. We thus propose to learn dual representations for each clip which (\romannumeral 1) encode intra-variance through a shuffle-rank pretext task; (\romannumeral 2) encode inter-variance through a temporal coherent contrastive loss. Experiment results show that our method plays an essential role in balancing inter and intra variances and brings consistent performance gains on multiple backbones and contrastive learning frameworks. Integrated with SimCLR and pretrained on Kinetics-400, our method achieves $\textbf{82.0\%}$ and $\textbf{51.2\%}$ downstream classification accuracy on UCF101 and HMDB51 test sets respectively and $\textbf{46.1\%}$ video retrieval accuracy on UCF101, outperforming both pretext-task based and contrastive learning based counterparts.
Rethinking Re-Sampling in Imbalanced Semi-Supervised Learning
Jun 01, 2021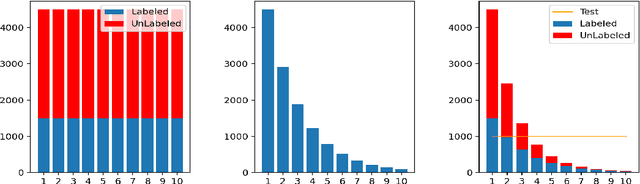
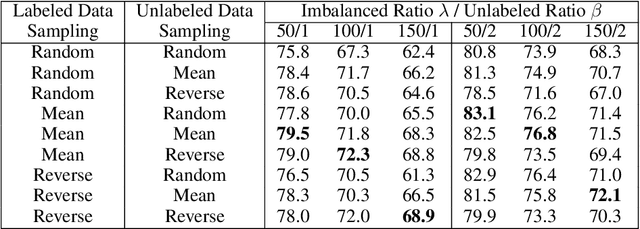
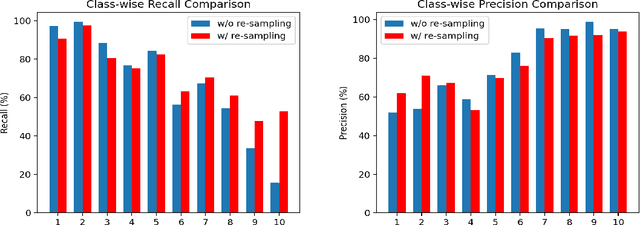
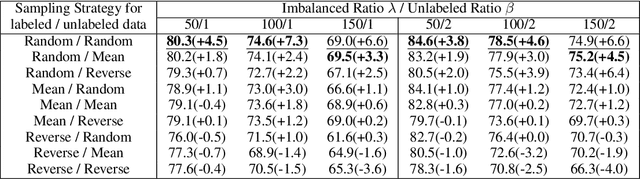
Semi-Supervised Learning (SSL) has shown its strong ability in utilizing unlabeled data when labeled data is scarce. However, most SSL algorithms work under the assumption that the class distributions are balanced in both training and test sets. In this work, we consider the problem of SSL on class-imbalanced data, which better reflects real-world situations but has only received limited attention so far. In particular, we decouple the training of the representation and the classifier, and systematically investigate the effects of different data re-sampling techniques when training the whole network including a classifier as well as fine-tuning the feature extractor only. We find that data re-sampling is of critical importance to learn a good classifier as it increases the accuracy of the pseudo-labels, in particular for the minority classes in the unlabeled data. Interestingly, we find that accurate pseudo-labels do not help when training the feature extractor, rather contrariwise, data re-sampling harms the training of the feature extractor. This finding is against the general intuition that wrong pseudo-labels always harm the model performance in SSL. Based on these findings, we suggest to re-think the current paradigm of having a single data re-sampling strategy and develop a simple yet highly effective Bi-Sampling (BiS) strategy for SSL on class-imbalanced data. BiS implements two different re-sampling strategies for training the feature extractor and the classifier and integrates this decoupled training into an end-to-end framework... Code will be released at https://github.com/TACJu/Bi-Sampling.
