 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Oct 16, 2025Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and unreliable. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking accuracy, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a general foundation for vision-language-action humanoid systems.
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025


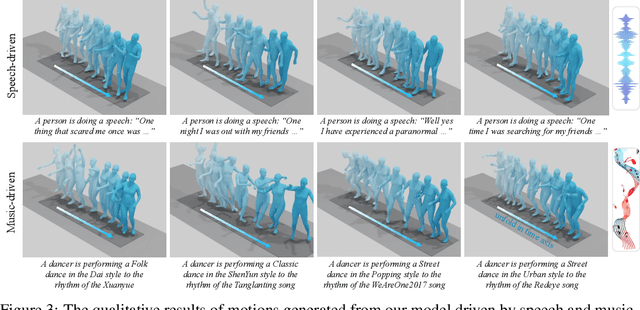
Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
Action-aware Dynamic Pruning for Efficient Vision-Language-Action Manipulation
Sep 26, 2025Robotic manipulation with Vision-Language-Action models requires efficient inference over long-horizon multi-modal context, where attention to dense visual tokens dominates computational cost. Existing methods optimize inference speed by reducing visual redundancy within VLA models, but they overlook the varying redundancy across robotic manipulation stages. We observe that the visual token redundancy is higher in coarse manipulation phase than in fine-grained operations, and is strongly correlated with the action dynamic. Motivated by this observation, we propose \textbf{A}ction-aware \textbf{D}ynamic \textbf{P}runing (\textbf{ADP}), a multi-modal pruning framework that integrates text-driven token selection with action-aware trajectory gating. Our method introduces a gating mechanism that conditions the pruning signal on recent action trajectories, using past motion windows to adaptively adjust token retention ratios in accordance with dynamics, thereby balancing computational efficiency and perceptual precision across different manipulation stages. Extensive experiments on the LIBERO suites and diverse real-world scenarios demonstrate that our method significantly reduces FLOPs and action inference latency (\textit{e.g.} $1.35 \times$ speed up on OpenVLA-OFT) while maintaining competitive success rates (\textit{e.g.} 25.8\% improvements with OpenVLA) compared to baselines, thereby providing a simple plug-in path to efficient robot policies that advances the efficiency and performance frontier of robotic manipulation. Our project website is: \href{https://vla-adp.github.io/}{ADP.com}.
DeCoP: Enhancing Self-Supervised Time Series Representation with Dependency Controlled Pre-training
Sep 18, 2025Modeling dynamic temporal dependencies is a critical challenge in time series pre-training, which evolve due to distribution shifts and multi-scale patterns. This temporal variability severely impairs the generalization of pre-trained models to downstream tasks. Existing frameworks fail to capture the complex interactions of short- and long-term dependencies, making them susceptible to spurious correlations that degrade generalization. To address these limitations, we propose DeCoP, a Dependency Controlled Pre-training framework that explicitly models dynamic, multi-scale dependencies by simulating evolving inter-patch dependencies. At the input level, DeCoP introduces Instance-wise Patch Normalization (IPN) to mitigate distributional shifts while preserving the unique characteristics of each patch, creating a robust foundation for representation learning. At the latent level, a hierarchical Dependency Controlled Learning (DCL) strategy explicitly models inter-patch dependencies across multiple temporal scales, with an Instance-level Contrastive Module (ICM) enhances global generalization by learning instance-discriminative representations from time-invariant positive pairs. DeCoP achieves state-of-the-art results on ten datasets with lower computing resources, improving MSE by 3% on ETTh1 over PatchTST using only 37% of the FLOPs.
SMARTIES: Spectrum-Aware Multi-Sensor Auto-Encoder for Remote Sensing Images
Jun 24, 2025From optical sensors to microwave radars, leveraging the complementary strengths of remote sensing (RS) sensors is crucial for achieving dense spatio-temporal monitoring of our planet. In contrast, recent deep learning models, whether task-specific or foundational, are often specific to single sensors or to fixed combinations: adapting such models to different sensory inputs requires both architectural changes and re-training, limiting scalability and generalization across multiple RS sensors. On the contrary, a single model able to modulate its feature representations to accept diverse sensors as input would pave the way to agile and flexible multi-sensor RS data processing. To address this, we introduce SMARTIES, a generic and versatile foundation model lifting sensor-specific/dependent efforts and enabling scalability and generalization to diverse RS sensors: SMARTIES projects data from heterogeneous sensors into a shared spectrum-aware space, enabling the use of arbitrary combinations of bands both for training and inference. To obtain sensor-agnostic representations, we train a single, unified transformer model reconstructing masked multi-sensor data with cross-sensor token mixup. On both single- and multi-modal tasks across diverse sensors, SMARTIES outperforms previous models that rely on sensor-specific pretraining. Our code and pretrained models are available at https://gsumbul.github.io/SMARTIES.
ConCM: Consistency-Driven Calibration and Matching for Few-Shot Class-Incremental Learning
Jun 24, 2025Few-Shot Class-Incremental Learning (FSCIL) requires models to adapt to novel classes with limited supervision while preserving learned knowledge. Existing prospective learning-based space construction methods reserve space to accommodate novel classes. However, prototype deviation and structure fixity limit the expressiveness of the embedding space. In contrast to fixed space reservation, we explore the optimization of feature-structure dual consistency and propose a Consistency-driven Calibration and Matching Framework (ConCM) that systematically mitigate the knowledge conflict inherent in FSCIL. Specifically, inspired by hippocampal associative memory, we design a memory-aware prototype calibration that extracts generalized semantic attributes from base classes and reintegrates them into novel classes to enhance the conceptual center consistency of features. Further, we propose dynamic structure matching, which adaptively aligns the calibrated features to a session-specific optimal manifold space, ensuring cross-session structure consistency. Theoretical analysis shows that our method satisfies both geometric optimality and maximum matching, thereby overcoming the need for class-number priors. On large-scale FSCIL benchmarks including mini-ImageNet and CUB200, ConCM achieves state-of-the-art performance, surpassing current optimal method by 3.20% and 3.68% in harmonic accuracy of incremental sessions.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
Jun 09, 2025