I2C2W: Image-to-Character-to-Word Transformers for Accurate Scene Text Recognition
May 18, 2021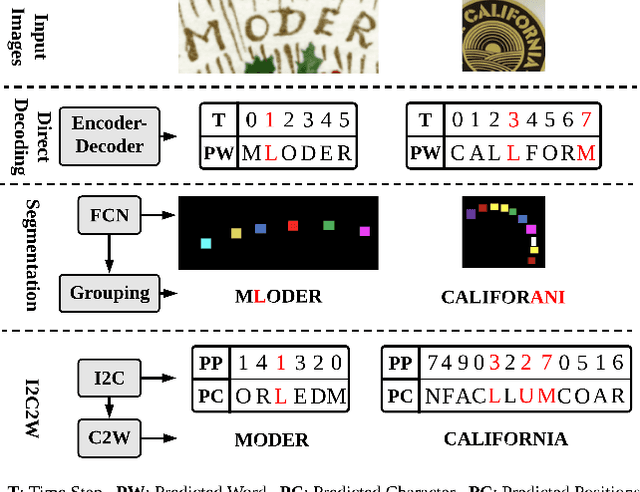
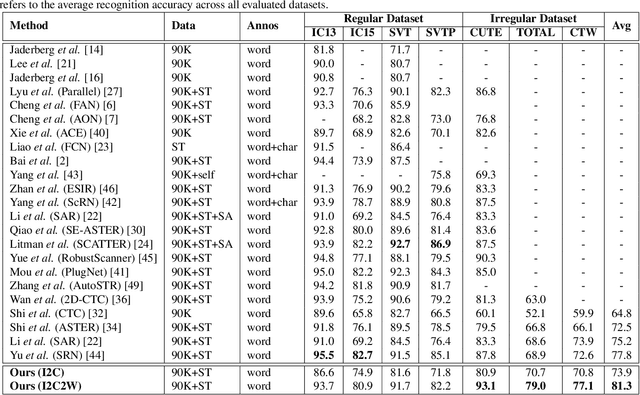
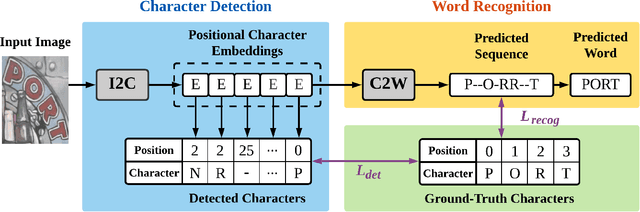
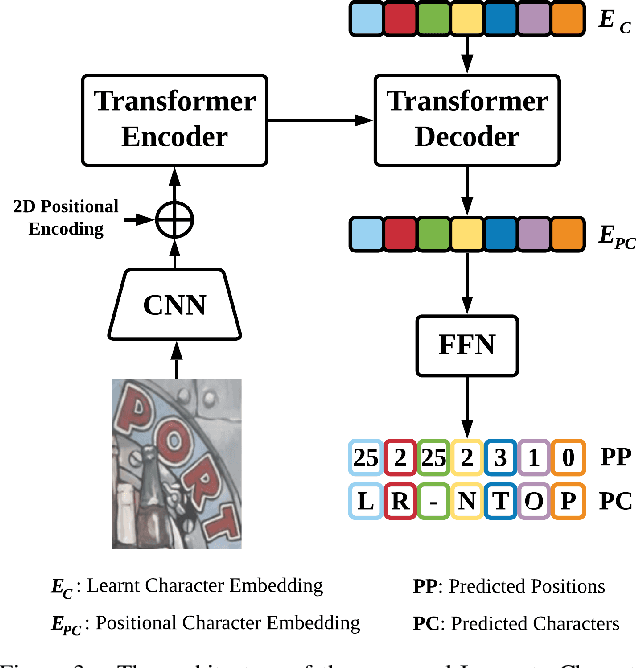
Leveraging the advances of natural language processing, most recent scene text recognizers adopt an encoder-decoder architecture where text images are first converted to representative features and then a sequence of characters via `direct decoding'. However, scene text images suffer from rich noises of different sources such as complex background and geometric distortions which often confuse the decoder and lead to incorrect alignment of visual features at noisy decoding time steps. This paper presents I2C2W, a novel scene text recognizer that is accurate and tolerant to various noises in scenes. I2C2W consists of an image-to-character module (I2C) and a character-to-word module (C2W) which are complementary and can be trained end-to-end. I2C detects characters and predicts their relative positions in a word. It strives to detect all possible characters including incorrect and redundant ones based on different alignments of visual features without the restriction of time steps. Taking the detected characters as input, C2W learns from character semantics and their positions to filter out incorrect and redundant detection and produce the final word recognition. Extensive experiments over seven public datasets show that I2C2W achieves superior recognition performances and outperforms the state-of-the-art by large margins on challenging irregular scene text datasets.