A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
GridRoute: A Benchmark for LLM-Based Route Planning with Cardinal Movement in Grid Environments
May 30, 2025



Recent advancements in Large Language Models (LLMs) have demonstrated their potential in planning and reasoning tasks, offering a flexible alternative to classical pathfinding algorithms. However, most existing studies focus on LLMs' independent reasoning capabilities and overlook the potential synergy between LLMs and traditional algorithms. To fill this gap, we propose a comprehensive evaluation benchmark GridRoute to assess how LLMs can take advantage of traditional algorithms. We also propose a novel hybrid prompting technique called Algorithm of Thought (AoT), which introduces traditional algorithms' guidance into prompting. Our benchmark evaluates six LLMs ranging from 7B to 72B parameters across various map sizes, assessing their performance in correctness, optimality, and efficiency in grid environments with varying sizes. Our results show that AoT significantly boosts performance across all model sizes, particularly in larger or more complex environments, suggesting a promising approach to addressing path planning challenges. Our code is open-sourced at https://github.com/LinChance/GridRoute.
Revisiting Uncertainty Estimation and Calibration of Large Language Models
May 29, 2025As large language models (LLMs) are increasingly deployed in high-stakes applications, robust uncertainty estimation is essential for ensuring the safe and trustworthy deployment of LLMs. We present the most comprehensive study to date of uncertainty estimation in LLMs, evaluating 80 models spanning open- and closed-source families, dense and Mixture-of-Experts (MoE) architectures, reasoning and non-reasoning modes, quantization variants and parameter scales from 0.6B to 671B. Focusing on three representative black-box single-pass methods, including token probability-based uncertainty (TPU), numerical verbal uncertainty (NVU), and linguistic verbal uncertainty (LVU), we systematically evaluate uncertainty calibration and selective classification using the challenging MMLU-Pro benchmark, which covers both reasoning-intensive and knowledge-based tasks. Our results show that LVU consistently outperforms TPU and NVU, offering stronger calibration and discrimination while being more interpretable. We also find that high accuracy does not imply reliable uncertainty, and that model scale, post-training, reasoning ability and quantization all influence estimation performance. Notably, LLMs exhibit better uncertainty estimates on reasoning tasks than on knowledge-heavy ones, and good calibration does not necessarily translate to effective error ranking. These findings highlight the need for multi-perspective evaluation and position LVU as a practical tool for improving the reliability of LLMs in real-world settings.
Rethinking Causal Mask Attention for Vision-Language Inference
May 24, 2025Causal attention has become a foundational mechanism in autoregressive vision-language models (VLMs), unifying textual and visual inputs under a single generative framework. However, existing causal mask-based strategies are inherited from large language models (LLMs) where they are tailored for text-only decoding, and their adaptation to vision tokens is insufficiently addressed in the prefill stage. Strictly masking future positions for vision queries introduces overly rigid constraints, which hinder the model's ability to leverage future context that often contains essential semantic cues for accurate inference. In this work, we empirically investigate how different causal masking strategies affect vision-language inference and then propose a family of future-aware attentions tailored for this setting. We first empirically analyze the effect of previewing future tokens for vision queries and demonstrate that rigid masking undermines the model's capacity to capture useful contextual semantic representations. Based on these findings, we propose a lightweight attention family that aggregates future visual context into past representations via pooling, effectively preserving the autoregressive structure while enhancing cross-token dependencies. We evaluate a range of causal masks across diverse vision-language inference settings and show that selectively compressing future semantic context into past representations benefits the inference.